 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingMess: Linguistically Informed Multi Expert Scorers for Coreference Resolution
May 25, 2022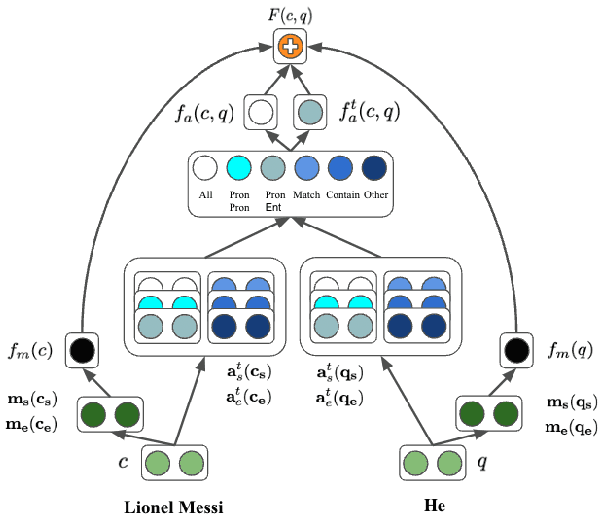
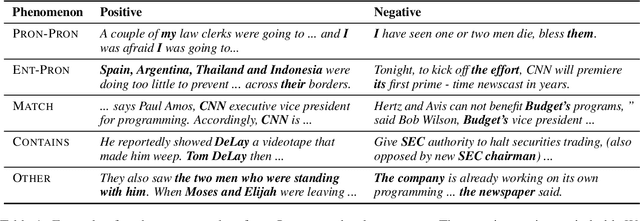

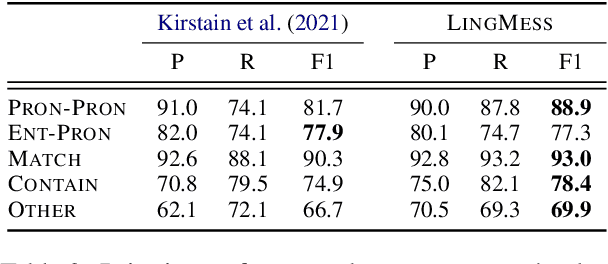
While coreference resolution typically involves various linguistic challenges, recent models are based on a single pairwise scorer for all types of pairs. We present LingMess, a new coreference model that defines different categories of coreference cases and optimize multiple pairwise scorers, where each scorer learns a specific set of linguistic challenges. Our model substantially improves pairwise scores for most categories and outperforms cluster-level performance on Ontonotes. Our model is available in https://github.com/shon-otmazgin/lingmess-coref
A Dataset for N-ary Relation Extraction of Drug Combinations
May 04, 2022

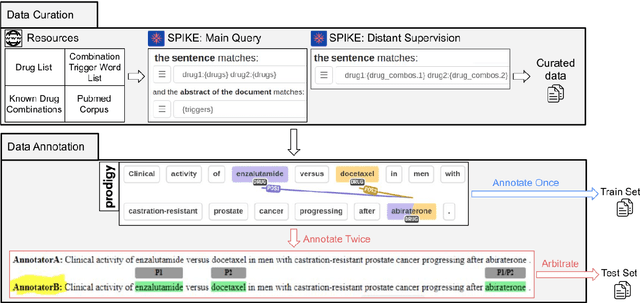
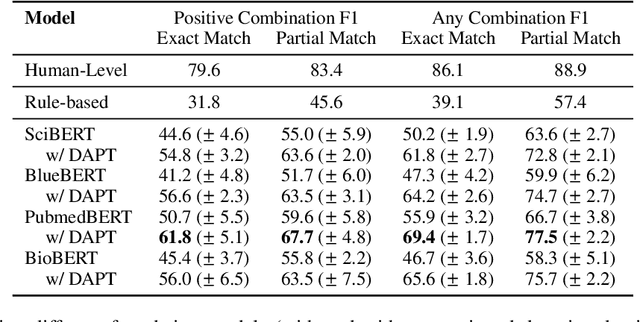
Combination therapies have become the standard of care for diseases such as cancer, tuberculosis, malaria and HIV. However, the combinatorial set of available multi-drug treatments creates a challenge in identifying effective combination therapies available in a situation. To assist medical professionals in identifying beneficial drug-combinations, we construct an expert-annotated dataset for extracting information about the efficacy of drug combinations from the scientific literature. Beyond its practical utility, the dataset also presents a unique NLP challenge, as the first relation extraction dataset consisting of variable-length relations. Furthermore, the relations in this dataset predominantly require language understanding beyond the sentence level, adding to the challenge of this task. We provide a promising baseline model and identify clear areas for further improvement. We release our dataset, code, and baseline models publicly to encourage the NLP community to participate in this task.
