 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning in Hierarchical Reinforcement Learning: Guarantees for Using Local Policies
Feb 26, 2019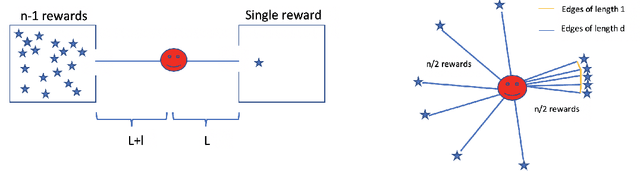
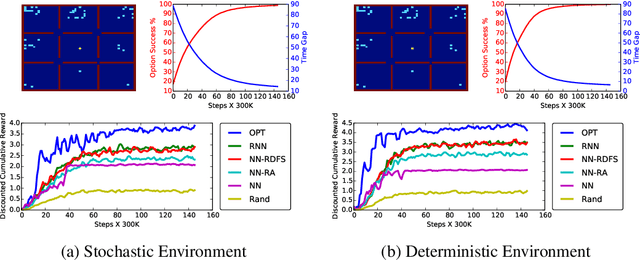
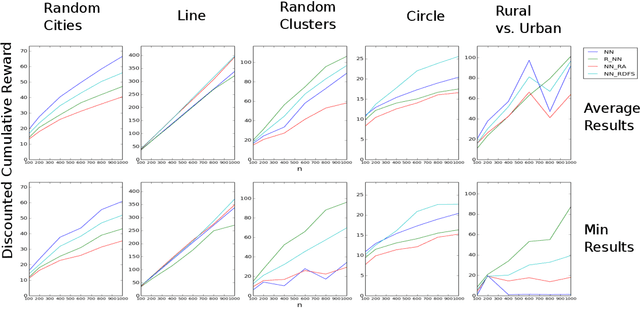
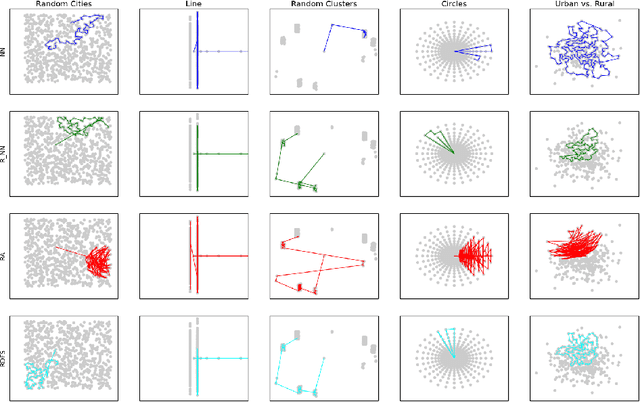
We consider a settings of hierarchical reinforcement learning, in which the reward is a sum of components. For each component we are given a policy that maximizes it and our goal is to assemble a policy from the individual policies that maximizes the sum of the components. We provide theoretical guarantees for assembling such policies in deterministic MDPs with collectible rewards. Our approach builds on formulating this problem as a traveling salesman problem with discounted reward. We focus on local solutions, i.e., policies that only use information from the current state; thus, they are easy to implement and do not require substantial computational resources. We propose three local stochastic policies and prove that they guarantee better performance than any deterministic local policy in the worst case; experimental results suggest that they also perform better on average.
Hierarchical Reinforcement Learning: Approximating Optimal Discounted TSP Using Local Policies
Mar 13, 2018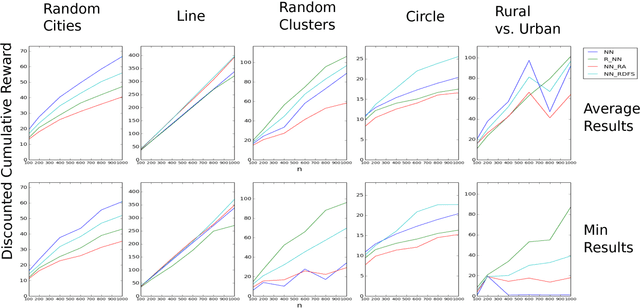
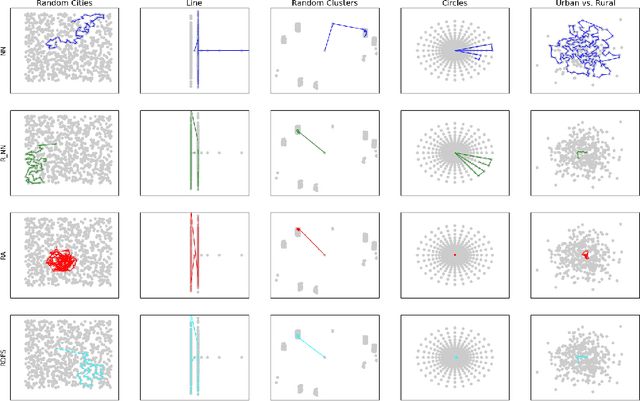
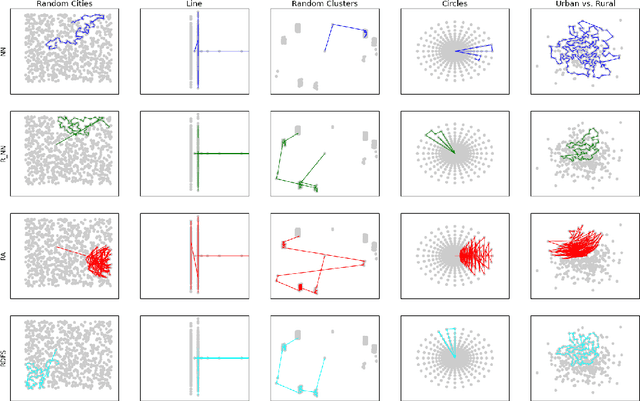
In this work, we provide theoretical guarantees for reward decomposition in deterministic MDPs. Reward decomposition is a special case of Hierarchical Reinforcement Learning, that allows one to learn many policies in parallel and combine them into a composite solution. Our approach builds on mapping this problem into a Reward Discounted Traveling Salesman Problem, and then deriving approximate solutions for it. In particular, we focus on approximate solutions that are local, i.e., solutions that only observe information about the current state. Local policies are easy to implement and do not require substantial computational resources as they do not perform planning. While local deterministic policies, like Nearest Neighbor, are being used in practice for hierarchical reinforcement learning, we propose three stochastic policies that guarantee better performance than any deterministic policy.