 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
Apr 06, 2022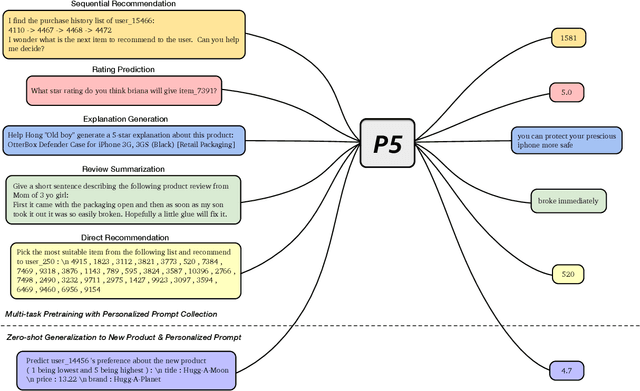
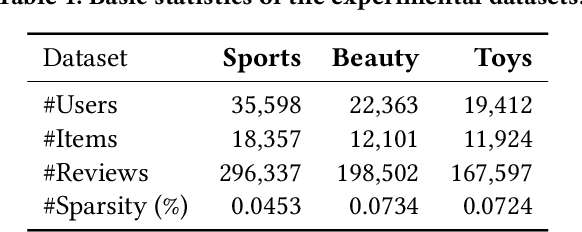
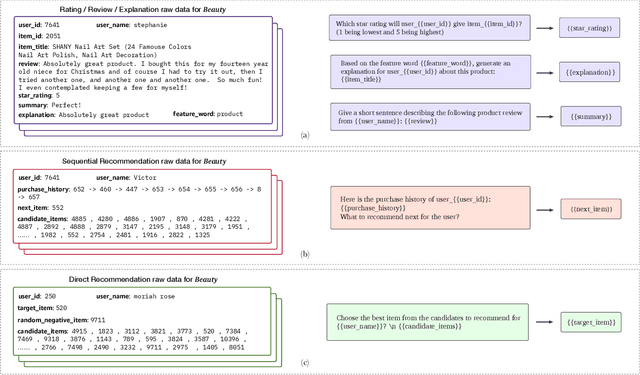
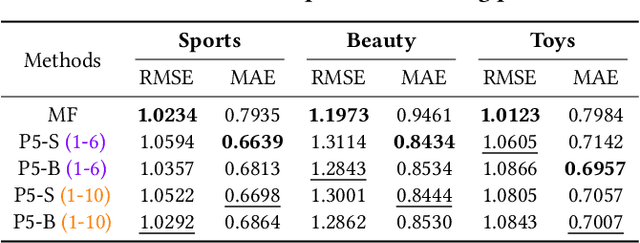
For a long period, different recommendation tasks typically require designing task-specific architectures and training objectives. As a result, it is hard to transfer the learned knowledge and representations from one task to another, thus restricting the generalization ability of existing recommendation approaches, e.g., a sequential recommendation model can hardly be applied or transferred to a review generation method. To deal with such issues, considering that language grounding is a powerful medium to describe and represent various problems or tasks, we present a flexible and unified text-to-text paradigm called "Pretrain, Personalized Prompt, and Predict Paradigm" (P5) for recommendation, which unifies various recommendation tasks in a shared framework. In P5, all data such as user-item interactions, item metadata, and user reviews are converted to a common format -- natural language sequences. The rich information from natural language assist P5 to capture deeper semantics for recommendation. P5 learns different tasks with the same language modeling objective during pretraining. Thus, it possesses the potential to serve as the foundation model for downstream recommendation tasks, allows easy integration with other modalities, and enables instruction-based recommendation, which will revolutionize the technical form of recommender system towards universal recommendation engine. With adaptive personalized prompt for different users, P5 is able to make predictions in a zero-shot or few-shot manner and largely reduces the necessity for extensive fine-tuning. On several recommendation benchmarks, we conduct experiments to show the effectiveness of our generative approach. We will release our prompts and pretrained P5 language model to help advance future research on Recommendation as Language Processing (RLP) and Personalized Foundation Models.