LM-Debugger: An Interactive Tool for Inspection and Intervention in Transformer-Based Language Models
Apr 26, 2022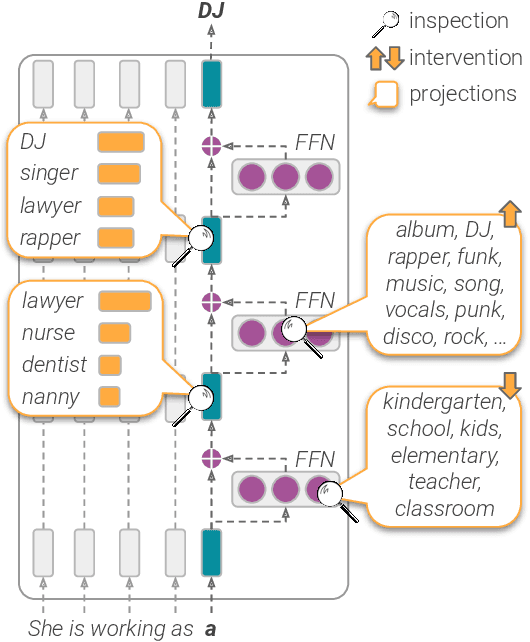

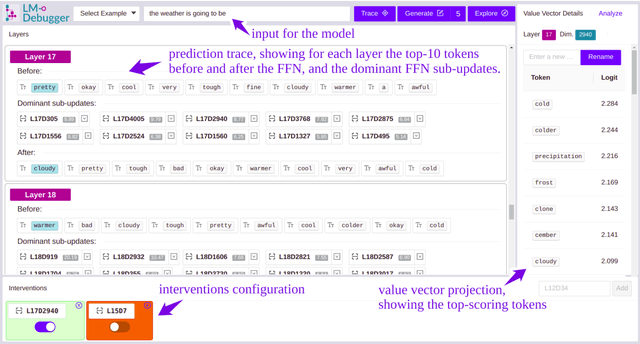

The opaque nature and unexplained behavior of transformer-based language models (LMs) have spurred a wide interest in interpreting their predictions. However, current interpretation methods mostly focus on probing models from outside, executing behavioral tests, and analyzing salience input features, while the internal prediction construction process is largely not understood. In this work, we introduce LM-Debugger, an interactive debugger tool for transformer-based LMs, which provides a fine-grained interpretation of the model's internal prediction process, as well as a powerful framework for intervening in LM behavior. For its backbone, LM-Debugger relies on a recent method that interprets the inner token representations and their updates by the feed-forward layers in the vocabulary space. We demonstrate the utility of LM-Debugger for single-prediction debugging, by inspecting the internal disambiguation process done by GPT2. Moreover, we show how easily LM-Debugger allows to shift model behavior in a direction of the user's choice, by identifying a few vectors in the network and inducing effective interventions to the prediction process. We release LM-Debugger as an open-source tool and a demo over GPT2 models.
