 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
DeepStock: Reinforcement Learning with Policy Regularizations for Inventory Management
Mar 20, 2026Deep Reinforcement Learning (DRL) provides a general-purpose methodology for training inventory policies that can leverage big data and compute. However, off-the-shelf implementations of DRL have seen mixed success, often plagued by high sensitivity to the hyperparameters used during training. In this paper, we show that by imposing policy regularizations, grounded in classical inventory concepts such as "Base Stock", we can significantly accelerate hyperparameter tuning and improve the final performance of several DRL methods. We report details from a 100% deployment of DRL with policy regularizations on Alibaba's e-commerce platform, Tmall. We also include extensive synthetic experiments, which show that policy regularizations reshape the narrative on what is the best DRL method for inventory management.
Balanced Anomaly-guided Ego-graph Diffusion Model for Inductive Graph Anomaly Detection
Feb 05, 2026Graph anomaly detection (GAD) is crucial in applications like fraud detection and cybersecurity. Despite recent advancements using graph neural networks (GNNs), two major challenges persist. At the model level, most methods adopt a transductive learning paradigm, which assumes static graph structures, making them unsuitable for dynamic, evolving networks. At the data level, the extreme class imbalance, where anomalous nodes are rare, leads to biased models that fail to generalize to unseen anomalies. These challenges are interdependent: static transductive frameworks limit effective data augmentation, while imbalance exacerbates model distortion in inductive learning settings. To address these challenges, we propose a novel data-centric framework that integrates dynamic graph modeling with balanced anomaly synthesis. Our framework features: (1) a discrete ego-graph diffusion model, which captures the local topology of anomalies to generate ego-graphs aligned with anomalous structural distribution, and (2) a curriculum anomaly augmentation mechanism, which dynamically adjusts synthetic data generation during training, focusing on underrepresented anomaly patterns to improve detection and generalization. Experiments on five datasets demonstrate that the effectiveness of our framework.
A Deep Q-Network Based on Radial Basis Functions for Multi-Echelon Inventory Management
Jan 29, 2024



This paper addresses a multi-echelon inventory management problem with a complex network topology where deriving optimal ordering decisions is difficult. Deep reinforcement learning (DRL) has recently shown potential in solving such problems, while designing the neural networks in DRL remains a challenge. In order to address this, a DRL model is developed whose Q-network is based on radial basis functions. The approach can be more easily constructed compared to classic DRL models based on neural networks, thus alleviating the computational burden of hyperparameter tuning. Through a series of simulation experiments, the superior performance of this approach is demonstrated compared to the simple base-stock policy, producing a better policy in the multi-echelon system and competitive performance in the serial system where the base-stock policy is optimal. In addition, the approach outperforms current DRL approaches.
Dynamic Pricing on E-commerce Platform with Deep Reinforcement Learning
Dec 05, 2019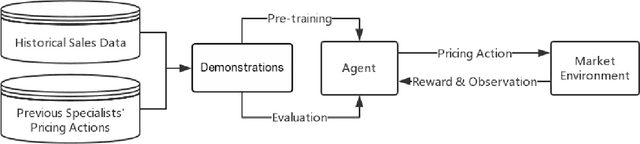
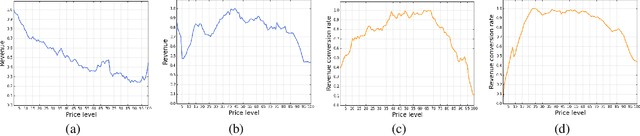
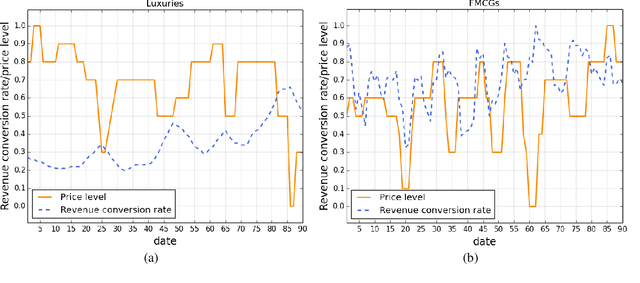
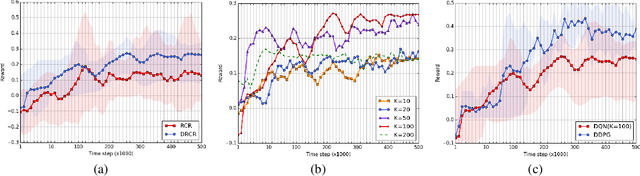
In this paper we present an end-to-end framework for addressing the problem of dynamic pricing on E-commerce platform using methods based on deep reinforcement learning (DRL). By using four groups of different business data to represent the states of each time period, we model the dynamic pricing problem as a Markov Decision Process (MDP). Compared with the state-of-the-art DRL-based dynamic pricing algorithms, our approaches make the following three contributions. First, we extend the discrete set problem to the continuous price set. Second, instead of using revenue as the reward function directly, we define a new function named difference of revenue conversion rates (DRCR). Third, the cold-start problem of MDP is tackled by pre-training and evaluation using some carefully chosen historical sales data. Our approaches are evaluated by both offline evaluation method using real dataset of Alibaba Inc., and online field experiments on Tmall.com, a major online shopping website owned by Alibaba Inc.. In particular, experiment results suggest that DRCR is a more appropriate reward function than revenue, which is widely used by current literature. In the end, field experiments, which last for months on 1000 stock keeping units (SKUs) of products demonstrate that continuous price sets have better performance than discrete sets and show that our approaches significantly outperformed the manual pricing by operation experts.