Learning and Evaluating Graph Neural Network Explanations based on Counterfactual and Factual Reasoning
Feb 17, 2022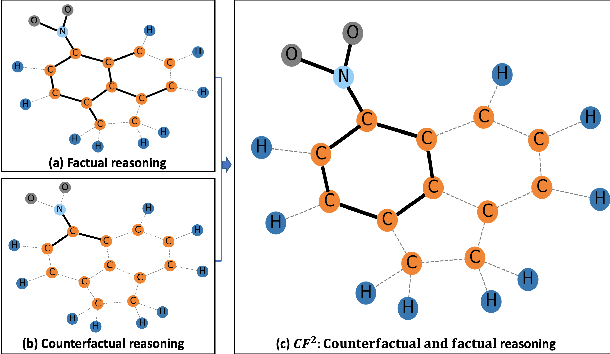
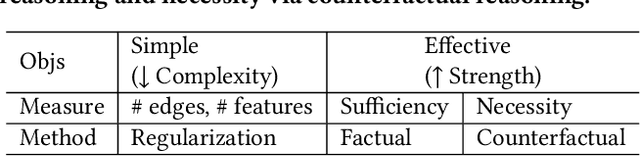

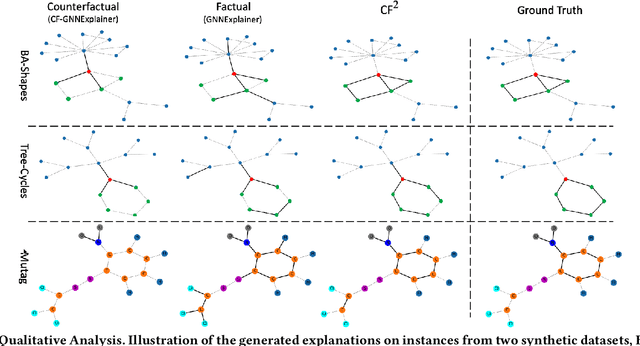
Structural data well exists in Web applications, such as social networks in social media, citation networks in academic websites, and threads data in online forums. Due to the complex topology, it is difficult to process and make use of the rich information within such data. Graph Neural Networks (GNNs) have shown great advantages on learning representations for structural data. However, the non-transparency of the deep learning models makes it non-trivial to explain and interpret the predictions made by GNNs. Meanwhile, it is also a big challenge to evaluate the GNN explanations, since in many cases, the ground-truth explanations are unavailable. In this paper, we take insights of Counterfactual and Factual (CF^2) reasoning from causal inference theory, to solve both the learning and evaluation problems in explainable GNNs. For generating explanations, we propose a model-agnostic framework by formulating an optimization problem based on both of the two casual perspectives. This distinguishes CF^2 from previous explainable GNNs that only consider one of them. Another contribution of the work is the evaluation of GNN explanations. For quantitatively evaluating the generated explanations without the requirement of ground-truth, we design metrics based on Counterfactual and Factual reasoning to evaluate the necessity and sufficiency of the explanations. Experiments show that no matter ground-truth explanations are available or not, CF^2 generates better explanations than previous state-of-the-art methods on real-world datasets. Moreover, the statistic analysis justifies the correlation between the performance on ground-truth evaluation and our proposed metrics.
