 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaLA: Unified Optimal Linear Approximation to Softmax Attention Map
Nov 16, 2024



Various linear complexity models, such as Linear Transformer (LinFormer), State Space Model (SSM), and Linear RNN (LinRNN), have been proposed to replace the conventional softmax attention in Transformer structures. However, the optimal design of these linear models is still an open question. In this work, we attempt to answer this question by finding the best linear approximation to softmax attention from a theoretical perspective. We start by unifying existing linear complexity models as the linear attention form and then identify three conditions for the optimal linear attention design: 1) Dynamic memory ability; 2) Static approximation ability; 3) Least parameter approximation. We find that none of the current linear models meet all three conditions, resulting in suboptimal performance. Instead, we propose Meta Linear Attention (MetaLA) as a solution that satisfies these conditions. Our experiments on Multi-Query Associative Recall (MQAR) task, language modeling, image classification, and Long-Range Arena (LRA) benchmark demonstrate that MetaLA is more effective than the existing linear models.
Storyboard guided Alignment for Fine-grained Video Action Recognition
Oct 18, 2024Fine-grained video action recognition can be conceptualized as a video-text matching problem. Previous approaches often rely on global video semantics to consolidate video embeddings, which can lead to misalignment in video-text pairs due to a lack of understanding of action semantics at an atomic granularity level. To tackle this challenge, we propose a multi-granularity framework based on two observations: (i) videos with different global semantics may share similar atomic actions or appearances, and (ii) atomic actions within a video can be momentary, slow, or even non-directly related to the global video semantics. Inspired by the concept of storyboarding, which disassembles a script into individual shots, we enhance global video semantics by generating fine-grained descriptions using a pre-trained large language model. These detailed descriptions capture common atomic actions depicted in videos. A filtering metric is proposed to select the descriptions that correspond to the atomic actions present in both the videos and the descriptions. By employing global semantics and fine-grained descriptions, we can identify key frames in videos and utilize them to aggregate embeddings, thereby making the embedding more accurate. Extensive experiments on various video action recognition datasets demonstrate superior performance of our proposed method in supervised, few-shot, and zero-shot settings.
Label-anticipated Event Disentanglement for Audio-Visual Video Parsing
Jul 11, 2024Audio-Visual Video Parsing (AVVP) task aims to detect and temporally locate events within audio and visual modalities. Multiple events can overlap in the timeline, making identification challenging. While traditional methods usually focus on improving the early audio-visual encoders to embed more effective features, the decoding phase -- crucial for final event classification, often receives less attention. We aim to advance the decoding phase and improve its interpretability. Specifically, we introduce a new decoding paradigm, \underline{l}abel s\underline{e}m\underline{a}ntic-based \underline{p}rojection (LEAP), that employs labels texts of event categories, each bearing distinct and explicit semantics, for parsing potentially overlapping events.LEAP works by iteratively projecting encoded latent features of audio/visual segments onto semantically independent label embeddings. This process, enriched by modeling cross-modal (audio/visual-label) interactions, gradually disentangles event semantics within video segments to refine relevant label embeddings, guaranteeing a more discriminative and interpretable decoding process. To facilitate the LEAP paradigm, we propose a semantic-aware optimization strategy, which includes a novel audio-visual semantic similarity loss function. This function leverages the Intersection over Union of audio and visual events (EIoU) as a novel metric to calibrate audio-visual similarities at the feature level, accommodating the varied event densities across modalities. Extensive experiments demonstrate the superiority of our method, achieving new state-of-the-art performance for AVVP and also enhancing the relevant audio-visual event localization task.
Scaling Laws for Linear Complexity Language Models
Jun 24, 2024The interest in linear complexity models for large language models is on the rise, although their scaling capacity remains uncertain. In this study, we present the scaling laws for linear complexity language models to establish a foundation for their scalability. Specifically, we examine the scaling behaviors of three efficient linear architectures. These include TNL, a linear attention model with data-independent decay; HGRN2, a linear RNN with data-dependent decay; and cosFormer2, a linear attention model without decay. We also include LLaMA as a baseline architecture for softmax attention for comparison. These models were trained with six variants, ranging from 70M to 7B parameters on a 300B-token corpus, and evaluated with a total of 1,376 intermediate checkpoints on various downstream tasks. These tasks include validation loss, commonsense reasoning, and information retrieval and generation. The study reveals that existing linear complexity language models exhibit similar scaling capabilities as conventional transformer-based models while also demonstrating superior linguistic proficiency and knowledge retention.
Advancing Weakly-Supervised Audio-Visual Video Parsing via Segment-wise Pseudo Labeling
Jun 03, 2024The Audio-Visual Video Parsing task aims to identify and temporally localize the events that occur in either or both the audio and visual streams of audible videos. It often performs in a weakly-supervised manner, where only video event labels are provided, \ie, the modalities and the timestamps of the labels are unknown. Due to the lack of densely annotated labels, recent work attempts to leverage pseudo labels to enrich the supervision. A commonly used strategy is to generate pseudo labels by categorizing the known video event labels for each modality. However, the labels are still confined to the video level, and the temporal boundaries of events remain unlabeled. In this paper, we propose a new pseudo label generation strategy that can explicitly assign labels to each video segment by utilizing prior knowledge learned from the open world. Specifically, we exploit the large-scale pretrained models, namely CLIP and CLAP, to estimate the events in each video segment and generate segment-level visual and audio pseudo labels, respectively. We then propose a new loss function to exploit these pseudo labels by taking into account their category-richness and segment-richness. A label denoising strategy is also adopted to further improve the visual pseudo labels by flipping them whenever abnormally large forward losses occur. We perform extensive experiments on the LLP dataset and demonstrate the effectiveness of each proposed design and we achieve state-of-the-art video parsing performance on all types of event parsing, \ie, audio event, visual event, and audio-visual event. We also examine the proposed pseudo label generation strategy on a relevant weakly-supervised audio-visual event localization task and the experimental results again verify the benefits and generalization of our method.
You Only Scan Once: Efficient Multi-dimension Sequential Modeling with LightNet
May 31, 2024



