 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-aware News Recommendation
Feb 28, 2022
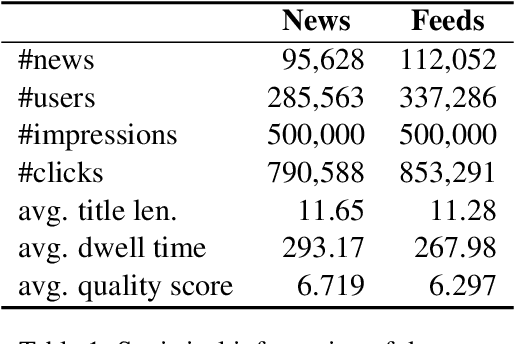
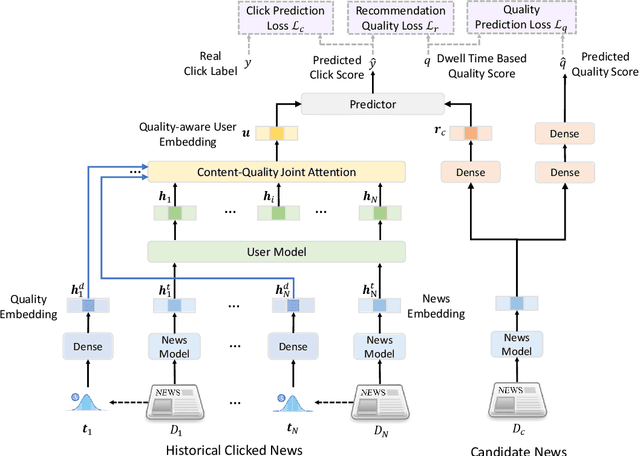
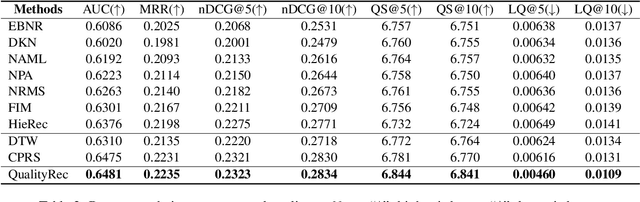
News recommendation is a core technique used by many online news platforms. Recommending high-quality news to users is important for keeping good user experiences and news platforms' reputations. However, existing news recommendation methods mainly aim to optimize news clicks while ignoring the quality of news they recommended, which may lead to recommending news with uninformative content or even clickbaits. In this paper, we propose a quality-aware news recommendation method named QualityRec that can effectively improve the quality of recommended news. In our approach, we first propose an effective news quality evaluation method based on the distributions of users' reading dwell time on news. Next, we propose to incorporate news quality information into user interest modeling by designing a content-quality attention network to select clicked news based on both news semantics and qualities. We further train the recommendation model with an auxiliary news quality prediction task to learn quality-aware recommendation model, and we add a recommendation quality regularization loss to encourage the model to recommend higher-quality news. Extensive experiments on two real-world datasets show that QualityRec can effectively improve the overall quality of recommended news and reduce the recommendation of low-quality news, with even slightly better recommendation accuracy.
