 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOracle-Efficient Reinforcement Learning in Factored MDPs with Unknown Structure
Sep 13, 2020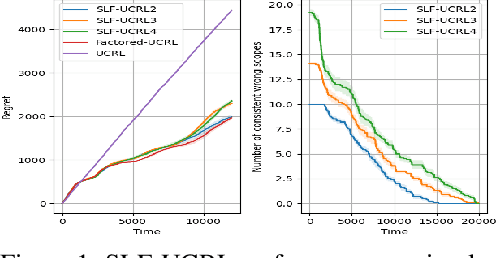
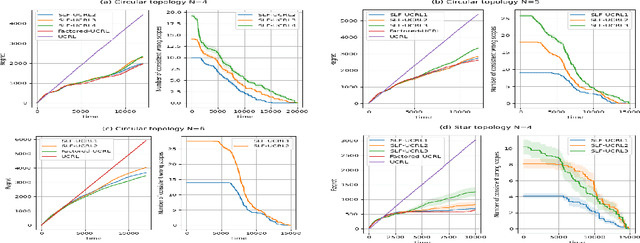
We consider provably-efficient reinforcement learning (RL) in non-episodic factored Markov decision processes (FMDPs). All previous algorithms for regret minimization in this setting made the strong assumption that the factored structure of the FMDP is known to the learner in advance. In this paper, we provide the first provably-efficient algorithm that has to learn the structure of the FMDP while minimizing its regret. Our algorithm is based on the optimism in face of uncertainty principle, combined with a simple statistical method for structure learning, and can be implemented efficiently given oracle-access to an FMDP planner. It maintains its computational efficiency even though the number of possible structures is exponential.
Beyond Individual and Group Fairness
Aug 21, 2020



We present a new data-driven model of fairness that, unlike existing static definitions of individual or group fairness is guided by the unfairness complaints received by the system. Our model supports multiple fairness criteria and takes into account their potential incompatibilities. We consider both a stochastic and an adversarial setting of our model. In the stochastic setting, we show that our framework can be naturally cast as a Markov Decision Process with stochastic losses, for which we give efficient vanishing regret algorithmic solutions. In the adversarial setting, we design efficient algorithms with competitive ratio guarantees. We also report the results of experiments with our algorithms and the stochastic framework on artificial datasets, to demonstrate their effectiveness empirically.
Detecting malicious PDF using CNN
Aug 02, 2020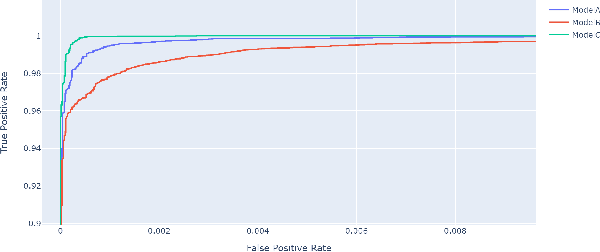
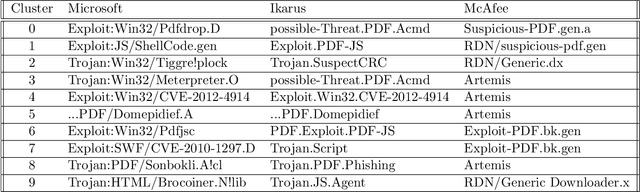
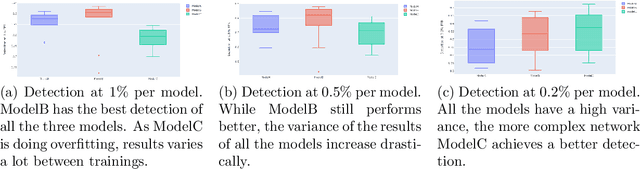
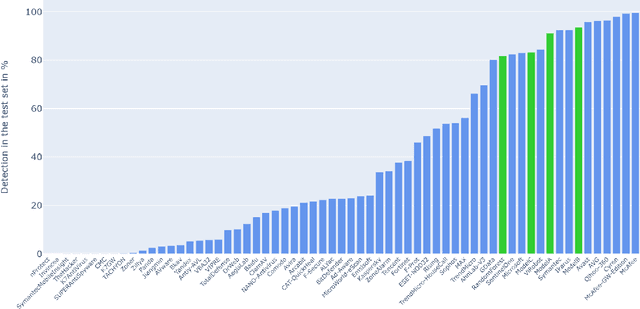
Malicious PDF files represent one of the biggest threats to computer security. To detect them, significant research has been done using handwritten signatures or machine learning based on manual feature extraction. Those approaches are both time-consuming, require significant prior knowledge and the list of features has to be updated with each newly discovered vulnerability. In this work, we propose a novel algorithm that uses an ensemble of Convolutional Neural Network (CNN) on the byte level of the file, without any handcrafted features. We show, using a data set of 90000 files downloadable online, that our approach maintains a high detection rate (94%) of PDF malware and even detects new malicious files, still undetected by most antiviruses. Using automatically generated features from our CNN network, and applying a clustering algorithm, we also obtain high similarity between the antiviruses' labels and the resulting clusters.
