 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGau-Occ: Geometry-Completed Gaussians for Multi-Modal 3D Occupancy Prediction
Mar 24, 20263D semantic occupancy prediction is crucial for autonomous driving. While multi-modal fusion improves accuracy over vision-only methods, it typically relies on computationally expensive dense voxel or BEV tensors. We present Gau-Occ, a multi-modal framework that bypasses dense volumetric processing by modeling the scene as a compact collection of semantic 3D Gaussians. To ensure geometric completeness, we propose a LiDAR Completion Diffuser (LCD) that recovers missing structures from sparse LiDAR to initialize robust Gaussian anchors. Furthermore, we introduce Gaussian Anchor Fusion (GAF), which efficiently integrates multi-view image semantics via geometry-aligned 2D sampling and cross-modal alignment. By refining these compact Gaussian descriptors, Gau-Occ captures both spatial consistency and semantic discriminability. Extensive experiments across challenging benchmarks demonstrate that Gau-Occ achieves state-of-the-art performance with significant computational efficiency.
Catalyst4D: High-Fidelity 3D-to-4D Scene Editing via Dynamic Propagation
Mar 13, 2026Recent advances in 3D scene editing using NeRF and 3DGS enable high-quality static scene editing. In contrast, dynamic scene editing remains challenging, as methods that directly extend 2D diffusion models to 4D often produce motion artifacts, temporal flickering, and inconsistent style propagation. We introduce Catalyst4D, a framework that transfers high-quality 3D edits to dynamic 4D Gaussian scenes while maintaining spatial and temporal coherence. At its core, Anchor-based Motion Guidance (AMG) builds a set of structurally stable and spatially representative anchors from both original and edited Gaussians. These anchors serve as robust region-level references, and their correspondences are established via optimal transport to enable consistent deformation propagation without cross-region interference or motion drift. Complementarily, Color Uncertainty-guided Appearance Refinement (CUAR) preserves temporal appearance consistency by estimating per-Gaussian color uncertainty and selectively refining regions prone to occlusion-induced artifacts. Extensive experiments demonstrate that Catalyst4D achieves temporally stable, high-fidelity dynamic scene editing and outperforms existing methods in both visual quality and motion coherence.
TokenSplat: Token-aligned 3D Gaussian Splatting for Feed-forward Pose-free Reconstruction
Feb 28, 2026We present TokenSplat, a feed-forward framework for joint 3D Gaussian reconstruction and camera pose estimation from unposed multi-view images. At its core, TokenSplat introduces a Token-aligned Gaussian Prediction module that aligns semantically corresponding information across views directly in the feature space. Guided by coarse token positions and fusion confidence, it aggregates multi-scale contextual features to enable long-range cross-view reasoning and reduce redundancy from overlapping Gaussians. To further enhance pose robustness and disentangle viewpoint cues from scene semantics, TokenSplat employs learnable camera tokens and an Asymmetric Dual-Flow Decoder (ADF-Decoder) that enforces directionally constrained communication between camera and image tokens. This maintains clean factorization within a feed-forward architecture, enabling coherent reconstruction and stable pose estimation without iterative refinement. Extensive experiments demonstrate that TokenSplat achieves higher reconstruction fidelity and novel-view synthesis quality in pose-free settings, and significantly improves pose estimation accuracy compared to prior pose-free methods. Project page: https://kidleyh.github.io/tokensplat/.
LLM Agents as VC investors: Predicting Startup Success via RolePlay-Based Collective Simulation
Dec 27, 2025Due to the high value and high failure rate of startups, predicting their success has become a critical challenge across interdisciplinary research. Existing approaches typically model success prediction from the perspective of a single decision-maker, overlooking the collective dynamics of investor groups that dominate real-world venture capital (VC) decisions. In this paper, we propose SimVC-CAS, a novel collective agent system that simulates VC decision-making as a multi-agent interaction process. By designing role-playing agents and a GNN-based supervised interaction module, we reformulate startup financing prediction as a group decision-making task, capturing both enterprise fundamentals and the behavioral dynamics of potential investor networks. Each agent embodies an investor with unique traits and preferences, enabling heterogeneous evaluation and realistic information exchange through a graph-structured co-investment network. Using real-world data from PitchBook and under strict data leakage controls, we show that SimVC-CAS significantly improves predictive accuracy while providing interpretable, multiperspective reasoning, for example, approximately 25% relative improvement with respect to average precision@10. SimVC-CAS also sheds light on other complex group decision scenarios.