Game of Privacy: Towards Better Federated Platform Collaboration under Privacy Restriction
Feb 24, 2022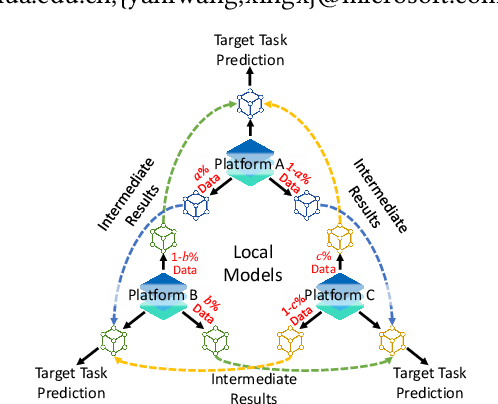
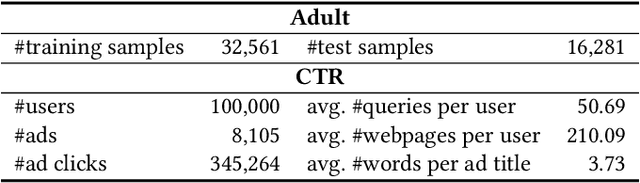
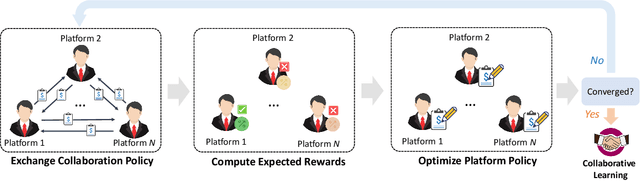
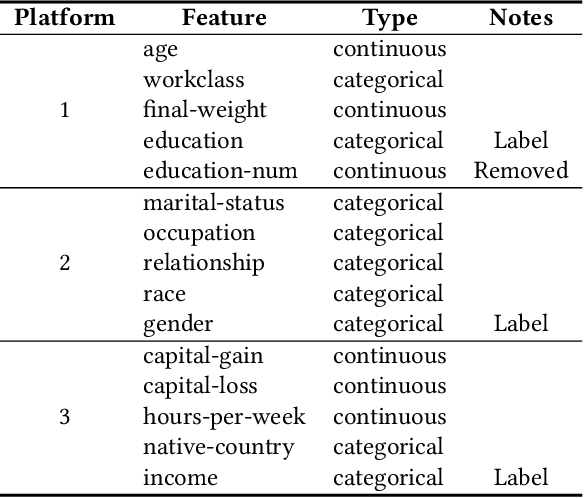
Vertical federated learning (VFL) aims to train models from cross-silo data with different feature spaces stored on different platforms. Existing VFL methods usually assume all data on each platform can be used for model training. However, due to the intrinsic privacy risks of federated learning, the total amount of involved data may be constrained. In addition, existing VFL studies usually assume only one platform has task labels and can benefit from the collaboration, making it difficult to attract other platforms to join in the collaborative learning. In this paper, we study the platform collaboration problem in VFL under privacy constraint. We propose to incent different platforms through a reciprocal collaboration, where all platforms can exploit multi-platform information in the VFL framework to benefit their own tasks. With limited privacy budgets, each platform needs to wisely allocate its data quotas for collaboration with other platforms. Thereby, they naturally form a multi-party game. There are two core problems in this game, i.e., how to appraise other platforms' data value to compute game rewards and how to optimize policies to solve the game. To evaluate the contributions of other platforms' data, each platform offers a small amount of "deposit" data to participate in the VFL. We propose a performance estimation method to predict the expected model performance when involving different amount combinations of inter-platform data. To solve the game, we propose a platform negotiation method that simulates the bargaining among platforms and locally optimizes their policies via gradient descent. Extensive experiments on two real-world datasets show that our approach can effectively facilitate the collaborative exploitation of multi-platform data in VFL under privacy restrictions.