Toward Pareto Efficient Fairness-Utility Trade-off inRecommendation through Reinforcement Learning
Jan 01, 2022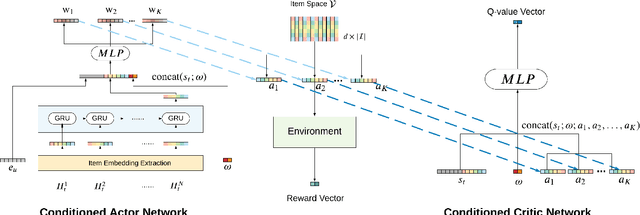

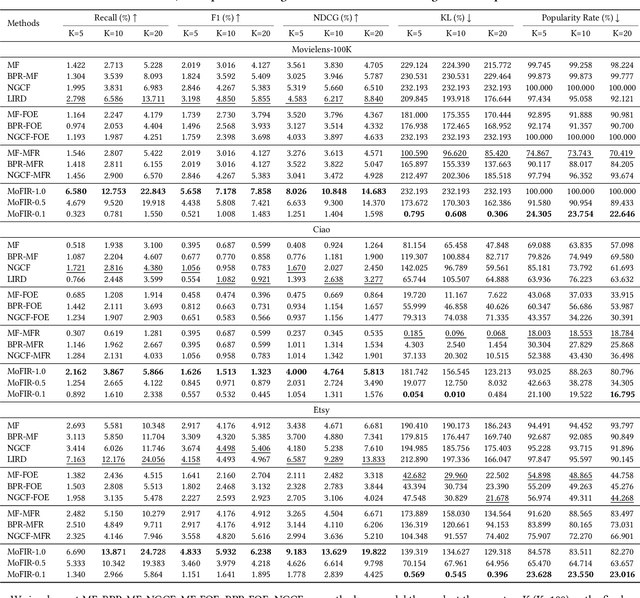
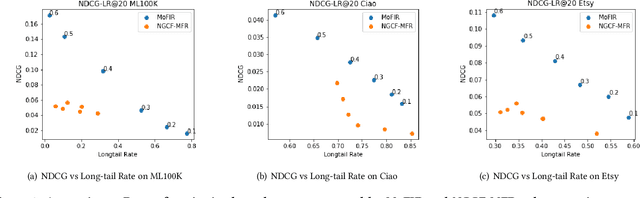
The issue of fairness in recommendation is becoming increasingly essential as Recommender Systems touch and influence more and more people in their daily lives. In fairness-aware recommendation, most of the existing algorithmic approaches mainly aim at solving a constrained optimization problem by imposing a constraint on the level of fairness while optimizing the main recommendation objective, e.g., CTR. While this alleviates the impact of unfair recommendations, the expected return of an approach may significantly compromise the recommendation accuracy due to the inherent trade-off between fairness and utility. This motivates us to deal with these conflicting objectives and explore the optimal trade-off between them in recommendation. One conspicuous approach is to seek a Pareto efficient solution to guarantee optimal compromises between utility and fairness. Moreover, considering the needs of real-world e-commerce platforms, it would be more desirable if we can generalize the whole Pareto Frontier, so that the decision-makers can specify any preference of one objective over another based on their current business needs. Therefore, in this work, we propose a fairness-aware recommendation framework using multi-objective reinforcement learning, called MoFIR, which is able to learn a single parametric representation for optimal recommendation policies over the space of all possible preferences. Specially, we modify traditional DDPG by introducing conditioned network into it, which conditions the networks directly on these preferences and outputs Q-value-vectors. Experiments on several real-world recommendation datasets verify the superiority of our framework on both fairness metrics and recommendation measures when compared with all other baselines. We also extract the approximate Pareto Frontier on real-world datasets generated by MoFIR and compare to state-of-the-art fairness methods.