Micro-macro Gaussian Splatting with Enhanced Scalability for Unconstrained Scene Reconstruction
Jun 16, 2025Reconstructing 3D scenes from unconstrained image collections poses significant challenges due to variations in appearance. In this paper, we propose Scalable Micro-macro Wavelet-based Gaussian Splatting (SMW-GS), a novel method that enhances 3D reconstruction across diverse scales by decomposing scene representations into global, refined, and intrinsic components. SMW-GS incorporates the following innovations: Micro-macro Projection, which enables Gaussian points to sample multi-scale details with improved diversity; and Wavelet-based Sampling, which refines feature representations using frequency-domain information to better capture complex scene appearances. To achieve scalability, we further propose a large-scale scene promotion strategy, which optimally assigns camera views to scene partitions by maximizing their contributions to Gaussian points, achieving consistent and high-quality reconstructions even in expansive environments. Extensive experiments demonstrate that SMW-GS significantly outperforms existing methods in both reconstruction quality and scalability, particularly excelling in large-scale urban environments with challenging illumination variations. Project is available at https://github.com/Kidleyh/SMW-GS.
Micro-macro Wavelet-based Gaussian Splatting for 3D Reconstruction from Unconstrained Images
Jan 24, 20253D reconstruction from unconstrained image collections presents substantial challenges due to varying appearances and transient occlusions. In this paper, we introduce Micro-macro Wavelet-based Gaussian Splatting (MW-GS), a novel approach designed to enhance 3D reconstruction by disentangling scene representations into global, refined, and intrinsic components. The proposed method features two key innovations: Micro-macro Projection, which allows Gaussian points to capture details from feature maps across multiple scales with enhanced diversity; and Wavelet-based Sampling, which leverages frequency domain information to refine feature representations and significantly improve the modeling of scene appearances. Additionally, we incorporate a Hierarchical Residual Fusion Network to seamlessly integrate these features. Extensive experiments demonstrate that MW-GS delivers state-of-the-art rendering performance, surpassing existing methods.
Question Answering for Decisionmaking in Green Building Design: A Multimodal Data Reasoning Method Driven by Large Language Models
Dec 06, 2024



In recent years, the critical role of green buildings in addressing energy consumption and environmental issues has become widely acknowledged. Research indicates that over 40% of potential energy savings can be achieved during the early design stage. Therefore, decision-making in green building design (DGBD), which is based on modeling and performance simulation, is crucial for reducing building energy costs. However, the field of green building encompasses a broad range of specialized knowledge, which involves significant learning costs and results in low decision-making efficiency. Many studies have already applied artificial intelligence (AI) methods to this field. Based on previous research, this study innovatively integrates large language models with DGBD, creating GreenQA, a question answering framework for multimodal data reasoning. Utilizing Retrieval Augmented Generation, Chain of Thought, and Function Call methods, GreenQA enables multimodal question answering, including weather data analysis and visualization, retrieval of green building cases, and knowledge query. Additionally, this study conducted a user survey using the GreenQA web platform. The results showed that 96% of users believed the platform helped improve design efficiency. This study not only effectively supports DGBD but also provides inspiration for AI-assisted design.
Distributed Hierarchical Distribution Control for Very-Large-Scale Clustered Multi-Agent Systems
May 30, 2023



As the scale and complexity of multi-agent robotic systems are subject to a continuous increase, this paper considers a class of systems labeled as Very-Large-Scale Multi-Agent Systems (VLMAS) with dimensionality that can scale up to the order of millions of agents. In particular, we consider the problem of steering the state distributions of all agents of a VLMAS to prescribed target distributions while satisfying probabilistic safety guarantees. Based on the key assumption that such systems often admit a multi-level hierarchical clustered structure - where the agents are organized into cliques of different levels - we associate the control of such cliques with the control of distributions, and introduce the Distributed Hierarchical Distribution Control (DHDC) framework. The proposed approach consists of two sub-frameworks. The first one, Distributed Hierarchical Distribution Estimation (DHDE), is a bottom-up hierarchical decentralized algorithm which links the initial and target configurations of the cliques of all levels with suitable Gaussian distributions. The second part, Distributed Hierarchical Distribution Steering (DHDS), is a top-down hierarchical distributed method that steers the distributions of all cliques and agents from the initial to the targets ones assigned by DHDE. Simulation results that scale up to two million agents demonstrate the effectiveness and scalability of the proposed framework. The increased computational efficiency and safety performance of DHDC against related methods is also illustrated. The results of this work indicate the importance of hierarchical distribution control approaches towards achieving safe and scalable solutions for the control of VLMAS. A video with all results is available in https://youtu.be/0QPyR4bD2q0 .