Context-Based Dynamic Pricing with Online Clustering
Feb 17, 2019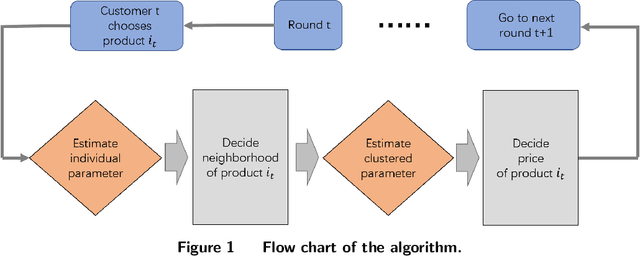

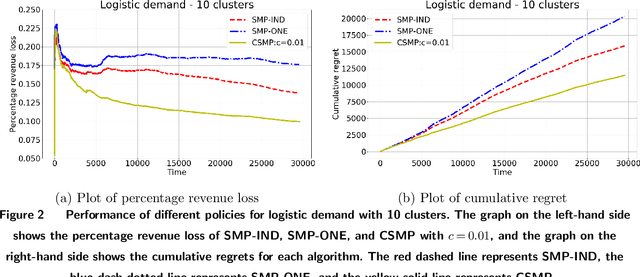
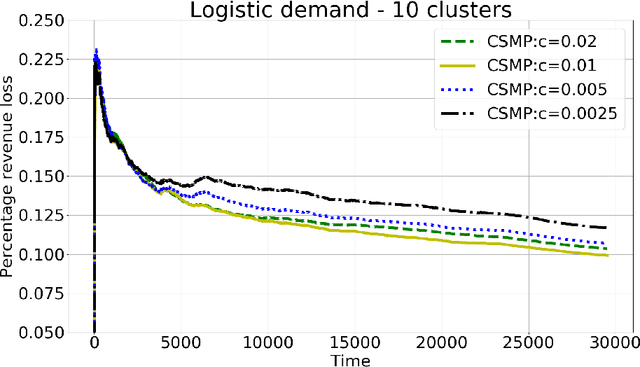
We consider a context-based dynamic pricing problem of online products which have low sales. Sales data from Alibaba, a major global online retailer, illustrate the prevalence of low-sale products. For these products, existing single-product dynamic pricing algorithms do not work well due to insufficient data samples. To address this challenge, we propose pricing policies that concurrently perform clustering over products and set individual pricing decisions on the fly. By clustering data and identifying products that have similar demand patterns, we utilize sales data from products within the same cluster to improve demand estimation and allow for better pricing decisions. We evaluate the algorithms using the regret, and the result shows that when product demand functions come from multiple clusters, our algorithms significantly outperform traditional single-product pricing policies. Numerical experiments using a real dataset from Alibaba demonstrate that the proposed policies, compared with several benchmark policies, increase the revenue. The results show that online clustering is an effective approach to tackling dynamic pricing problems associated with low-sale products. Our algorithms were further implemented in a field study at Alibaba with 40 products for 30 consecutive days, and compared to the products which use business-as-usual pricing policy of Alibaba. The results from the field experiment show that the overall revenue increased by 10.14%.