Counterfactual Evaluation for Explainable AI
Sep 05, 2021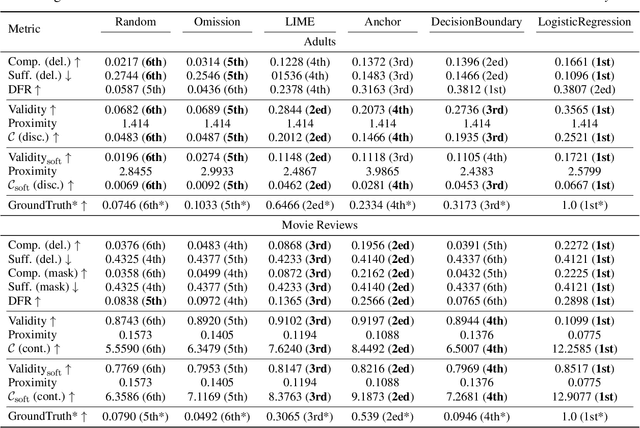
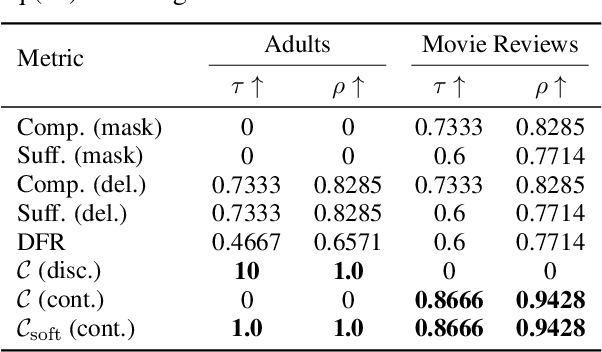
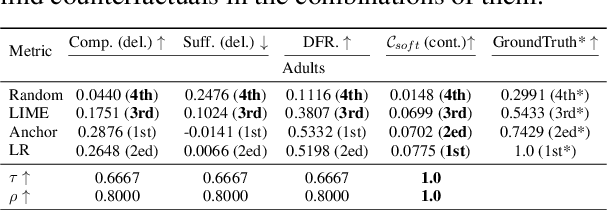
While recent years have witnessed the emergence of various explainable methods in machine learning, to what degree the explanations really represent the reasoning process behind the model prediction -- namely, the faithfulness of explanation -- is still an open problem. One commonly used way to measure faithfulness is \textit{erasure-based} criteria. Though conceptually simple, erasure-based criterion could inevitably introduce biases and artifacts. We propose a new methodology to evaluate the faithfulness of explanations from the \textit{counterfactual reasoning} perspective: the model should produce substantially different outputs for the original input and its corresponding counterfactual edited on a faithful feature. Specially, we introduce two algorithms to find the proper counterfactuals in both discrete and continuous scenarios and then use the acquired counterfactuals to measure faithfulness. Empirical results on several datasets show that compared with existing metrics, our proposed counterfactual evaluation method can achieve top correlation with the ground truth under diffe
Counterfactual Explainable Recommendation
Aug 24, 2021
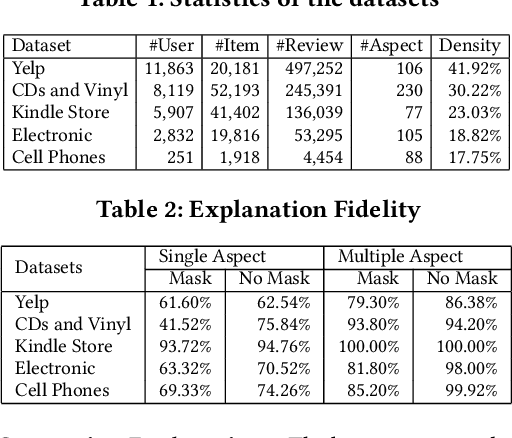
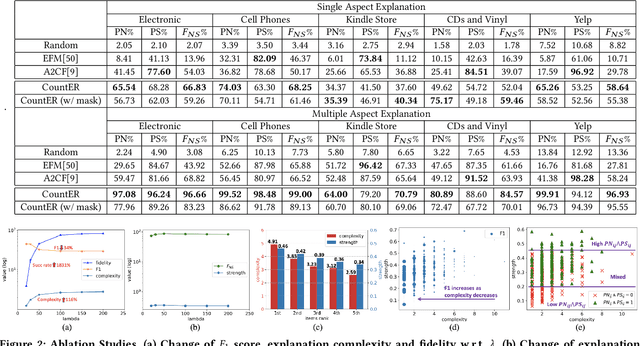
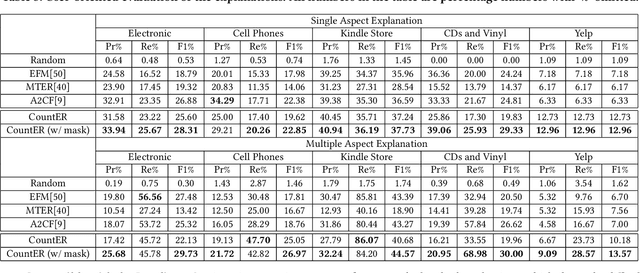
By providing explanations for users and system designers to facilitate better understanding and decision making, explainable recommendation has been an important research problem. In this paper, we propose Counterfactual Explainable Recommendation (CountER), which takes the insights of counterfactual reasoning from causal inference for explainable recommendation. CountER is able to formulate the complexity and the strength of explanations, and it adopts a counterfactual learning framework to seek simple (low complexity) and effective (high strength) explanations for the model decision. Technically, for each item recommended to each user, CountER formulates a joint optimization problem to generate minimal changes on the item aspects so as to create a counterfactual item, such that the recommendation decision on the counterfactual item is reversed. These altered aspects constitute the explanation of why the original item is recommended. The counterfactual explanation helps both the users for better understanding and the system designers for better model debugging. Another contribution of the work is the evaluation of explainable recommendation, which has been a challenging task. Fortunately, counterfactual explanations are