FedAttack: Effective and Covert Poisoning Attack on Federated Recommendation via Hard Sampling
Feb 10, 2022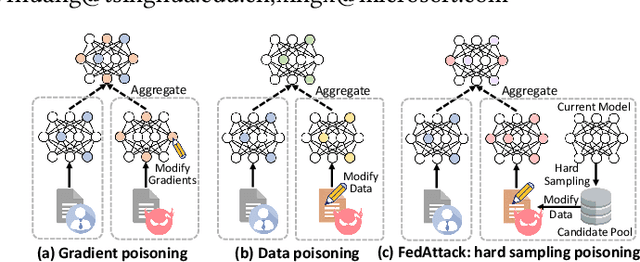

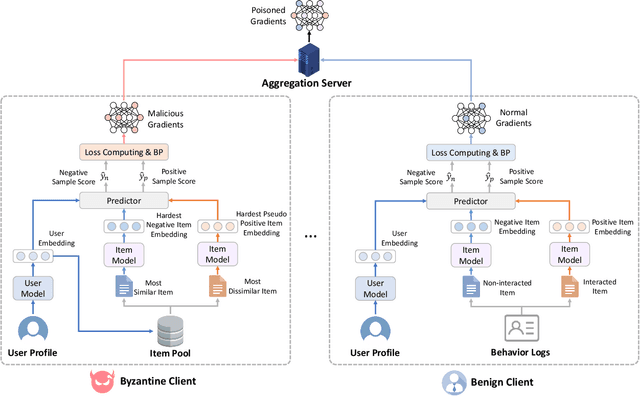
Federated learning (FL) is a feasible technique to learn personalized recommendation models from decentralized user data. Unfortunately, federated recommender systems are vulnerable to poisoning attacks by malicious clients. Existing recommender system poisoning methods mainly focus on promoting the recommendation chances of target items due to financial incentives. In fact, in real-world scenarios, the attacker may also attempt to degrade the overall performance of recommender systems. However, existing general FL poisoning methods for degrading model performance are either ineffective or not concealed in poisoning federated recommender systems. In this paper, we propose a simple yet effective and covert poisoning attack method on federated recommendation, named FedAttack. Its core idea is using globally hardest samples to subvert model training. More specifically, the malicious clients first infer user embeddings based on local user profiles. Next, they choose the candidate items that are most relevant to the user embeddings as hardest negative samples, and find the candidates farthest from the user embeddings as hardest positive samples. The model gradients inferred from these poisoned samples are then uploaded to the server for aggregation and model update. Since the behaviors of malicious clients are somewhat similar to users with diverse interests, they cannot be effectively distinguished from normal clients by the server. Extensive experiments on two benchmark datasets show that FedAttack can effectively degrade the performance of various federated recommender systems, meanwhile cannot be effectively detected nor defended by many existing methods.
Pixel-Stega: Generative Image Steganography Based on Autoregressive Models
Dec 21, 2021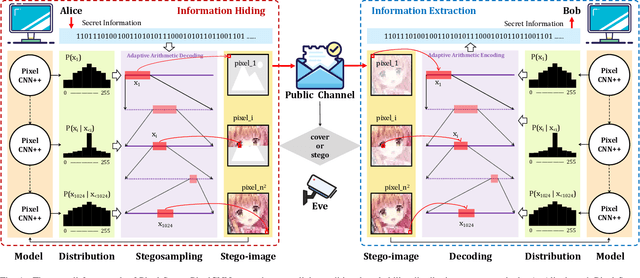

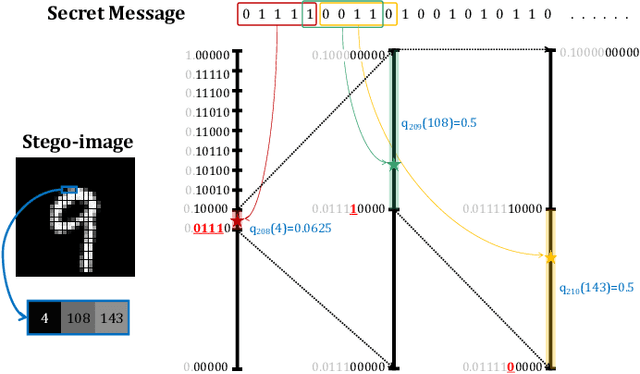

In this letter, we explored generative image steganography based on autoregressive models. We proposed Pixel-Stega, which implements pixel-level information hiding with autoregressive models and arithmetic coding algorithm. Firstly, one of the autoregressive models, PixelCNN++, is utilized to produce explicit conditional probability distribution of each pixel. Secondly, secret messages are encoded to the selection of pixels through steganographic sampling (stegosampling) based on arithmetic coding. We carried out qualitative and quantitative assessment on gray-scale and colour image datasets. Experimental results show that Pixel-Stega is able to embed secret messages adaptively according to the entropy of the pixels to achieve both high embedding capacity (up to 4.3 bpp) and nearly perfect imperceptibility (about 50% detection accuracy).
