 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Aware Memory Cards: Counterfactual-Inspired Context Selection and Compression for Tool-Using LLM Agents
Jun 06, 2026Tool-using LLM agents often fail not because relevant text is absent, but because decisive evidence is not selected, compressed, or surfaced at action time. We present CICL, a decision-aware context layer that turns instance evidence into a context graph, routes deterministic, Opus-assisted, Qwen, Codex/GPT-5.5, and Qwen-QLoRA judgments through a shared eight-field schema, scores units by action shift, outcome uplift, necessity, and negative-transfer risk, and packs high-utility evidence as typed memory cards for a budgeted agent. The design separates the measured decision signal from the judge model, so frontier annotation, local surrogates, and lightweight rankers can be compared under one auditable protocol. Empirically, CICL yields a concrete open-benchmark gain while exposing its limits. On 50 SWE-bench Verified file-retrieval instances, direct Qwen3.6-plus reranking of BM25 top-50 candidates raises hit@1 from 0.58 to 0.78 and MRR@10 from 0.634 to 0.790, with all 2,500 judgments parseable. Controlled diagnostics show action-criticality: at budget 120, CICL reaches F1 0.620 on v1 and 0.425 on v3, and removing the top-utility semantic v3 unit collapses F1 to 0.000. Supplementary checks add Qwen-QLoRA agreement over 710 candidates, a small 200-label real-code Opus-assisted signal, and a three-instance patch smoke validating retrieval-to-patch plumbing without claiming official SWE-bench success. RepoBench-R summaries still beat cards, and compact rankers do not yet replace the heuristic. CICL contributes a reproducible measurement and selection layer for decision-critical context, not an end-to-end coding-agent repair claim.
Dynamic Pricing on E-commerce Platform with Deep Reinforcement Learning
Dec 05, 2019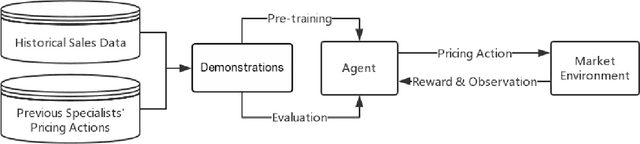
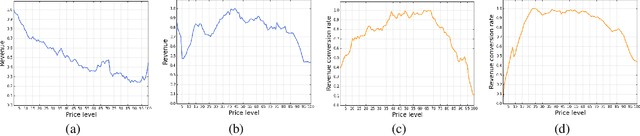
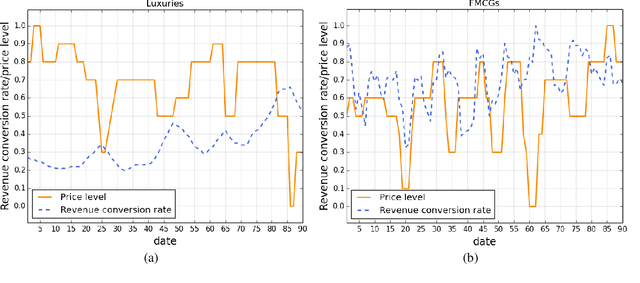
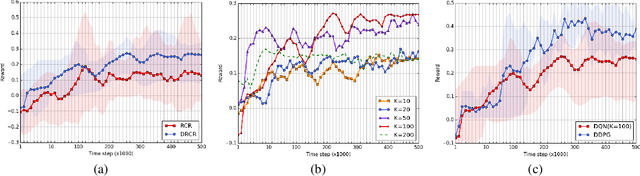
In this paper we present an end-to-end framework for addressing the problem of dynamic pricing on E-commerce platform using methods based on deep reinforcement learning (DRL). By using four groups of different business data to represent the states of each time period, we model the dynamic pricing problem as a Markov Decision Process (MDP). Compared with the state-of-the-art DRL-based dynamic pricing algorithms, our approaches make the following three contributions. First, we extend the discrete set problem to the continuous price set. Second, instead of using revenue as the reward function directly, we define a new function named difference of revenue conversion rates (DRCR). Third, the cold-start problem of MDP is tackled by pre-training and evaluation using some carefully chosen historical sales data. Our approaches are evaluated by both offline evaluation method using real dataset of Alibaba Inc., and online field experiments on Tmall.com, a major online shopping website owned by Alibaba Inc.. In particular, experiment results suggest that DRCR is a more appropriate reward function than revenue, which is widely used by current literature. In the end, field experiments, which last for months on 1000 stock keeping units (SKUs) of products demonstrate that continuous price sets have better performance than discrete sets and show that our approaches significantly outperformed the manual pricing by operation experts.