Analyzing Gender Representation in Multilingual Models
Apr 20, 2022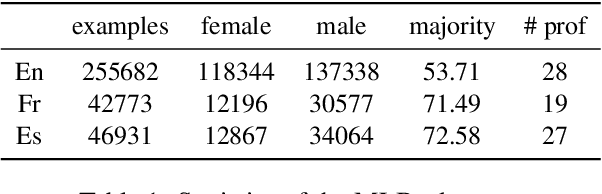
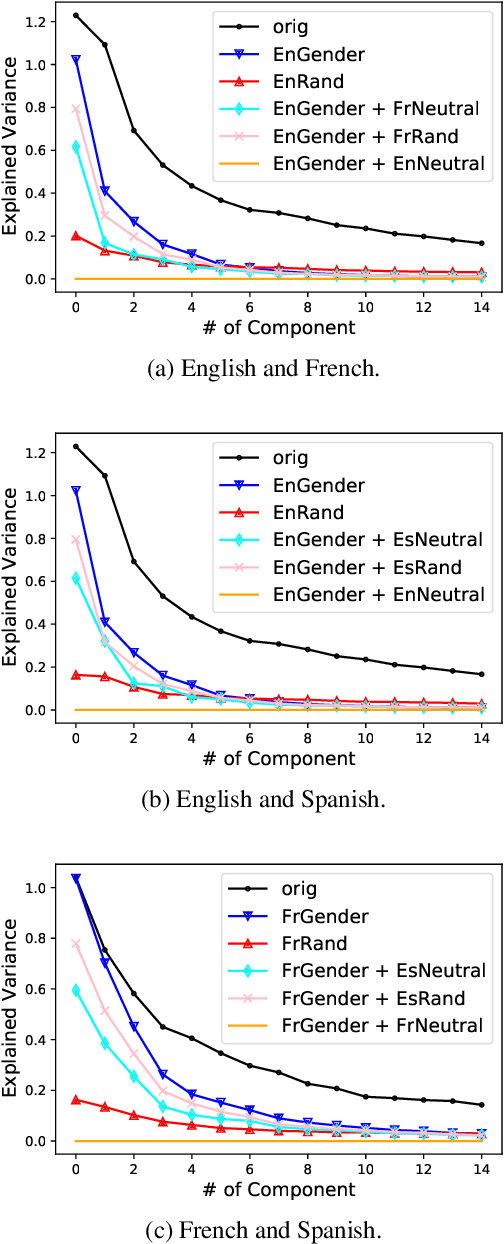
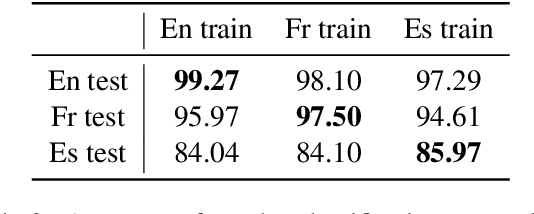
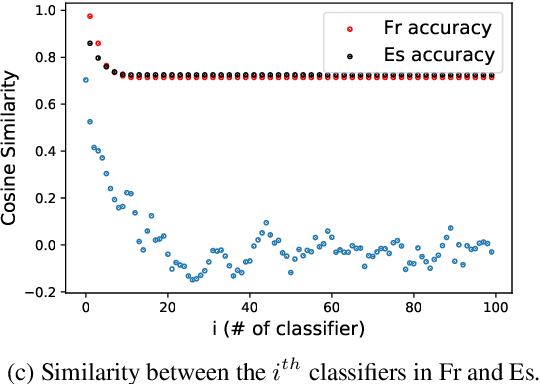
Multilingual language models were shown to allow for nontrivial transfer across scripts and languages. In this work, we study the structure of the internal representations that enable this transfer. We focus on the representation of gender distinctions as a practical case study, and examine the extent to which the gender concept is encoded in shared subspaces across different languages. Our analysis shows that gender representations consist of several prominent components that are shared across languages, alongside language-specific components. The existence of language-independent and language-specific components provides an explanation for an intriguing empirical observation we make: while gender classification transfers well across languages, interventions for gender removal, trained on a single language, do not transfer easily to others.