very suitable for standard quantitative evaluation. To measure the explanation quality, we design two types of evaluation metrics, one from user's perspective (i.e. why the user likes the item), and the other from model's perspective (i.e. why the item is recommended by the model). We apply our counterfactual learning algorithm on a black-box recommender system and evaluate the generated explanations on five real-world datasets. Results show that our model generates more accurate and effective explanations than state-of-the-art explainable recommendation models.
FAIR: Fairness-Aware Information Retrieval Evaluation
Jun 16, 2021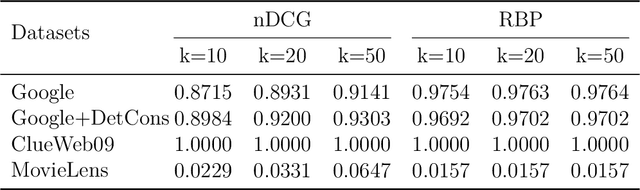
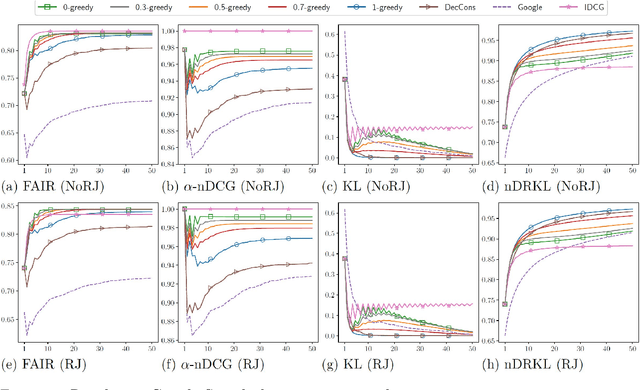
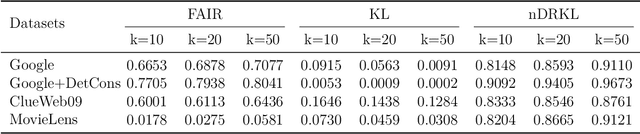
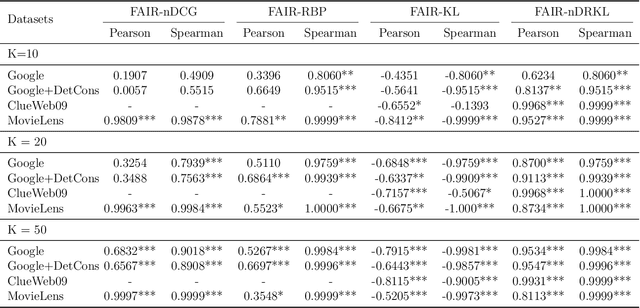
With the emerging needs of creating fairness-aware solutions for search and recommendation systems, a daunting challenge exists of evaluating such solutions. While many of the traditional information retrieval (IR) metrics can capture the relevance, diversity and novelty for the utility with respect to users, they are not suitable for inferring whether the presented results are fair from the perspective of responsible information exposure. On the other hand, various fairness metrics have been proposed but they do not account for the user utility or do not measure it adequately. To address this problem, we propose a new metric called Fairness-Aware IR (FAIR). By unifying standard IR metrics and fairness measures into an integrated metric, this metric offers a new perspective for evaluating fairness-aware ranking results. Based on this metric, we developed an effective ranking algorithm that jointly optimized user utility and fairness. The experimental results showed that our FAIR metric could highlight results with good user utility and fair information exposure. We showed how FAIR related to existing metrics and demonstrated the effectiveness of our FAIR-based algorithm. We believe our work opens up a new direction of pursuing a computationally feasible metric for evaluating and implementing the fairness-aware IR systems.
Towards Personalized Fairness based on Causal Notion
May 20, 2021

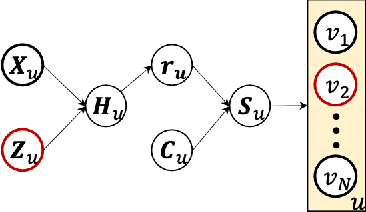
Recommender systems are gaining increasing and critical impacts on human and society since a growing number of users use them for information seeking and decision making. Therefore, it is crucial to address the potential unfairness problems in recommendations. Just like users have personalized preferences on items, users' demands for fairness are also personalized in many scenarios. Therefore, it is important to provide personalized fair