 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Ultra-High-Resolution Remote Sensing MLLMs
Dec 19, 2025Multimodal large language models (MLLMs) demonstrate strong perception and reasoning performance on existing remote sensing (RS) benchmarks. However, most prior benchmarks rely on low-resolution imagery, and some high-resolution benchmarks suffer from flawed reasoning-task designs. We show that text-only LLMs can perform competitively with multimodal vision-language models on RS reasoning tasks without access to images, revealing a critical mismatch between current benchmarks and the intended evaluation of visual understanding. To enable faithful assessment, we introduce RSHR-Bench, a super-high-resolution benchmark for RS visual understanding and reasoning. RSHR-Bench contains 5,329 full-scene images with a long side of at least 4,000 pixels, with up to about 3 x 10^8 pixels per image, sourced from widely used RS corpora and UAV collections. We design four task families: multiple-choice VQA, open-ended VQA, image captioning, and single-image evaluation. These tasks cover nine perception categories and four reasoning types, supporting multi-turn and multi-image dialog. To reduce reliance on language priors, we apply adversarial filtering with strong LLMs followed by rigorous human verification. Overall, we construct 3,864 VQA tasks, 3,913 image captioning tasks, and 500 fully human-written or verified single-image evaluation VQA pairs. Evaluations across open-source, closed-source, and RS-specific VLMs reveal persistent performance gaps in super-high-resolution scenarios. Code: https://github.com/Yunkaidang/RSHR
Can LLM Graph Reasoning Generalize beyond Pattern Memorization?
Jun 23, 2024



Large language models (LLMs) demonstrate great potential for problems with implicit graphical structures, while recent works seek to enhance the graph reasoning capabilities of LLMs through specialized instruction tuning. The resulting 'graph LLMs' are evaluated with in-distribution settings only, thus it remains underexplored whether LLMs are learning generalizable graph reasoning skills or merely memorizing patterns in the synthetic training data. To this end, we propose the NLGift benchmark, an evaluation suite of LLM graph reasoning generalization: whether LLMs could go beyond semantic, numeric, structural, reasoning patterns in the synthetic training data and improve utility on real-world graph-based tasks. Extensive experiments with two LLMs across four graph reasoning tasks demonstrate that while generalization on simple patterns (semantic, numeric) is somewhat satisfactory, LLMs struggle to generalize across reasoning and real-world patterns, casting doubt on the benefit of synthetic graph tuning for real-world tasks with underlying network structures. We explore three strategies to improve LLM graph reasoning generalization, and we find that while post-training alignment is most promising for real-world tasks, empowering LLM graph reasoning to go beyond pattern memorization remains an open research question.
Dynamic Indoor Fingerprinting Localization based on Few-Shot Meta-Learning with CSI Images
