 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaS: Accelerating RAG through Homology-Aware Speculative Retrieval
Apr 22, 2026Retrieval-Augmented Generation (RAG) expands the knowledge boundary of large language models (LLMs) at inference by retrieving external documents as context. However, retrieval becomes increasingly time-consuming as the knowledge databases grow in size. Existing acceleration strategies either compromise accuracy through approximate retrieval, or achieve marginal gains by reusing results of strictly identical queries. We propose HaS, a homology-aware speculative retrieval framework that performs low-latency speculative retrieval over restricted scopes to obtain candidate documents, followed by validating whether they contain the required knowledge. The validation, grounded in the homology relation between queries, is formulated as a homologous query re-identification task: once a previously observed query is identified as a homologous re-encounter of the incoming query, the draft is deemed acceptable, allowing the system to bypass slow full-database retrieval. Benefiting from the prevalence of homologous queries under real-world popularity patterns, HaS achieves substantial efficiency gains. Extensive experiments demonstrate that HaS reduces retrieval latency by 23.74% and 36.99% across datasets with only a 1-2% marginal accuracy drop. As a plug-and-play solution, HaS also significantly accelerates complex multi-hop queries in modern agentic RAG pipelines. Source code is available at: https://github.com/ErrEqualsNil/HaS.
Unified Enhancement of the Generalization and Robustness of Language Models via Bi-Stage Optimization
Mar 19, 2025



Neural network language models (LMs) are confronted with significant challenges in generalization and robustness. Currently, many studies focus on improving either generalization or robustness in isolation, without methods addressing both aspects simultaneously, which presents a significant challenge in developing LMs that are both robust and generalized. In this paper, we propose a bi-stage optimization framework to uniformly enhance both the generalization and robustness of LMs, termed UEGR. Specifically, during the forward propagation stage, we enrich the output probability distributions of adversarial samples by adaptive dropout to generate diverse sub models, and incorporate JS divergence and adversarial losses of these output distributions to reinforce output stability. During backward propagation stage, we compute parameter saliency scores and selectively update only the most critical parameters to minimize unnecessary deviations and consolidate the model's resilience. Theoretical analysis shows that our framework includes gradient regularization to limit the model's sensitivity to input perturbations and selective parameter updates to flatten the loss landscape, thus improving both generalization and robustness. The experimental results show that our method significantly improves the generalization and robustness of LMs compared to other existing methods across 13 publicly available language datasets, achieving state-of-the-art (SOTA) performance.
AIPerf: Automated machine learning as an AI-HPC benchmark
Aug 26, 2020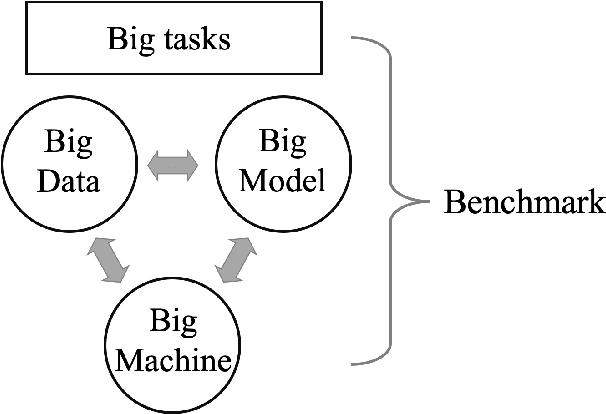
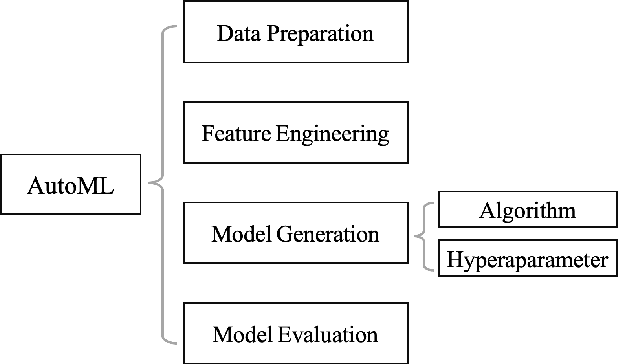

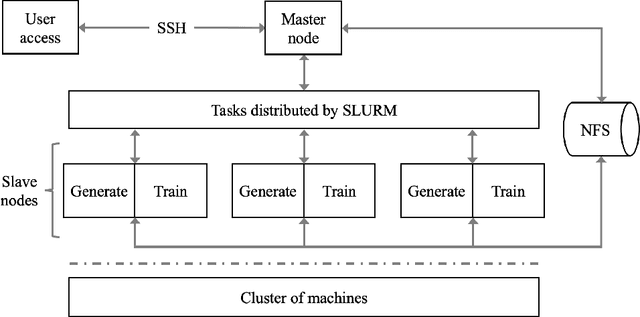
The plethora of complex artificial intelligence (AI) algorithms and available high performance computing (HPC) power stimulates the convergence of AI and HPC. The expeditious development of AI components, in both hardware and software domain, increases the system heterogeneity, which prompts the challenge on fair and comprehensive benchmarking. Existing HPC and AI benchmarks fail to cover the variety of heterogeneous systems while providing a simple quantitative measurement to reflect the overall performance of large clusters for AI tasks. To address the challenges, we specify the requirements of an AI-HPC considering the future scenarios and propose an end-to-end benchmark suite utilizing automated machine learning (AutoML) as a representative AI application. The extremely high computational cost and high scalability make AutoML a desired workload candidate for AI-HPC benchmark. We implement the algorithms in a highly efficient and parallel way to ensure automatic adaption on various systems regarding AI accelerator's memory and quantity. The benchmark is particularly customizable on back-end training framework and hyperparameters so as to achieve optimal performance on diverse systems. The major metric to quantify the machine performance is floating-point operations per second (FLOPS), which is measured in a systematic and analytical approach. We also provide a regulated score as a complementary result to reflect hardware and software co-performance. We verify the benchmark's linear scalability on different scales of nodes up to 16 equipped with 128 GPUs and evaluate the stability as well as reproducibility at discrete timestamps. The source code, specifications, and detailed procedures are publicly accessible on GitHub: https://github.com/AI-HPC-Research-Team/AIPerf.