recommendations for users to satisfy their personalized fairness demands. Besides, previous works on fair recommendation mainly focus on association-based fairness. However, it is important to advance from associative fairness notions to causal fairness notions for assessing fairness more properly in recommender systems. Based on the above considerations, this paper focuses on achieving personalized counterfactual fairness for users in recommender systems. To this end, we introduce a framework for achieving counterfactually fair recommendations through adversary learning by generating feature-independent user embeddings for recommendation. The framework allows recommender systems to achieve personalized fairness for users while also covering non-personalized situations. Experiments on two real-world datasets with shallow and deep recommendation algorithms show that our method can generate fairer recommendations for users with a desirable recommendation performance.
Efficient Non-Sampling Knowledge Graph Embedding
Apr 30, 2021
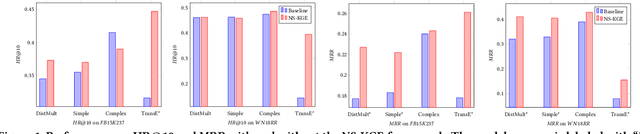
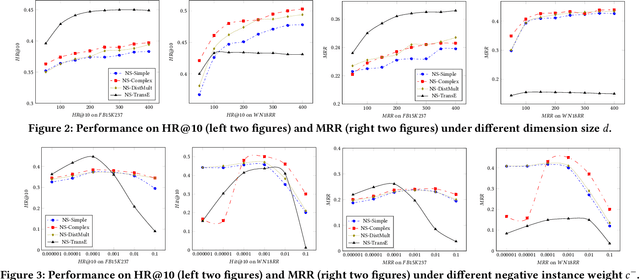
Knowledge Graph (KG) is a flexible structure that is able to describe the complex relationship between data entities. Currently, most KG embedding models are trained based on negative sampling, i.e., the model aims to maximize some similarity of the connected entities in the KG, while minimizing the similarity of the sampled disconnected entities. Negative sampling helps to reduce the time complexity of model learning by only considering a subset of negative instances, which may fail to deliver stable model performance due to the uncertainty in the sampling procedure. To avoid such deficiency, we propose a new framework for KG embedding -- Efficient Non-Sampling Knowledge Graph Embedding (NS-KGE). The basic idea is to consider all of the negative instances in the KG for model learning, and thus to avoid negative sampling. The framework can be applied to square-loss based knowledge graph embedding models or models whose loss can be converted to a square loss. A natural side-effect of this non-sampling strategy is the increased computational complexity of model learning. To solve the problem, we leverage mathematical derivations to reduce the complexity of non-sampling loss function, which eventually provides us both better efficiency and better accuracy in KG embedding compared with existing models. Experiments on benchmark datasets show that our NS-KGE framework can achieve a better performance on efficiency and accuracy over traditional negative sampling based models, and that the framework is applicable to a large class of knowledge graph embedding models.