An unsupervised extractive summarization method based on multi-round computation
Dec 15, 2021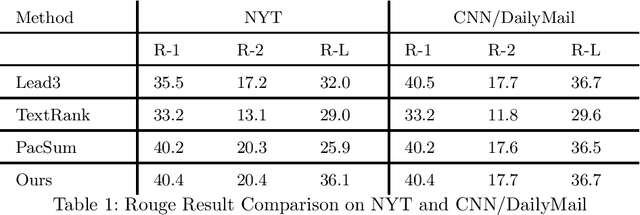
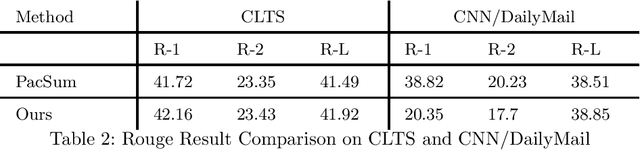
Text summarization methods have attracted much attention all the time. In recent years, deep learning has been applied to text summarization, and it turned out to be pretty effective. However, most of the current text summarization methods based on deep learning need large-scale datasets, which is difficult to achieve in practical applications. In this paper, an unsupervised extractive text summarization method based on multi-round calculation is proposed. Based on the directed graph algorithm, we change the traditional method of calculating the sentence ranking at one time to multi-round calculation, and the summary sentences are dynamically optimized after each round of calculation to better match the characteristics of the text. In this paper, experiments are carried out on four data sets, each separately containing Chinese, English, long and short texts. The experiment results show that our method has better performance than both baseline methods and other unsupervised methods and is robust on different datasets.
Uni-FedRec: A Unified Privacy-Preserving News Recommendation Framework for Model Training and Online Serving
Sep 11, 2021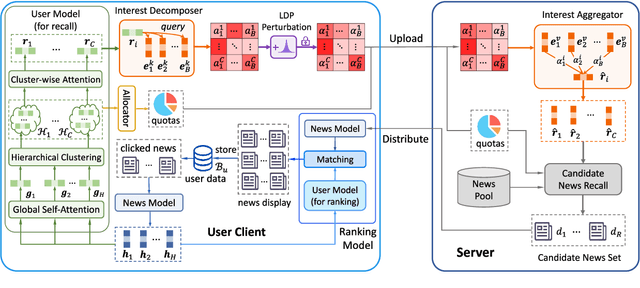
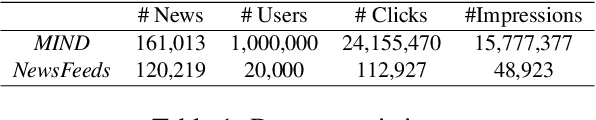
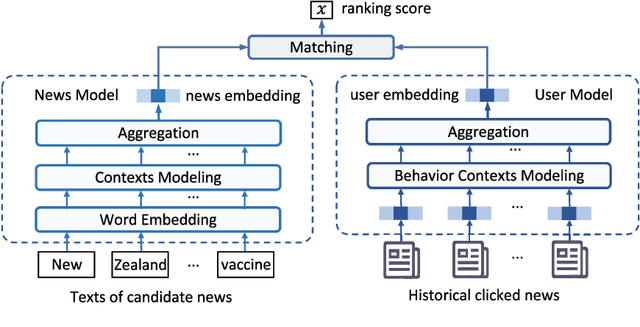
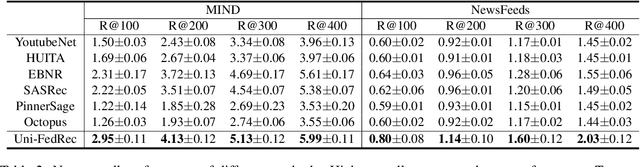
News recommendation is important for personalized online news services. Most existing news recommendation methods rely on centrally stored user behavior data to both train models offline and provide online recommendation services. However, user data is usually highly privacy-sensitive, and centrally storing them may raise privacy concerns and risks. In this paper, we propose a unified news recommendation framework, which can utilize user data locally stored in user clients to train models and serve users in a privacy-preserving way. Following a widely used paradigm in real-world recommender systems, our framework contains two stages. The first one is for candidate news generation (i.e., recall) and the second one is for candidate news ranking (i.e., ranking). At the recall stage, each client locally learns multiple interest representations from clicked news to comprehensively model user interests. These representations are uploaded to the server to recall candidate news from a large news pool, which are further distributed to the user client at the ranking stage for personalized news display. In addition, we propose an interest decomposer-aggregator method with perturbation noise to better protect private user information encoded in user interest representations. Besides, we collaboratively train both recall and ranking models on the data decentralized in a large number of user clients in a privacy-preserving way. Experiments on two real-world news datasets show that our method can outperform baseline methods and effectively protect user privacy.
