 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2I-Calib++: A Multi-terminal Spatial Calibration Approach in Urban Intersections for Collaborative Perception
Oct 14, 2024



Urban intersections, dense with pedestrian and vehicular traffic and compounded by GPS signal obstructions from high-rise buildings, are among the most challenging areas in urban traffic systems. Traditional single-vehicle intelligence systems often perform poorly in such environments due to a lack of global traffic flow information and the ability to respond to unexpected events. Vehicle-to-Everything (V2X) technology, through real-time communication between vehicles (V2V) and vehicles to infrastructure (V2I), offers a robust solution. However, practical applications still face numerous challenges. Calibration among heterogeneous vehicle and infrastructure endpoints in multi-end LiDAR systems is crucial for ensuring the accuracy and consistency of perception system data. Most existing multi-end calibration methods rely on initial calibration values provided by positioning systems, but the instability of GPS signals due to high buildings in urban canyons poses severe challenges to these methods. To address this issue, this paper proposes a novel multi-end LiDAR system calibration method that does not require positioning priors to determine initial external parameters and meets real-time requirements. Our method introduces an innovative multi-end perception object association technique, utilizing a new Overall Distance metric (oDist) to measure the spatial association between perception objects, and effectively combines global consistency search algorithms with optimal transport theory. By this means, we can extract co-observed targets from object association results for further external parameter computation and optimization. Extensive comparative and ablation experiments conducted on the simulated dataset V2X-Sim and the real dataset DAIR-V2X confirm the effectiveness and efficiency of our method. The code for this method can be accessed at: \url{https://github.com/MassimoQu/v2i-calib}.
V2I-Calib: A Novel Calibration Approach for Collaborative Vehicle and Infrastructure LiDAR Systems
Jul 14, 2024



Cooperative vehicle and infrastructure LiDAR systems hold great potential, yet their implementation faces numerous challenges. Calibration of LiDAR systems across heterogeneous vehicle and infrastructure endpoints is a critical step to ensure the accuracy and consistency of perception system data, necessitating calibration methods that are real-time and stable. To this end, this paper introduces a novel calibration method for cooperative vehicle and road infrastructure LiDAR systems, which exploits spatial association information between detection boxes. The method centers around a novel Overall IoU metric that reflects the correlation of targets between vehicle and infrastructure, enabling real-time monitoring of calibration results. We search for common matching boxes between vehicle and infrastructure nodes by constructing an affinity matrix. Subsequently, these matching boxes undergo extrinsic parameter computation and optimization. Comparative and ablation experiments on the DAIR-V2X dataset confirm the superiority of our method. To better reflect the differences in calibration results, we have categorized the calibration tasks on the DAIR-V2X dataset based on their level of difficulty, enriching the dataset's utility for future research. Our project is available at https://github.com/MassimoQu/v2i-calib .
Cooperative Visual-LiDAR Extrinsic Calibration Technology for Intersection Vehicle-Infrastructure: A review
May 16, 2024



In the typical urban intersection scenario, both vehicles and infrastructures are equipped with visual and LiDAR sensors. By successfully integrating the data from vehicle-side and road monitoring devices, a more comprehensive and accurate environmental perception and information acquisition can be achieved. The Calibration of sensors, as an essential component of autonomous driving technology, has consistently drawn significant attention. Particularly in scenarios involving multiple sensors collaboratively perceiving and addressing localization challenges, the requirement for inter-sensor calibration becomes crucial. Recent years have witnessed the emergence of the concept of multi-end cooperation, where infrastructure captures and transmits surrounding environment information to vehicles, bolstering their perception capabilities while mitigating costs. However, this also poses technical complexities, underscoring the pressing need for diverse end calibration. Camera and LiDAR, the bedrock sensors in autonomous driving, exhibit expansive applicability. This paper comprehensively examines and analyzes the calibration of multi-end camera-LiDAR setups from vehicle, roadside, and vehicle-road cooperation perspectives, outlining their relevant applications and profound significance. Concluding with a summary, we present our future-oriented ideas and hypotheses.
Informative Data Selection with Uncertainty for Multi-modal Object Detection
Apr 23, 2023



