 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombinatorial Bandits with Full-Bandit Feedback: Sample Complexity and Regret Minimization
May 28, 2019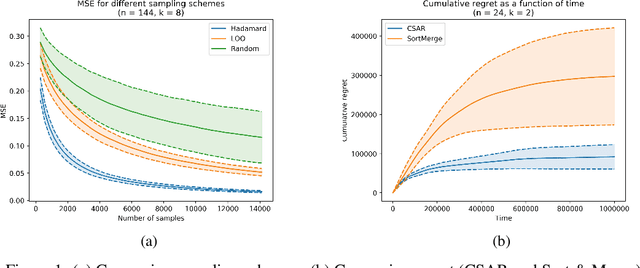
Combinatorial Bandits generalize multi-armed bandits, where k out of n arms are chosen at each round and the sum of the rewards is gained. We address the full-bandit feedback, in which the agent observes only the sum of rewards, in contrast to the semi-bandit feedback, in which the agent observes also the individual arms' rewards. We present the Combinatorial Successive Accepts and Rejects (CSAR) algorithm, which is a generalization of the SAR algorithm (Bubeck et al. 2013) for the combinatorial setting. Our main contribution is an efficient sampling scheme that uses Hadamard matrices in order to estimate accurately the individual arms' expected rewards. We discuss two variants of the algorithm, the first minimizes the sample complexity and the second minimizes the regret. For the sample complexity we also prove a matching lower bound that shows it is optimal. For the regret minimization, we prove a lower bound which is tight up to a factor of k. Finally, we run experiments and show that our algorithm outperforms other methods.
Repeated A/B Testing
May 28, 2019We study a setting in which a learner faces a sequence of A/B tests and has to make as many good decisions as possible within a given amount of time. Each A/B test $n$ is associated with an unknown (and potentially negative) reward $\mu_n \in [-1,1]$, drawn i.i.d. from an unknown and fixed distribution. For each A/B test $n$, the learner sequentially draws i.i.d. samples of a $\{-1,1\}$-valued random variable with mean $\mu_n$ until a halting criterion is met. The learner then decides to either accept the reward $\mu_n$ or to reject it and get zero instead. We measure the learner's performance as the sum of the expected rewards of the accepted $\mu_n$ divided by the total expected number of used time steps (which is different from the expected ratio between the total reward and the total number of used time steps). We design an algorithm and prove a data-dependent regret bound against any set of policies based on an arbitrary halting criterion and decision rule. Though our algorithm borrows ideas from multiarmed bandits, the two settings are significantly different and not directly comparable. In fact, the value of $\mu_n$ is never observed directly in our setting---unlike rewards in stochastic bandits. Moreover, the particular structure of our problem allows our regret bounds to be independent of the number of policies.
Efficient candidate screening under multiple tests and implications for fairness
May 27, 2019
When recruiting job candidates, employers rarely observe their underlying skill level directly. Instead, they must administer a series of interviews and/or collate other noisy signals in order to estimate the worker's skill. Traditional economics papers address screening models where employers access worker skill via a single noisy signal. In this paper, we extend this theoretical analysis to a multi-test setting, considering both Bernoulli and Gaussian models. We analyze the optimal employer policy both when the employer sets a fixed number of tests per candidate and when the employer can set a dynamic policy, assigning further tests adaptively based on results from the previous tests. To start, we characterize the optimal policy when employees constitute a single group, demonstrating some interesting trade-offs. Subsequently, we address the multi-group setting, demonstrating that when the noise levels vary across groups, a fundamental impossibility emerges whereby we cannot administer the same number of tests, subject candidates to the same decision rule, and yet realize the same outcomes in both groups.