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space
Mar 28, 2022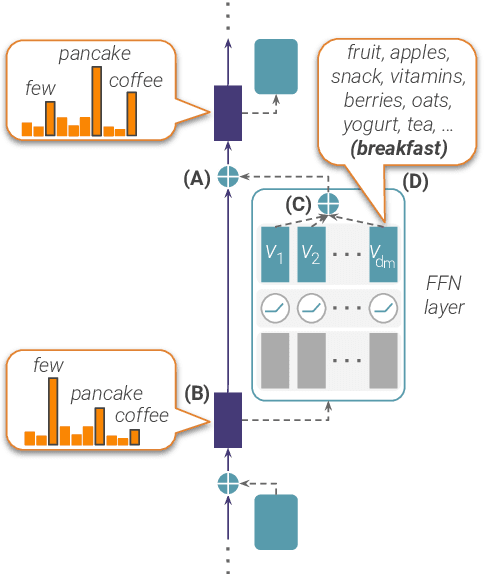

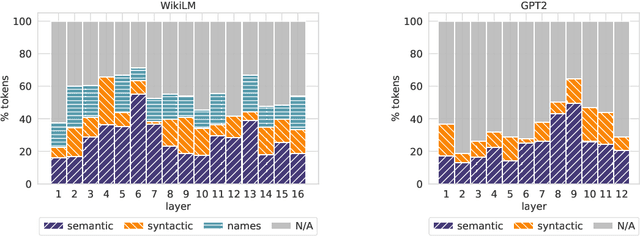

Transformer-based language models (LMs) are at the core of modern NLP, but their internal prediction construction process is opaque and largely not understood. In this work, we make a substantial step towards unveiling this underlying prediction process, by reverse-engineering the operation of the feed-forward network (FFN) layers, one of the building blocks of transformer models. We view the token representation as a changing distribution over the vocabulary, and the output from each FFN layer as an additive update to that distribution. Then, we analyze the FFN updates in the vocabulary space, showing that each update can be decomposed to sub-updates corresponding to single FFN parameter vectors, each promoting concepts that are often human-interpretable. We then leverage these findings for controlling LM predictions, where we reduce the toxicity of GPT2 by almost 50%, and for improving computation efficiency with a simple early exit rule, saving 20% of computation on average.
Adversarial Concept Erasure in Kernel Space
Jan 28, 2022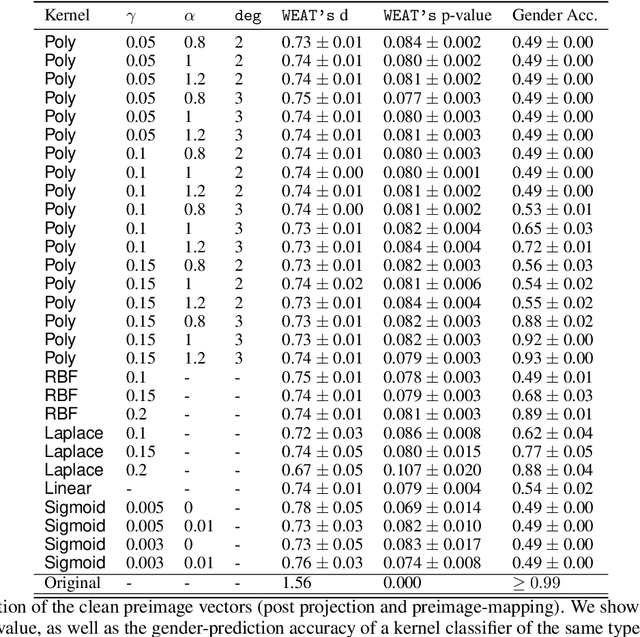
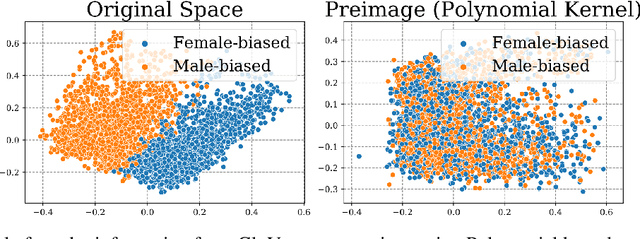

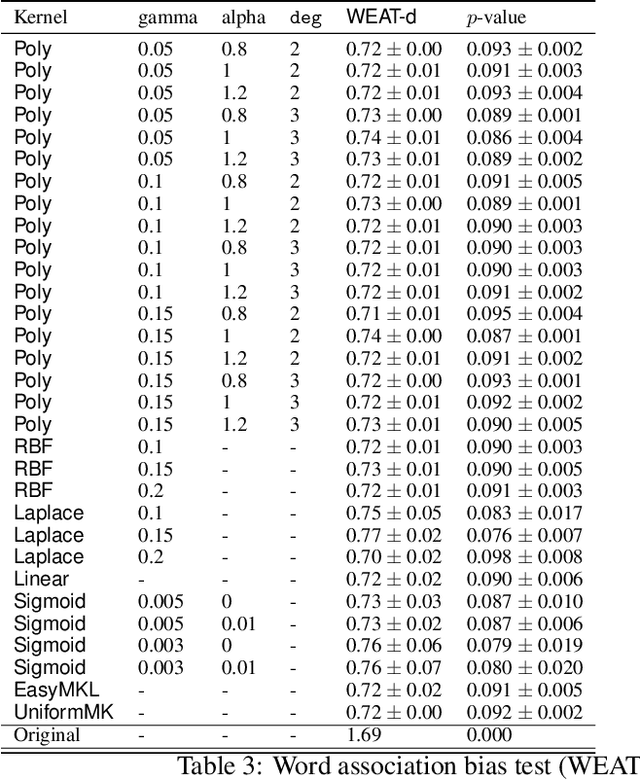
The representation space of neural models for textual data emerges in an unsupervised manner during training. Understanding how human-interpretable concepts, such as gender, are encoded in these representations would improve the ability of users to \emph{control} the content of these representations and analyze the working of the models that rely on them. One prominent approach to the control problem is the identification and removal of linear concept subspaces -- subspaces in the representation space that correspond to a given concept. While those are tractable and interpretable, neural network do