User-oriented Fairness in Recommendation
Apr 21, 2021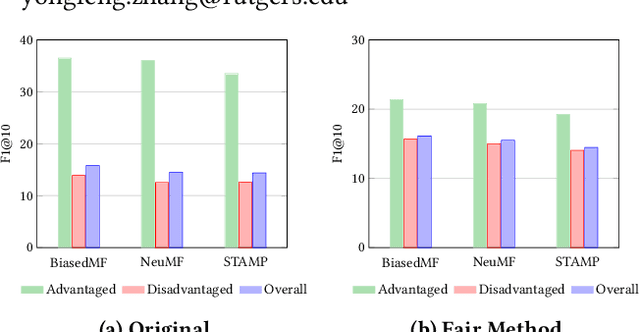
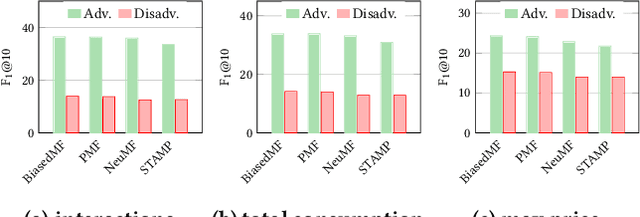
As a highly data-driven application, recommender systems could be affected by data bias, resulting in unfair results for different data groups, which could be a reason that affects the system performance. Therefore, it is important to identify and solve the unfairness issues in recommendation scenarios. In this paper, we address the unfairness problem in recommender systems from the user perspective. We group users into advantaged and disadvantaged groups according to their level of activity, and conduct experiments to show that current recommender systems will behave unfairly between two groups of users. Specifically, the advantaged users (active) who only account for a small proportion in data enjoy much higher recommendation quality than those disadvantaged users (inactive). Such bias can also affect the overall performance since the disadvantaged users are the majority. To solve this problem, we provide a re-ranking approach to mitigate this unfairness problem by adding constraints over evaluation metrics. The experiments we conducted on several real-world datasets with various recommendation algorithms show that our approach can not only improve group fairness of users in recommender systems, but also achieve better overall recommendation performance.