Fastformer: Additive Attention Can Be All You Need
Sep 05, 2021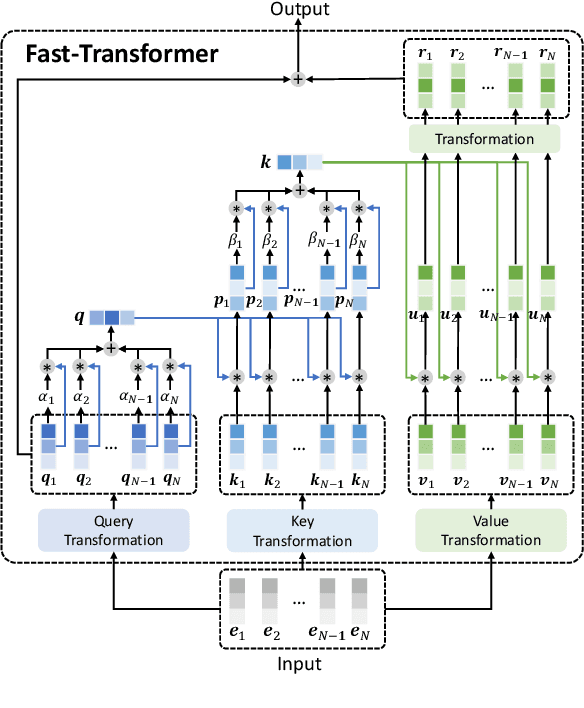


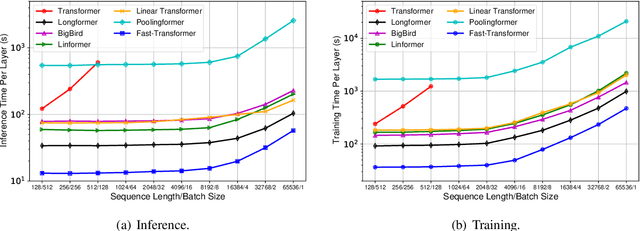
Transformer is a powerful model for text understanding. However, it is inefficient due to its quadratic complexity to input sequence length. Although there are many methods on Transformer acceleration, they are still either inefficient on long sequences or not effective enough. In this paper, we propose Fastformer, which is an efficient Transformer model based on additive attention. In Fastformer, instead of modeling the pair-wise interactions between tokens, we first use additive attention mechanism to model global contexts, and then further transform each token representation based on its interaction with global context representations. In this way, Fastformer can achieve effective context modeling with linear complexity. Extensive experiments on five datasets show that Fastformer is much more efficient than many existing Transformer models and can meanwhile achieve comparable or even better long text modeling performance.
