 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlue Data Intelligence Layer: Streaming Data and Agents for Multi-source Multi-modal Data-Centric Applications
Apr 16, 2026NL2SQL systems aim to address the growing need for natural language interaction with data. However, real-world information rarely maps to a single SQL query because (1) users express queries iteratively (2) questions often span multiple data sources beyond the closed-world assumption of a single database, and (3) queries frequently rely on commonsense or external knowledge. Consequently, satisfying realistic data needs require integrating heterogeneous sources, modalities, and contextual data. In this paper, we present Blue's Data Intelligence Layer (DIL) designed to support multi-source, multi-modal, and data-centric applications. Blue is a compound AI system that orchestrates agents and data for enterprise settings. DIL serves as the data intelligence layer for agentic data processing, to bridge the semantic gap between user intent and available information by unifying structured enterprise data, world knowledge accessible through LLMs, and personal context obtained through interaction. At the core of DIL is a data registry that stores metadata for diverse data sources and modalities to enable both native and natural language queries. DIL treats LLMs, the Web, and the User as source 'databases', each with their own query interface, elevating them to first-class data sources. DIL relies on data planners to transform user queries into executable query plans. These plans are declarative abstractions that unify relational operators with other operators spanning multiple modalities. DIL planners support decomposition of complex requests into subqueries, retrieval from diverse sources, and finally reasoning and integration to produce final results. We demonstrate DIL through two interactive scenarios in which user queries dynamically trigger multi-source retrieval, cross-modal reasoning, and result synthesis, illustrating how compound AI systems can move beyond single database NL2SQL.
REQUAL-LM: Reliability and Equity through Aggregation in Large Language Models
Apr 17, 2024



The extensive scope of large language models (LLMs) across various domains underscores the critical importance of responsibility in their application, beyond natural language processing. In particular, the randomized nature of LLMs, coupled with inherent biases and historical stereotypes in data, raises critical concerns regarding reliability and equity. Addressing these challenges are necessary before using LLMs for applications with societal impact. Towards addressing this gap, we introduce REQUAL-LM, a novel method for finding reliable and equitable LLM outputs through aggregation. Specifically, we develop a Monte Carlo method based on repeated sampling to find a reliable output close to the mean of the underlying distribution of possible outputs. We formally define the terms such as reliability and bias, and design an equity-aware aggregation to minimize harmful bias while finding a highly reliable output. REQUAL-LM does not require specialized hardware, does not impose a significant computing load, and uses LLMs as a blackbox. This design choice enables seamless scalability alongside the rapid advancement of LLM technologies. Our system does not require retraining the LLMs, which makes it deployment ready and easy to adapt. Our comprehensive experiments using various tasks and datasets demonstrate that REQUAL- LM effectively mitigates bias and selects a more equitable response, specifically the outputs that properly represents minority groups.
FairEM360: A Suite for Responsible Entity Matching
Apr 10, 2024Entity matching is one the earliest tasks that occur in the big data pipeline and is alarmingly exposed to unintentional biases that affect the quality of data. Identifying and mitigating the biases that exist in the data or are introduced by the matcher at this stage can contribute to promoting fairness in downstream tasks. This demonstration showcases FairEM360, a framework for 1) auditing the output of entity matchers across a wide range of fairness measures and paradigms, 2) providing potential explanations for the underlying reasons for unfairness, and 3) providing resolutions for the unfairness issues through an exploratory process with human-in-the-loop feedback, utilizing an ensemble of matchers. We aspire for FairEM360 to contribute to the prioritization of fairness as a key consideration in the evaluation of EM pipelines.
Through the Fairness Lens: Experimental Analysis and Evaluation of Entity Matching
Jul 06, 2023



Entity matching (EM) is a challenging problem studied by different communities for over half a century. Algorithmic fairness has also become a timely topic to address machine bias and its societal impacts. Despite extensive research on these two topics, little attention has been paid to the fairness of entity matching. Towards addressing this gap, we perform an extensive experimental evaluation of a variety of EM techniques in this paper. We generated two social datasets from publicly available datasets for the purpose of auditing EM through the lens of fairness. Our findings underscore potential unfairness under two common conditions in real-world societies: (i) when some demographic groups are overrepresented, and (ii) when names are more similar in some groups compared to others. Among our many findings, it is noteworthy to mention that while various fairness definitions are valuable for different settings, due to EM's class imbalance nature, measures such as positive predictive value parity and true positive rate parity are, in general, more capable of revealing EM unfairness.
A Survey on Techniques for Identifying and Resolving Representation Bias in Data
Mar 22, 2022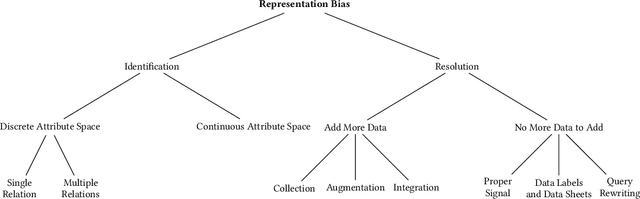
The grand goal of data-driven decision-making is to help humans make decisions, not only easily and at scale but also wisely, accurately, and just. However, data-driven algorithms are only as good as the data they work with, while data sets, especially social data, often miss representing minorities. Representation Bias in data can happen due to various reasons ranging from historical discrimination to selection and sampling biases in the data acquisition and preparation methods. One cannot expect AI-based societal solutions to have equitable outcomes without addressing the representation bias. This paper surveys the existing literature on representation bias in the data. It presents a taxonomy to categorize the studied techniques based on multiple design dimensions and provide a side-by-side comparison of their properties. There is still a long way to fully address representation bias issues in data. The authors hope that this survey motivates researchers to approach these challenges in the future by observing existing work within their respective domains.