Noise has always been nonnegligible trouble in object detection by creating confusion in model reasoning, thereby reducing the informativeness of the data. It can lead to inaccurate recognition due to the shift in the observed pattern, that requires a robust generalization of the models. To implement a general vision model, we need to develop deep learning models that can adaptively select valid information from multi-modal data. This is mainly based on two reasons. Multi-modal learning can break through the inherent defects of single-modal data, and adaptive information selection can reduce chaos in multi-modal data. To tackle this problem, we propose a universal uncertainty-aware multi-modal fusion model. It adopts a multi-pipeline loosely coupled architecture to combine the features and results from point clouds and images. To quantify the correlation in multi-modal information, we model the uncertainty, as the inverse of data information, in different modalities and embed it in the bounding box generation. In this way, our model reduces the randomness in fusion and generates reliable output. Moreover, we conducted a completed investigation on the KITTI 2D object detection dataset and its derived dirty data. Our fusion model is proven to resist severe noise interference like Gaussian, motion blur, and frost, with only slight degradation. The experiment results demonstrate the benefits of our adaptive fusion. Our analysis on the robustness of multi-modal fusion will provide further insights for future research.
Temporal and Spatial Online Integrated Calibration for Camera and LiDAR
Jul 21, 2022
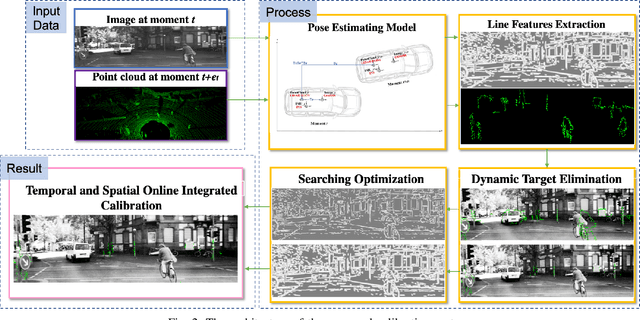
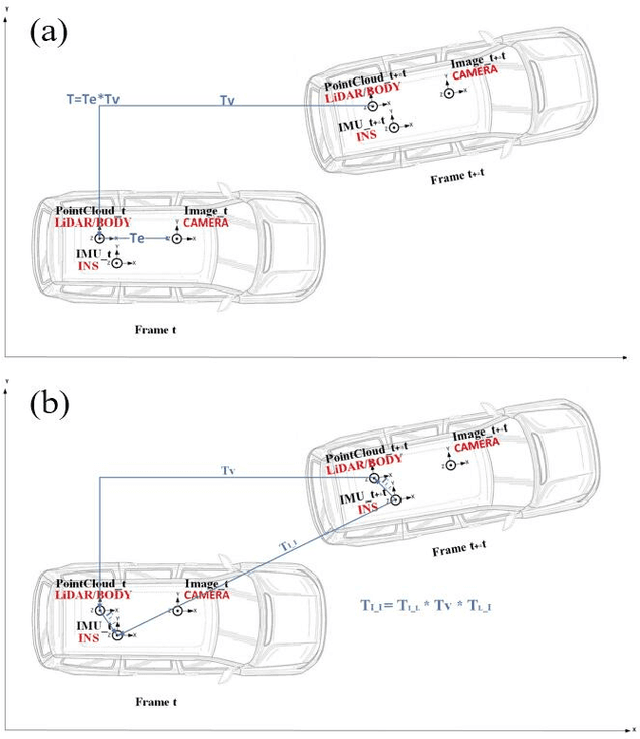

While camera and LiDAR are widely used in most of the assisted and autonomous driving systems, only a few works have been proposed to associate the temporal synchronization and extrinsic calibration for camera and LiDAR which are dedicated to online sensors data fusion. The temporal and spatial calibration technologies are facing the challenges of lack of relevance and real-time. In this paper, we introduce the pose estimation model and environmental robust line features extraction to improve the relevance of data fusion and instant online ability of correction. Dynamic targets eliminating aims to seek optimal policy considering the correspondence of point cloud matching between adjacent moments. The searching optimization process aims to provide accurate parameters with both computation accuracy and efficiency. To demonstrate the benefits of this method, we evaluate it on the KITTI benchmark with ground truth value. In online experiments, our approach improves the accuracy by 38.5\% than the soft synchronization method in temporal calibration. While in spatial calibration, our approach automatically corrects disturbance errors within 0.4 second and achieves an accuracy of 0.3-degree. This work can promote the research and application of sensor fusion.