not necessarily represent concepts in linear subspaces. We propose a kernalization of the linear concept-removal objective of [Ravfogel et al. 2022], and show that it is effective in guarding against the ability of certain nonlinear adversaries to recover the concept. Interestingly, our findings suggest that the division between linear and nonlinear models is overly simplistic: when considering the concept of binary gender and its neutralization, we do not find a single kernel space that exclusively contains all the concept-related information. It is therefore challenging to protect against \emph{all} nonlinear adversaries at once.
Linear Adversarial Concept Erasure
Jan 28, 2022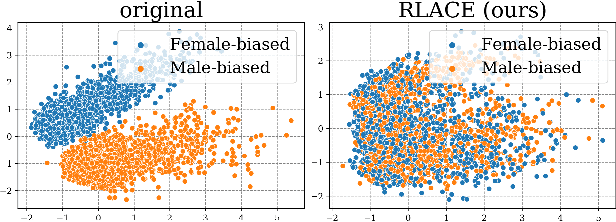
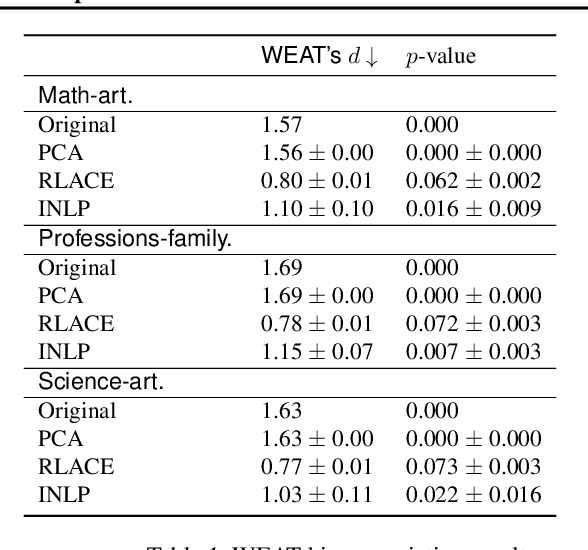
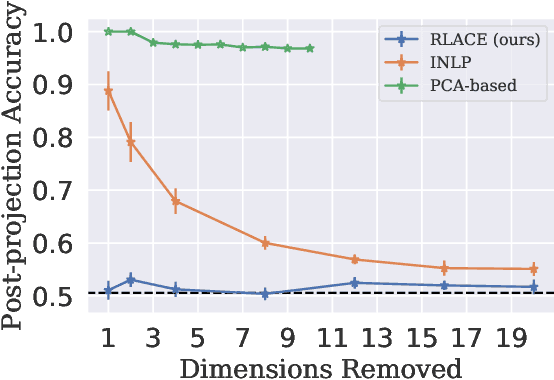
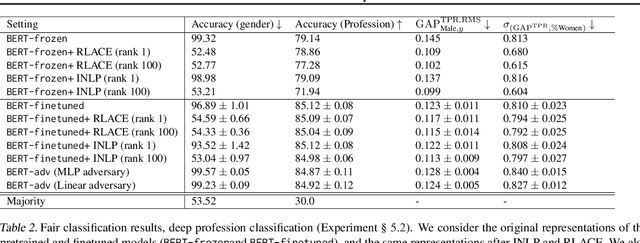
Modern neural models trained on textual data rely on pre-trained representations that emerge without direct supervision. As these representations are increasingly being used in real-world applications, the inability to \emph{control} their content becomes an increasingly important problem. We formulate the problem of identifying and erasing a linear subspace that corresponds to a given concept, in order to prevent linear predictors from recovering the concept. We model this problem as a constrained, linear minimax game, and show that existing solutions are generally not optimal for this task. We derive a closed-form solution for certain objectives, and propose a convex relaxation, R-LACE, that works well for others. When evaluated in the context of binary gender removal, the method recovers a low-dimensional subspace whose removal mitigates bias by intrinsic and extrinsic evaluation. We show that the method -- despite being linear -- is highly expressive, effectively mitigating bias in deep nonlinear classifiers while maintaining tractability and interpretability.