Average reward reinforcement learning with unknown mixing times
May 23, 2019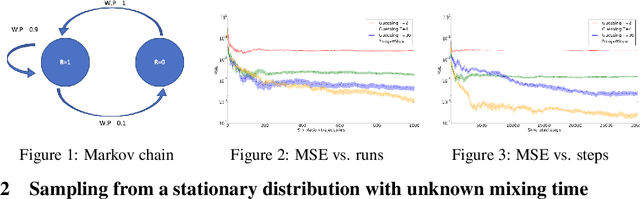
We derive and analyze learning algorithms for policy evaluation, apprenticeship learning, and policy gradient for average reward criteria. Existing algorithms explicitly require an upper bound on the mixing time. In contrast, we build on ideas from Markov chain theory and derive sampling algorithms that do not require such an upper bound. For these algorithms, we provide theoretical bounds on their sample-complexity and running time.
Online Convex Optimization in Adversarial Markov Decision Processes
May 19, 2019We consider online learning in episodic loop-free Markov decision processes (MDPs), where the loss function can change arbitrarily between episodes, and the transition function is not known to the learner. We show $\tilde{O}(L|X|\sqrt{|A|T})$ regret bound, where $T$ is the number of episodes, $X$ is the state space, $A$ is the action space, and $L$ is the length of each episode. Our online algorithm is implemented using entropic regularization methodology, which allows to extend the original adversarial MDP model to handle convex performance criteria (different ways to aggregate the losses of a single episode) , as well as improve previous regret bounds.
Competitive ratio versus regret minimization: achieving the best of both worlds
Apr 07, 2019
We consider online algorithms under both the competitive ratio criteria and the regret minimization one. Our main goal is to build a unified methodology that would be able to guarantee both criteria simultaneously. For a general class of online algorithms, namely any Metrical Task System (MTS), we show that one can simultaneously guarantee the best known competitive ratio and a natural regret bound. For the paging problem we further show an efficient online algorithm (polynomial in the number of pages) with this guarantee. To this end, we extend an existing regret minimization algorithm (specifically, Kapralov and Panigrahy) to handle movement cost (the cost of switching between states of the online system). We then show how to use the extended regret minimization algorithm to combine multiple online algorithms. Our end result is an online algorithm that can combine a "base" online algorithm, having a guaranteed competitive ratio, with a range of online algorithms that guarantee a small regret over any interval of time. The combined algorithm guarantees both that the competitive ratio matches that of the base algorithm and a low regret over any time interval. As a by product, we obtain an expert algorithm with close to optimal regret bound on every time interval, even in the presence of switching costs. This result is of independent interest.
Planning in Hierarchical Reinforcement Learning: Guarantees for Using Local Policies
Feb 26, 2019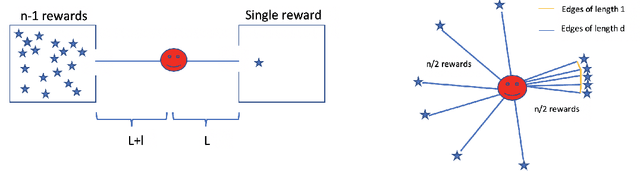
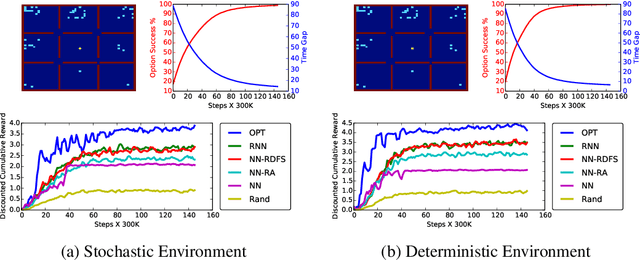
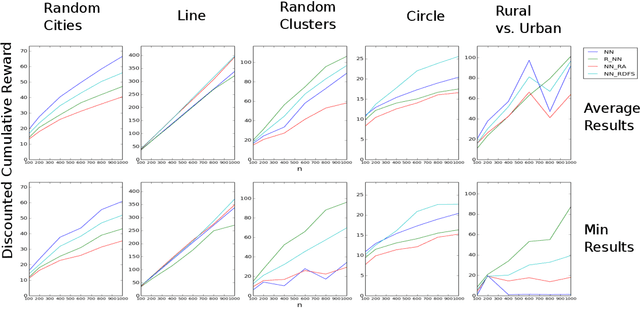
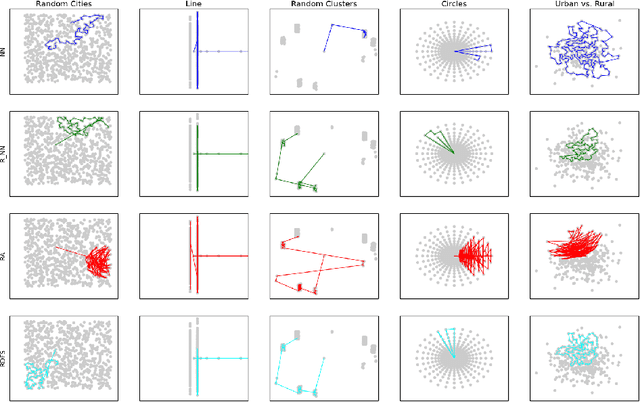