Competing Bandits: The Perils of Exploration Under Competition
Jul 20, 2020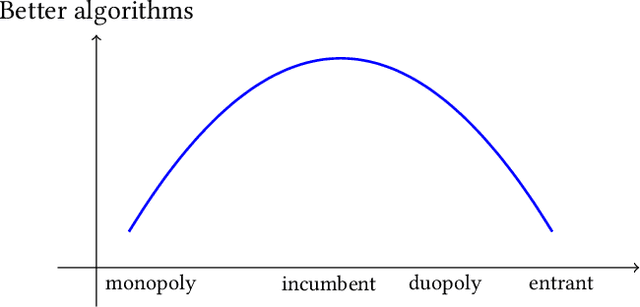
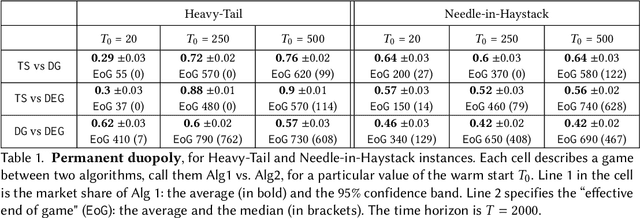
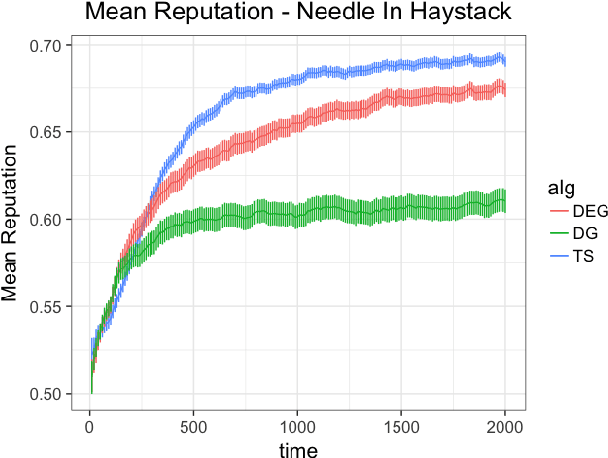
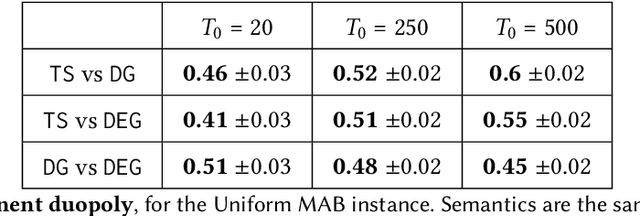
Most online platforms strive to learn from interactions with consumers, and many engage in exploration: making potentially suboptimal choices for the sake of acquiring new information. We initiate a study of the interplay between exploration and competition: how such platforms balance the exploration for learning and the competition for consumers. Here consumers play three distinct roles: they are customers that generate revenue, they are sources of data for learning, and they are self-interested agents which choose among the competing platforms. We consider a stylized duopoly model in which two firms face the same multi-armed bandit instance. Users arrive one by one and choose between the two firms, so that each firm makes progress on its bandit instance only if it is chosen. We study whether and to what extent competition incentivizes the adoption of better bandit algorithms, and whether it leads to welfare increases for consumers. We find that stark competition induces firms to commit to a "greedy" bandit algorithm that leads to low consumer welfare. However, we find that weakening competition by providing firms with some "free" consumers incentivizes better exploration strategies and increases consumer welfare. We investigate two channels for weakening the competition: relaxing the rationality of consumers and giving one firm a first-mover advantage. We provide a mix of theoretical results and numerical simulations. Our findings are closely related to the "competition vs. innovation" relationship, a well-studied theme in economics. They also elucidate the first-mover advantage in the digital economy by exploring the role that data can play as a barrier to entry in online markets.
A Theory of Multiple-Source Adaptation with Limited Target Labeled Data
Jul 19, 2020
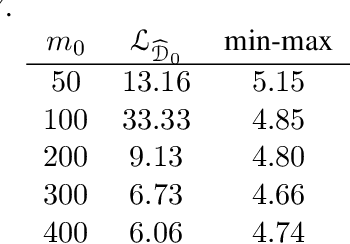
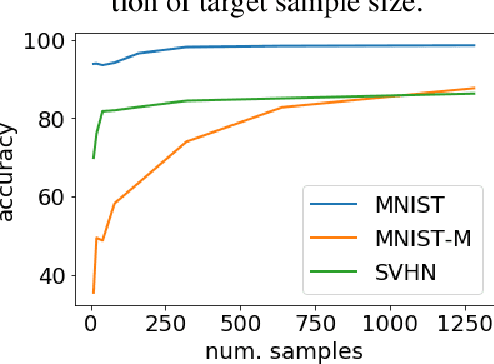
We study multiple-source domain adaptation, when the learner has access to abundant labeled data from multiple-source domains and limited labeled data from the target domain. We analyze existing algorithms for this problem, and propose a novel algorithm based on model selection. Our algorithms are efficient, and experiments on real data-sets empirically demonstrate their benefits.