A SLAM Map Restoration Algorithm Based on Submaps and an Undirected Connected Graph
Jul 29, 2020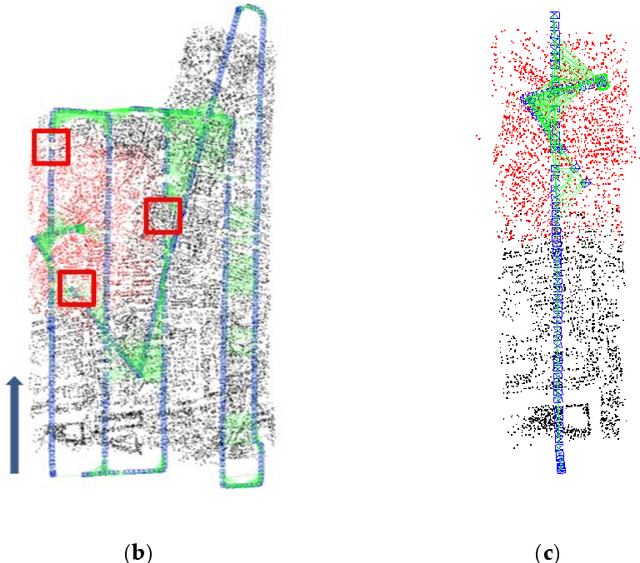

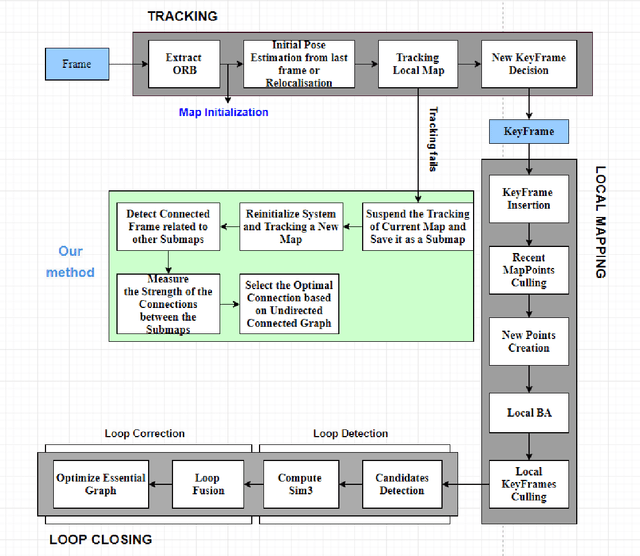
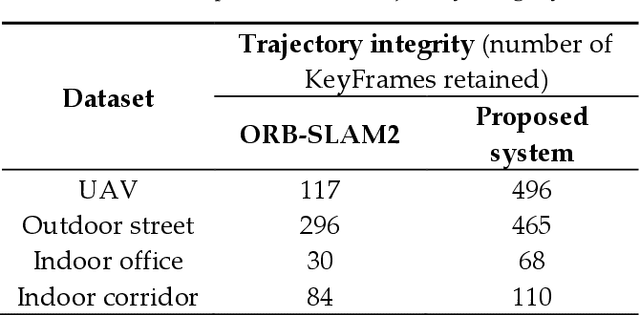
Many visual simultaneous localization and mapping (SLAM) systems have been shown to be accurate and robust, and have real-time performance capabilities on both indoor and ground datasets. However, these methods can be problematic when dealing with aerial frames captured by a camera mounted on an unmanned aerial vehicle (UAV) because the flight height of the UAV can be difficult to control and is easily affected by the environment.To cope with the case of lost tracking, many visual SLAM systems employ a relocalization strategy. This involves the tracking thread continuing the online working by inspecting the connections between the subsequent new frames and the generated map before the tracking was lost. To solve the missing map problem, which is an issue in many applications , after the tracking is lost, based on monocular visual SLAM, we present a method of reconstructing a complete global map of UAV datasets by sequentially merging the submaps via the corresponding undirected connected graph. Specifically, submaps are repeatedly generated, from the initialization process to the place where the tracking is lost, and a corresponding undirected connected graph is built by considering these submaps as nodes and the common map points within two submaps as edges. The common map points are then determined by the bag-of-words (BoW) method, and the submaps are merged if they are found to be connected with the online map in the undirect connected graph. To demonstrate the performance of the proposed method, we first investigated the performance on a UAV dataset, and the experimental results showed that, in the case of several tracking failures, the integrity of the mapping was significantly better than that of the current mainstream SLAM method.