We consider a settings of hierarchical reinforcement learning, in which the reward is a sum of components. For each component we are given a policy that maximizes it and our goal is to assemble a policy from the individual policies that maximizes the sum of the components. We provide theoretical guarantees for assembling such policies in deterministic MDPs with collectible rewards. Our approach builds on formulating this problem as a traveling salesman problem with discounted reward. We focus on local solutions, i.e., policies that only use information from the current state; thus, they are easy to implement and do not require substantial computational resources. We propose three local stochastic policies and prove that they guarantee better performance than any deterministic local policy in the worst case; experimental results suggest that they also perform better on average.
Learning and Generalization for Matching Problems
Feb 24, 2019
We study a classic algorithmic problem through the lens of statistical learning. That is, we consider a matching problem where the input graph is sampled from some distribution. This distribution is unknown to the algorithm; however, an additional graph which is sampled from the same distribution is given during a training phase (preprocessing). More specifically, the algorithmic problem is to match $k$ out of $n$ items that arrive online to $d$ categories ($d\ll k \ll n$). Our goal is to design a two-stage online algorithm that retains a small subset of items in the first stage which contains an offline matching of maximum weight. We then compute this optimal matching in a second stage. The added statistical component is that before the online matching process begins, our algorithms learn from a training set consisting of another matching instance drawn from the same unknown distribution. Using this training set, we learn a policy that we apply during the online matching process. We consider a class of online policies that we term \emph{thresholds policies}. For this class, we derive uniform convergence results both for the number of retained items and the value of the optimal matching. We show that the number of retained items and the value of the offline optimal matching deviate from their expectation by $O(\sqrt{k})$. This requires usage of less-standard concentration inequalities (standard ones give deviations of $O(\sqrt{n})$). Furthermore, we design an algorithm that outputs the optimal offline solution with high probability while retaining only $O(k\log \log n)$ items in expectation.
Learning Linear-Quadratic Regulators Efficiently with only $\sqrt{T}$ Regret
Feb 23, 2019We present the first computationally-efficient algorithm with $\widetilde O(\sqrt{T})$ regret for learning in Linear Quadratic Control systems with unknown dynamics. By that, we resolve an open question of Abbasi-Yadkori and Szepesv\'ari (2011) and Dean, Mania, Matni, Recht, and Tu (2018).
Differentially Private Learning of Geometric Concepts
Feb 13, 2019We present differentially private efficient algorithms for learning union of polygons in the plane (which are not necessarily convex). Our algorithms achieve $(\alpha,\beta)$-PAC learning and $(\epsilon,\delta)$-differential privacy using a sample of size $\tilde{O}\left(\frac{1}{\alpha\epsilon}k\log d\right)$, where the domain is $[d]\times[d]$ and $k$ is the number of edges in the union of polygons.