Adversarial Stochastic Shortest Path
Jun 20, 2020Stochastic shortest path (SSP) is a well-known problem in planning and control, in which an agent has to reach a goal state in minimum total expected cost. In this paper we consider adversarial SSPs that also account for adversarial changes in the costs over time, while the dynamics (i.e., transition function) remains unchanged. Formally, an agent interacts with an SSP environment for $K$ episodes, the cost function changes arbitrarily between episodes, and the fixed dynamics are unknown to the agent. We give high probability regret bounds of $\widetilde O (\sqrt{K})$ assuming all costs are strictly positive, and $\widetilde O (K^{3/4})$ for the general case. To the best of our knowledge, we are the first to consider this natural setting of adversarial SSP and obtain sub-linear regret for it.
Reinforcement Learning with Feedback Graphs
May 07, 2020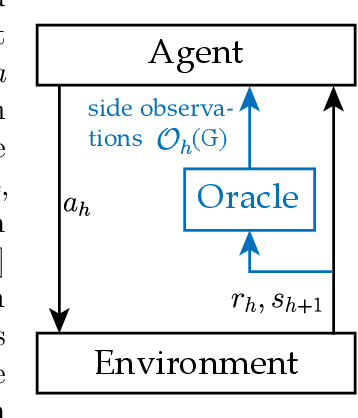


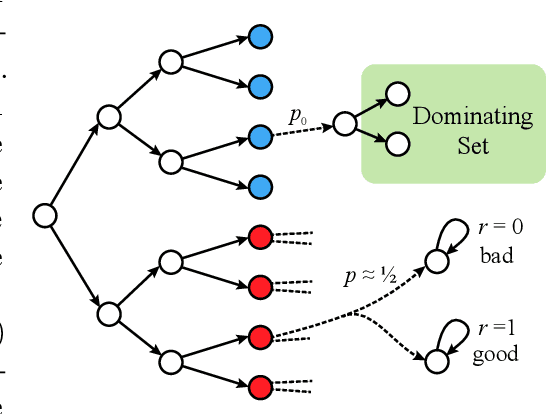
We study episodic reinforcement learning in Markov decision processes when the agent receives additional feedback per step in the form of several transition observations. Such additional observations are available in a range of tasks through extended sensors or prior knowledge about the environment (e.g., when certain actions yield similar outcome). We formalize this setting using a feedback graph over state-action pairs and show that model-based algorithms can leverage the additional feedback for more sample-efficient learning. We give a regret bound that, ignoring logarithmic factors and lower-order terms, depends only on the size of the maximum acyclic subgraph of the feedback graph, in contrast with a polynomial dependency on the number of states and actions in the absence of a feedback graph. Finally, we highlight challenges when leveraging a small dominating set of the feedback graph as compared to the bandit setting and propose a new algorithm that can use knowledge of such a dominating set for more sample-efficient learning of a near-optimal policy.
Sample Complexity of Uniform Convergence for Multicalibration
May 04, 2020There is a growing interest in societal concerns in machine learning systems, especially in fairness. Multicalibration gives a comprehensive methodology to address group fairness. In this work, we address the multicalibration error and decouple it from the prediction error. The importance of decoupling the fairness metric (multicalibration) and the accuracy (prediction error) is due to the inherent trade-off between the two, and the societal decision regarding the "right tradeoff" (as imposed many times by regulators). Our work gives sample complexity bounds for uniform convergence guarantees of multicalibration error, which implies that regardless of the accuracy, we can guarantee that the empirical and (true) multicalibration errors are close. We emphasize that our results: (1) are more general than previous bounds, as they apply to both agnostic and realizable settings, and do not rely on a specific type of algorithm (such as deferentially private), (2) improve over previous multicalibration sample complexity bounds and (3) implies uniform convergence guarantees for the classical calibration error.
Private Learning of Halfspaces: Simplifying the Construction and Reducing the Sample Complexity
Apr 16, 2020

We present a differentially private learner for halfspaces over a finite grid $G$ in $\mathbb{R}^d$ with sample complexity $\approx d^{2.5}\cdot 2^{\log^*|G|}$, which improves the state-of-the-art result of [Beimel et al., COLT 2019] by a $d^2$ factor. The building block for our learner is a new differentially private algorithm for approximately solving the linear feasibility problem: Given a feasible collection of $m$ linear constraints of the form $Ax\geq b$, the task is to privately identify a solution $x$ that satisfies most of the constraints. Our algorithm is iterative, where each iteration determines the next coordinate of the constructed solution $x$.
Adversarially Robust Streaming Algorithms via Differential Privacy
Apr 13, 2020A streaming algorithm is said to be adversarially robust if its accuracy guarantees are maintained even when the data stream is chosen maliciously, by an adaptive adversary. We establish a connection between adversarial robustness of streaming algorithms and the notion of differential privacy. This connection allows us to design new adversarially robust streaming algorithms that outperform the current state-of-the-art constructions for many interesting regimes of parameters.