Human Interpretation of Saliency-based Explanation Over Text
Jan 27, 2022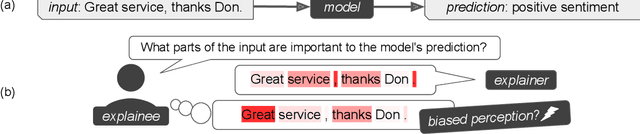

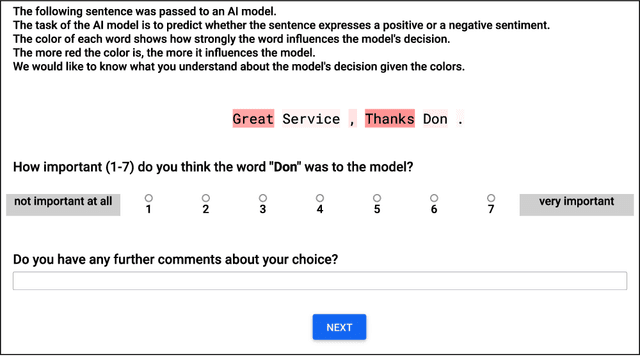
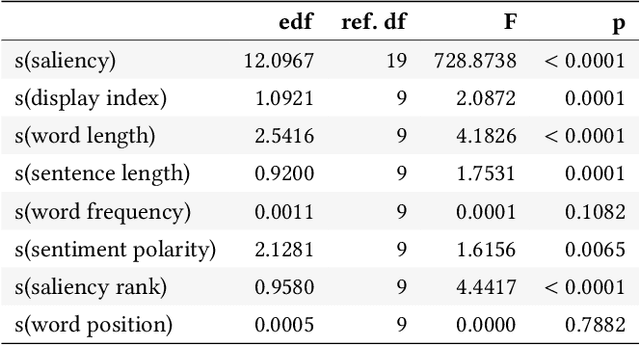
While a lot of research in explainable AI focuses on producing effective explanations, less work is devoted to the question of how people understand and interpret the explanation. In this work, we focus on this question through a study of saliency-based explanations over textual data. Feature-attribution explanations of text models aim to communicate which parts of the input text were more influential than others towards the model decision. Many current explanation methods, such as gradient-based or Shapley value-based methods, provide measures of importance which are well-understood mathematically. But how does a person receiving the explanation (the explainee) comprehend it? And does their understanding match what the explanation attempted to communicate? We empirically investigate the effect of various factors of the input, the feature-attribution explanation, and visualization procedure, on laypeople's interpretation of the explanation. We query crowdworkers for their interpretation on tasks in English and German, and fit a GAMM model to their responses considering the factors of interest. We find that people often mis-interpret the explanations: superficial and unrelated factors, such as word length, influence the explainees' importance assignment despite the explanation communicating importance directly. We then show that some of this distortion can be attenuated: we propose a method to adjust saliencies based on model estimates of over- and under-perception, and explore bar charts as an alternative to heatmap saliency visualization. We find that both approaches can attenuate the distorting effect of specific factors, leading to better-calibrated understanding of the explanation.