Linear attention mechanisms have gained prominence in causal language models due to their linear computational complexity and enhanced speed. However, the inherent decay mechanism in linear attention presents challenges when applied to multi-dimensional sequence modeling tasks, such as image processing and multi-modal learning. In these scenarios, the utilization of sequential scanning to establish a global receptive field necessitates multiple scans for multi-dimensional data, thereby leading to inefficiencies. This paper identifies the inefficiency caused by a multiplicative linear recurrence and proposes an efficient alternative additive linear recurrence to avoid the issue, as it can handle multi-dimensional data within a single scan. We further develop an efficient multi-dimensional sequential modeling framework called LightNet based on the new recurrence. Moreover, we present two new multi-dimensional linear relative positional encoding methods, MD-TPE and MD-LRPE to enhance the model's ability to discern positional information in multi-dimensional scenarios. Our empirical evaluations across various tasks, including image classification, image generation, bidirectional language modeling, and autoregressive language modeling, demonstrate the efficacy of LightNet, showcasing its potential as a versatile and efficient solution for multi-dimensional sequential modeling.
Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention
May 27, 2024We present Lightning Attention, the first linear attention implementation that maintains a constant training speed for various sequence lengths under fixed memory consumption. Due to the issue with cumulative summation operations (cumsum), previous linear attention implementations cannot achieve their theoretical advantage in a casual setting. However, this issue can be effectively solved by utilizing different attention calculation strategies to compute the different parts of attention. Specifically, we split the attention calculation into intra-blocks and inter-blocks and use conventional attention computation for intra-blocks and linear attention kernel tricks for inter-blocks. This eliminates the need for cumsum in the linear attention calculation. Furthermore, a tiling technique is adopted through both forward and backward procedures to take full advantage of the GPU hardware. To enhance accuracy while preserving efficacy, we introduce TransNormerLLM (TNL), a new architecture that is tailored to our lightning attention. We conduct rigorous testing on standard and self-collected datasets with varying model sizes and sequence lengths. TNL is notably more efficient than other language models. In addition, benchmark results indicate that TNL performs on par with state-of-the-art LLMs utilizing conventional transformer structures. The source code is released at github.com/OpenNLPLab/TransnormerLLM.
Unlocking the Secrets of Linear Complexity Sequence Model from A Unified Perspective
May 27, 2024We present the Linear Complexity Sequence Model (LCSM), a comprehensive solution that unites various sequence modeling techniques with linear complexity, including linear attention, state space model, long convolution, and linear RNN, within a single framework. The goal is to enhance comprehension of these models by analyzing the impact of each component from a cohesive and streamlined viewpoint. Specifically, we segment the modeling processes of these models into three distinct stages: Expand, Oscillation, and Shrink (EOS), with each model having its own specific settings. The Expand stage involves projecting the input signal onto a high-dimensional memory state. This is followed by recursive operations performed on the memory state in the Oscillation stage. Finally, the memory state is projected back to a low-dimensional space in the Shrink stage. We perform comprehensive experiments to analyze the impact of different stage settings on language modeling and retrieval tasks. Our results show that data-driven methods are crucial for the effectiveness of the three stages in language modeling, whereas hand-crafted methods yield better performance in retrieval tasks.
TAVGBench: Benchmarking Text to Audible-Video Generation
Apr 22, 2024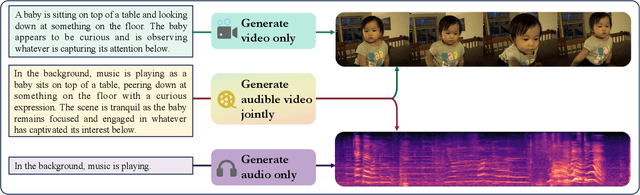