Variation Control and Evaluation for Generative SlateRecommendations
Feb 26, 2021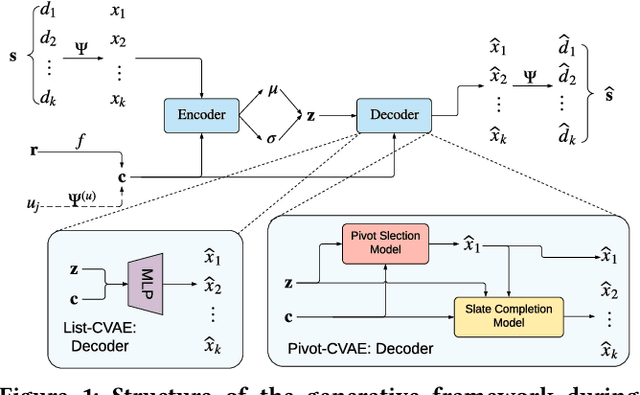

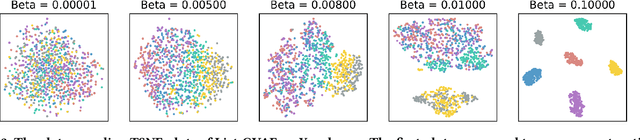
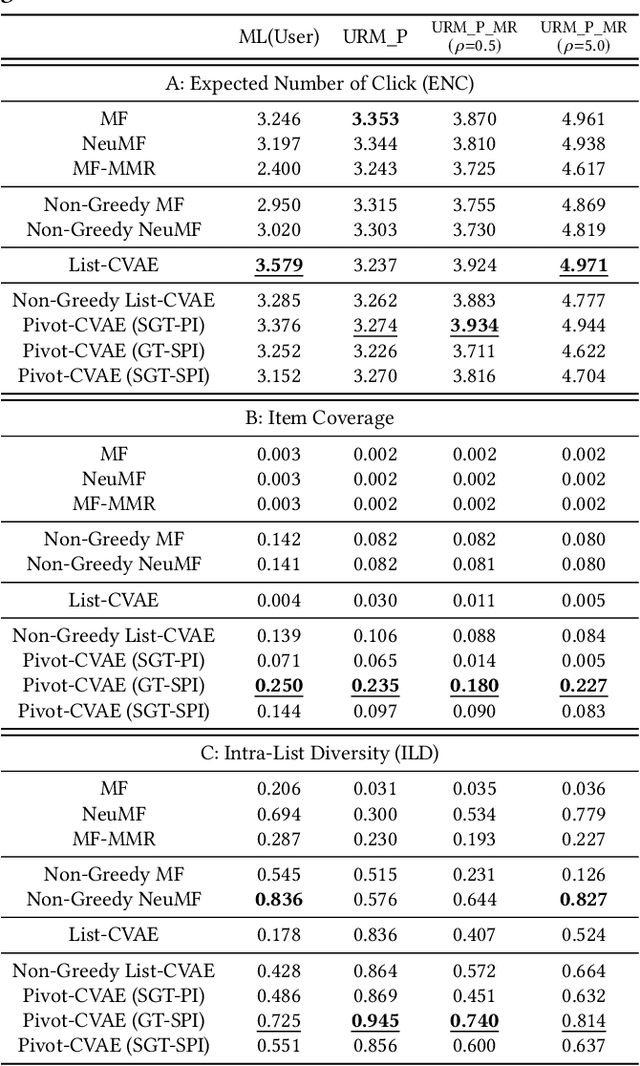
Slate recommendation generates a list of items as a whole instead of ranking each item individually, so as to better model the intra-list positional biases and item relations. In order to deal with the enormous combinatorial space of slates, recent work considers a generative solution so that a slate distribution can be directly modeled. However, we observe that such approaches -- despite their proved effectiveness in computer vision -- suffer from a trade-off dilemma in recommender systems: when focusing on reconstruction, they easily over-fit the data and hardly generate satisfactory recommendations; on the other hand, when focusing on satisfying the user interests, they get trapped in a few items and fail to cover the item variation in slates. In this paper, we propose to enhance the accuracy-based evaluation with slate variation metrics to estimate the stochastic behavior of generative models. We illustrate that instead of reaching to one of the two undesirable extreme cases in the dilemma, a valid generative solution resides in a narrow "elbow" region in between. And we show that item perturbation can enforce slate variation and mitigate the over-concentration of generated slates, which expand the "elbow" performance to an easy-to-find region. We further propose to separate a pivot selection phase from the generation process so that the model can apply perturbation before generation. Empirical results show that this simple modification can provide even better variance with the same level of accuracy compared to post-generation perturbation methods.