UserBERT: Contrastive User Model Pre-training
Sep 03, 2021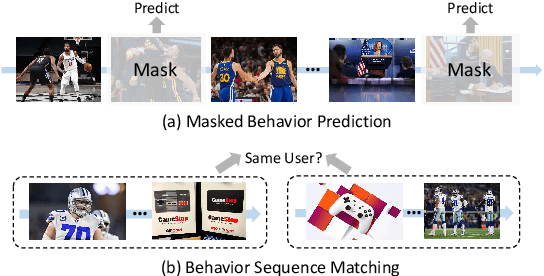
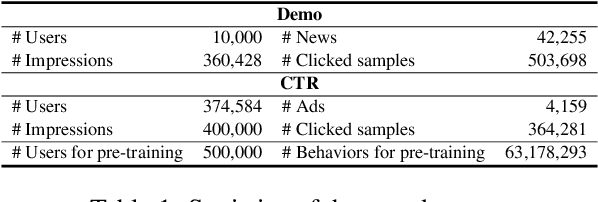
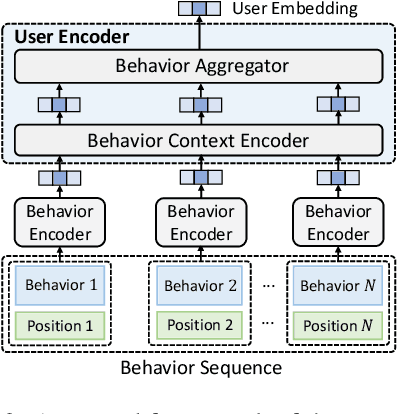
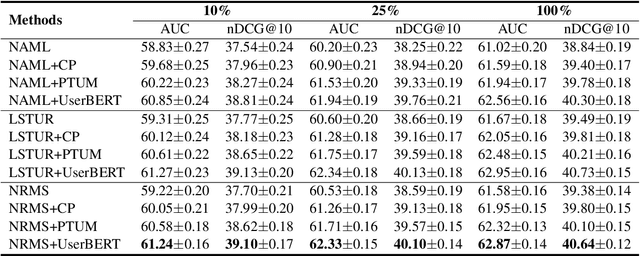
User modeling is critical for personalized web applications. Existing user modeling methods usually train user models from user behaviors with task-specific labeled data. However, labeled data in a target task may be insufficient for training accurate user models. Fortunately, there are usually rich unlabeled user behavior data which encode rich information of user characteristics and interests. Thus, pre-training user models on unlabeled user behavior data has the potential to improve user modeling for many downstream tasks. In this paper, we propose a contrastive user model pre-training method named UserBERT. Two self-supervision tasks are incorporated in UserBERT for user model pre-training on unlabeled user behavior data to empower user modeling. The first one is masked behavior prediction, which aims to model the relatedness between user behaviors. The second one is behavior sequence matching, which aims to capture the inherent user interests that are consistent in different periods. In addition, we propose a medium-hard negative sampling framework to select informative negative samples for better contrastive pre-training. We maintain a synchronously updated candidate behavior pool and an asynchronously updated candidate behavior sequence pool to select the locally hardest negative behaviors and behavior sequences in an efficient way. Extensive experiments on two real-world datasets in different tasks show that UserBERT can effectively improve various user models.
Smart Bird: Learnable Sparse Attention for Efficient and Effective Transformer
Sep 02, 2021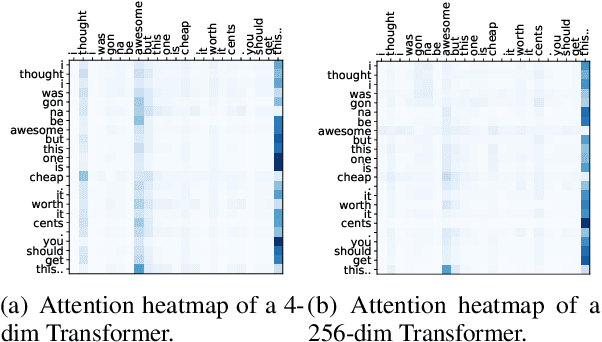
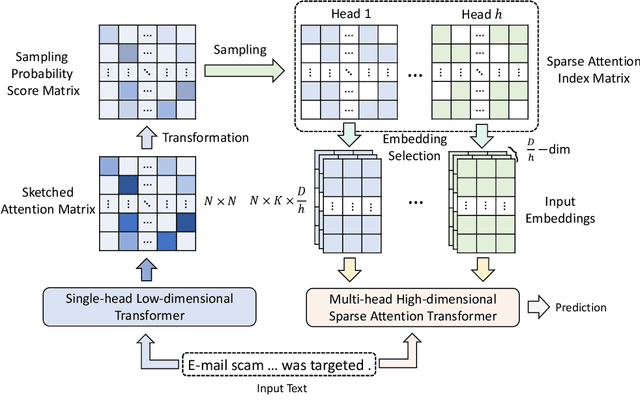

Transformer has achieved great success in NLP. However, the quadratic complexity of the self-attention mechanism in Transformer makes it inefficient in handling long sequences. Many existing works explore to accelerate Transformers by computing sparse self-attention instead of a dense one, which usually attends to tokens at certain positions or randomly selected tokens. However, manually selected or random tokens may be uninformative for context modeling. In this paper, we propose Smart Bird, which is an efficient and effective Transformer with learnable sparse attention. In Smart Bird, we first compute a sketched attention matrix with a single-head low-dimensional Transformer, which aims to find potential important interactions between tokens. We then sample token pairs based on their probability scores derived from the sketched attention matrix to generate different sparse attention index matrices for different attention heads. Finally, we select token embeddings according to the index matrices to form the input of sparse attention networks. Extensive experiments on six benchmark datasets for different tasks validate the efficiency and effectiveness of Smart Bird in text modeling.