Jan 11, 2024While fingerprinting localization is favored for its effectiveness, it is hindered by high data acquisition costs and the inaccuracy of static database-based estimates. Addressing these issues, this letter presents an innovative indoor localization method using a data-efficient meta-learning algorithm. This approach, grounded in the ``Learning to Learn'' paradigm of meta-learning, utilizes historical localization tasks to improve adaptability and learning efficiency in dynamic indoor environments. We introduce a task-weighted loss to enhance knowledge transfer within this framework. Our comprehensive experiments confirm the method's robustness and superiority over current benchmarks, achieving a notable 23.13\% average gain in Mean Euclidean Distance, particularly effective in scenarios with limited CSI data.
Less Is More: Fast Multivariate Time Series Forecasting with Light Sampling-oriented MLP Structures
Jul 04, 2022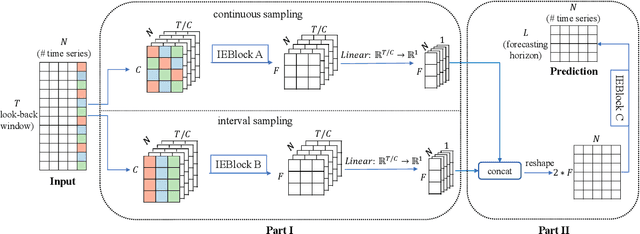
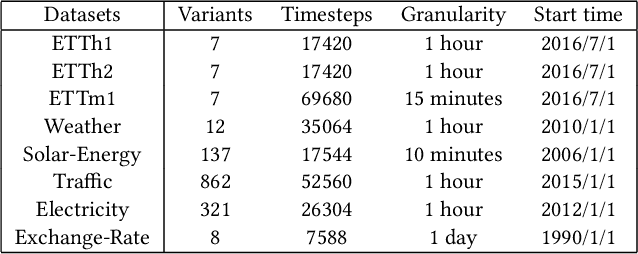
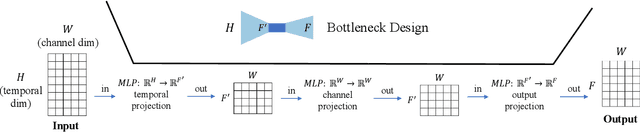
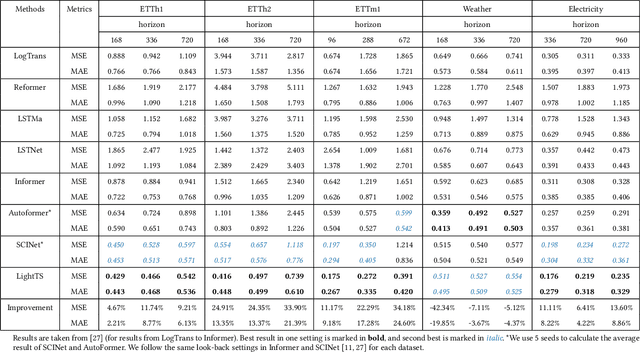
Multivariate time series forecasting has seen widely ranging applications in various domains, including finance, traffic, energy, and healthcare. To capture the sophisticated temporal patterns, plenty of research studies designed complex neural network architectures based on many variants of RNNs, GNNs, and Transformers. However, complex models are often computationally expensive and thus face a severe challenge in training and inference efficiency when applied to large-scale real-world datasets. In this paper, we introduce LightTS, a light deep learning architecture merely based on simple MLP-based structures. The key idea of LightTS is to apply an MLP-based structure on top of two delicate down-sampling strategies, including interval sampling and continuous sampling, inspired by a crucial fact that down-sampling time series often preserves the majority of its information. We conduct extensive experiments on eight widely used benchmark datasets. Compared with the existing state-of-the-art methods, LightTS demonstrates better performance on five of them and comparable performance on the rest. Moreover, LightTS is highly efficient. It uses less than 5% FLOPS compared with previous SOTA methods on the largest benchmark dataset. In addition, LightTS is robust and has a much smaller variance in forecasting accuracy than previous SOTA methods in long sequence forecasting tasks.
A Transductive Approach for Video Object Segmentation
Apr 16, 2020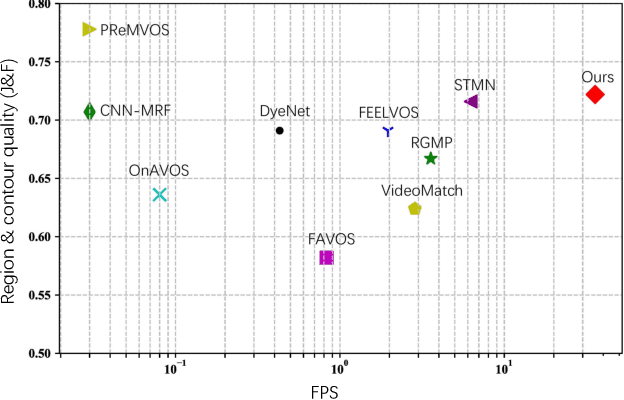

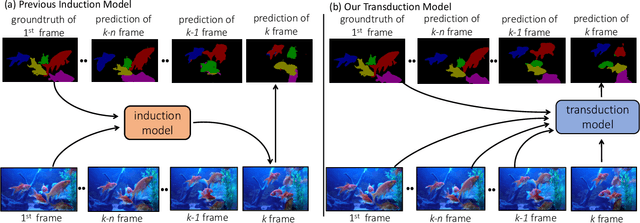
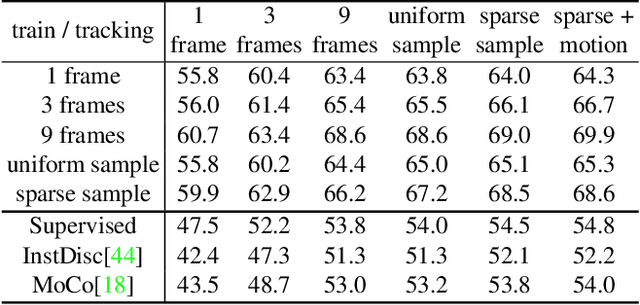
Semi-supervised video object segmentation aims to separate a target object from a video sequence, given the mask in the first frame. Most of current prevailing methods utilize information from additional modules trained in other domains like optical flow and instance segmentation, and as a result they do not compete with other methods on common ground. To address this issue, we propose a simple yet strong transductive method, in which additional modules, datasets, and dedicated architectural designs are not needed. Our method takes a label propagation approach where pixel labels are passed forward based on feature similarity in an embedding space. Different from other propagation methods, ours diffuses temporal information in a holistic manner which take accounts of long-term object appearance. In addition, our method requires few additional computational overhead, and runs at a fast $\sim$37 fps speed. Our single model with a vanilla ResNet50 backbone achieves an overall score of 72.3 on the DAVIS 2017 validation set and 63.1 on the test set. This simple yet high performing and efficient method can serve as a solid baseline that facilitates future research. Code and models are available at \url{https://github.com/microsoft/transductive-vos.pytorch}.