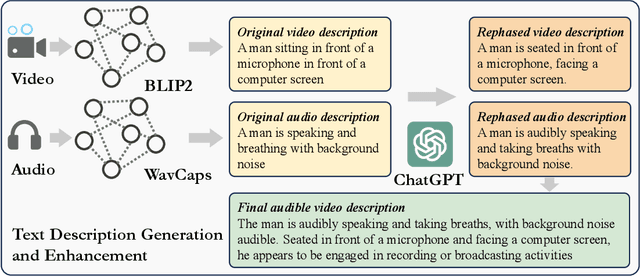

The Text to Audible-Video Generation (TAVG) task involves generating videos with accompanying audio based on text descriptions. Achieving this requires skillful alignment of both audio and video elements. To support research in this field, we have developed a comprehensive Text to Audible-Video Generation Benchmark (TAVGBench), which contains over 1.7 million clips with a total duration of 11.8 thousand hours. We propose an automatic annotation pipeline to ensure each audible video has detailed descriptions for both its audio and video contents. We also introduce the Audio-Visual Harmoni score (AVHScore) to provide a quantitative measure of the alignment between the generated audio and video modalities. Additionally, we present a baseline model for TAVG called TAVDiffusion, which uses a two-stream latent diffusion model to provide a fundamental starting point for further research in this area. We achieve the alignment of audio and video by employing cross-attention and contrastive learning. Through extensive experiments and evaluations on TAVGBench, we demonstrate the effectiveness of our proposed model under both conventional metrics and our proposed metrics.
HGRN2: Gated Linear RNNs with State Expansion
Apr 11, 2024



Hierarchically gated linear RNN (HGRN,Qin et al. 2023) has demonstrated competitive training speed and performance in language modeling, while offering efficient inference. However, the recurrent state size of HGRN remains relatively small, which limits its expressiveness.To address this issue, inspired by linear attention, we introduce a simple outer-product-based state expansion mechanism so that the recurrent state size can be significantly enlarged without introducing any additional parameters. The linear attention form also allows for hardware-efficient training.Our extensive experiments verify the advantage of HGRN2 over HGRN1 in language modeling, image classification, and Long Range Arena.Our largest 3B HGRN2 model slightly outperforms Mamba and LLaMa Architecture Transformer for language modeling in a controlled experiment setting; and performs competitively with many open-source 3B models in downstream evaluation while using much fewer total training tokens.