Diagnosing AI Explanation Methods with Folk Concepts of Behavior
Jan 27, 2022
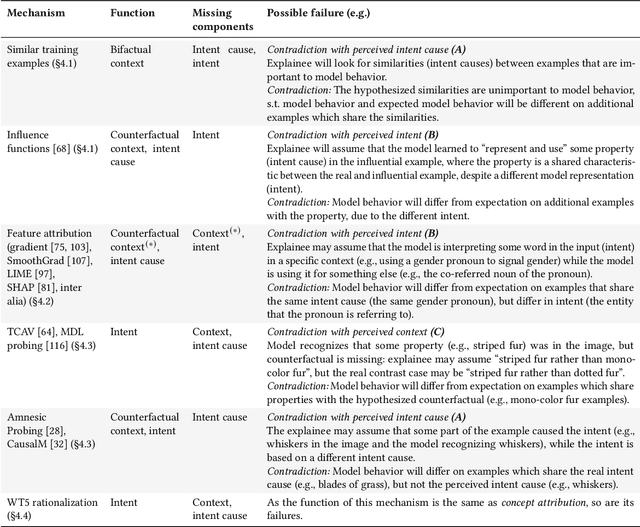
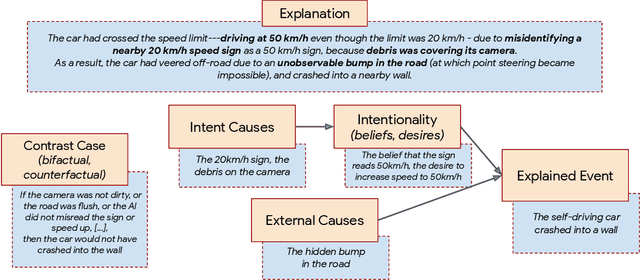

When explaining AI behavior to humans, how is the communicated information being comprehended by the human explainee, and does it match what the explanation attempted to communicate? When can we say that an explanation is explaining something? We aim to provide an answer by leveraging theory of mind literature about the folk concepts that humans use to understand behavior. We establish a framework of social attribution by the human explainee, which describes the function of explanations: the concrete information that humans comprehend from them. Specifically, effective explanations should be coherent (communicate information which generalizes to other contrast cases), complete (communicating an explicit contrast case, objective causes, and subjective causes), and interactive (surfacing and resolving contradictions to the generalization property through iterations). We demonstrate that many XAI mechanisms can be mapped to folk concepts of behavior. This allows us to uncover their modes of failure that prevent current methods from explaining effectively, and what is necessary to enable coherent explanations.
CommonsenseQA 2.0: Exposing the Limits of AI through Gamification
Jan 14, 2022


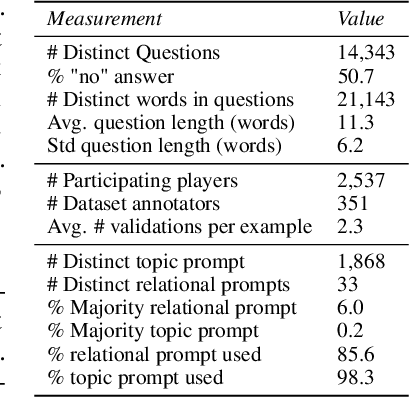
Constructing benchmarks that test the abilities of modern natural language understanding models is difficult - pre-trained language models exploit artifacts in benchmarks to achieve human parity, but still fail on adversarial examples and make errors that demonstrate a lack of common sense. In this work, we propose gamification as a framework for data construction. The goal of players in the game is to compose questions that mislead a rival AI while using specific phrases for extra points. The game environment leads to enhanced user engagement and simultaneously gives the game designer control over the collected data, allowing us to collect high-quality data at scale. Using our method we create CommonsenseQA 2.0, which includes 14,343 yes/no questions, and demonstrate its difficulty for models that are orders-of-magnitude larger than the AI used in the game itself. Our best baseline, the T5-based Unicorn with 11B parameters achieves an accuracy of 70.2%, substantially higher than GPT-3 (52.9%) in a few-shot inference setup. Both score well below human performance which is at 94.1%.