FedKD: Communication Efficient Federated Learning via Knowledge Distillation
Aug 30, 2021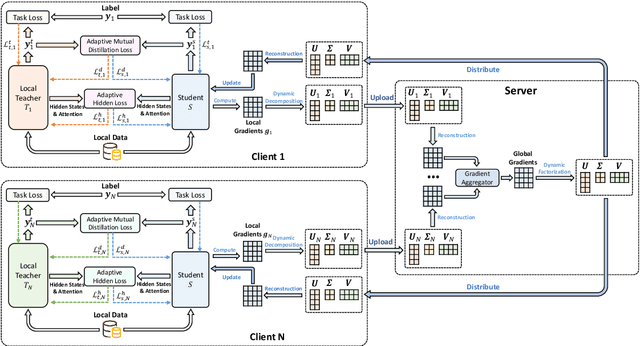
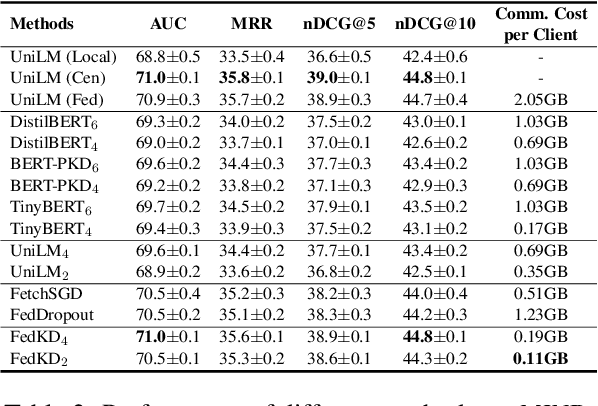
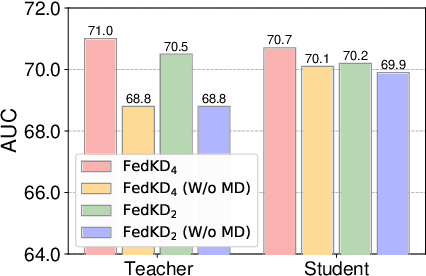
Federated learning is widely used to learn intelligent models from decentralized data. In federated learning, clients need to communicate their local model updates in each iteration of model learning. However, model updates are large in size if the model contains numerous parameters, and there usually needs many rounds of communication until model converges. Thus, the communication cost in federated learning can be quite heavy. In this paper, we propose a communication efficient federated learning method based on knowledge distillation. Instead of directly communicating the large models between clients and server, we propose an adaptive mutual distillation framework to reciprocally learn a student and a teacher model on each client, where only the student model is shared by different clients and updated collaboratively to reduce the communication cost. Both the teacher and student on each client are learned on its local data and the knowledge distilled from each other, where their distillation intensities are controlled by their prediction quality. To further reduce the communication cost, we propose a dynamic gradient approximation method based on singular value decomposition to approximate the exchanged gradients with dynamic precision. Extensive experiments on benchmark datasets in different tasks show that our approach can effectively reduce the communication cost and achieve competitive results.