 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Accurate Person-level Action Recognition in Videos of Crowded Scenes
Oct 16, 2020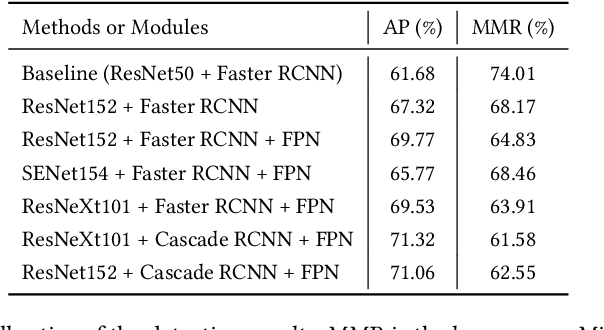
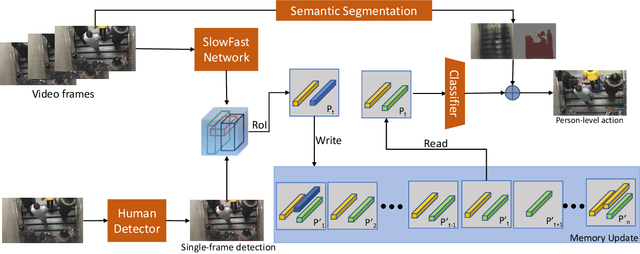
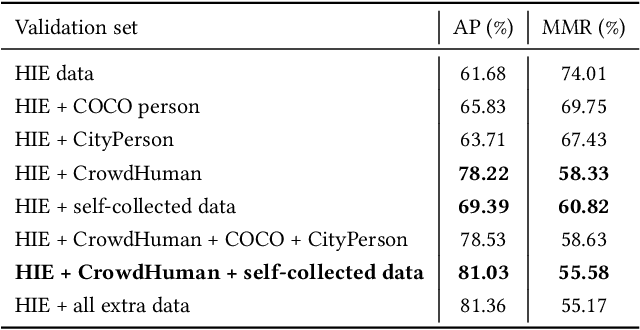

Detecting and recognizing human action in videos with crowded scenes is a challenging problem due to the complex environment and diversity events. Prior works always fail to deal with this problem in two aspects: (1) lacking utilizing information of the scenes; (2) lacking training data in the crowd and complex scenes. In this paper, we focus on improving spatio-temporal action recognition by fully-utilizing the information of scenes and collecting new data. A top-down strategy is used to overcome the limitations. Specifically, we adopt a strong human detector to detect the spatial location of each frame. We then apply action recognition models to learn the spatio-temporal information from video frames on both the HIE dataset and new data with diverse scenes from the internet, which can improve the generalization ability of our model. Besides, the scenes information is extracted by the semantic segmentation model to assistant the process. As a result, our method achieved an average 26.05 wf\_mAP (ranking 1st place in the ACM MM grand challenge 2020: Human in Events).
* 1'st Place in ACM Multimedia Grand Challenge: Human in Events, Track4: Person-level Action Recognition in Complex Events
A Deep-Learning-Based Fashion Attributes Detection Model
Oct 24, 2018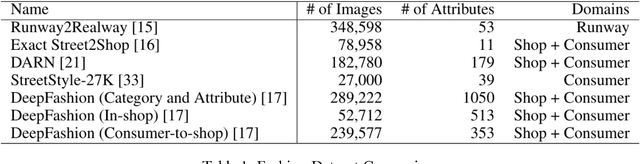
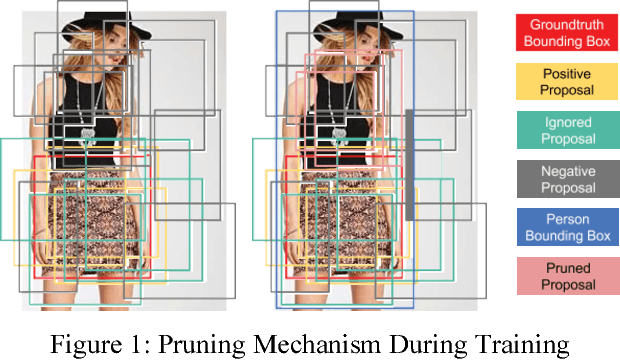
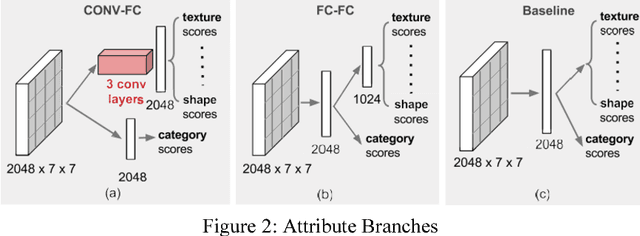
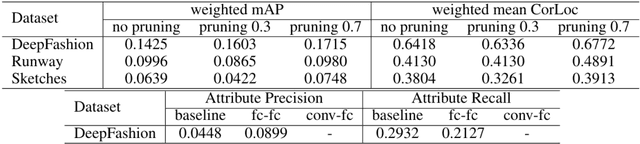
Analyzing fashion attributes is essential in the fashion design process. Current fashion forecasting firms, such as WGSN utilizes information from all around the world (from fashion shows, visual merchandising, blogs, etc). They gather information by experience, by observation, by media scan, by interviews, and by exposed to new things. Such information analyzing process is called abstracting, which recognize similarities or differences across all the garments and collections. In fact, such abstraction ability is useful in many fashion careers with different purposes. Fashion forecasters abstract across design collections and across time to identify fashion change and directions; designers, product developers and buyers abstract across a group of garments and collections to develop a cohesive and visually appeal lines; sales and marketing executives abstract across product line each season to recognize selling points; fashion journalist and bloggers abstract across runway photos to recognize symbolic core concepts that can be translated into editorial features. Fashion attributes analysis for such fashion insiders requires much detailed and in-depth attributes annotation than that for consumers, and requires inference on multiple domains. In this project, we propose a data-driven approach for recognizing fashion attributes. Specifically, a modified version of Faster R-CNN model is trained on images from a large-scale localization dataset with 594 fine-grained attributes under different scenarios, for example in online stores and street snapshots. This model will then be used to detect garment items and classify clothing attributes for runway photos and fashion illustrations.
Approximation Trees: Statistical Stability in Model Distillation
Aug 22, 2018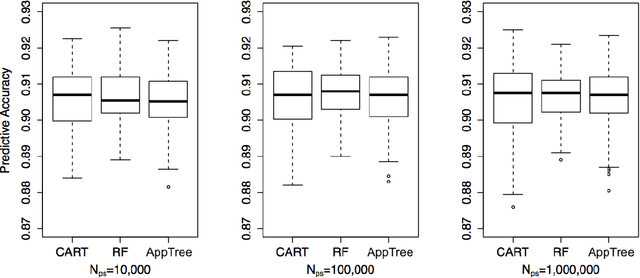
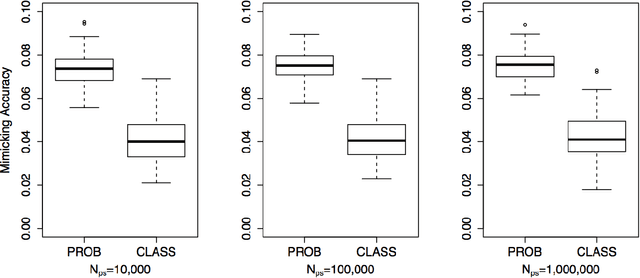
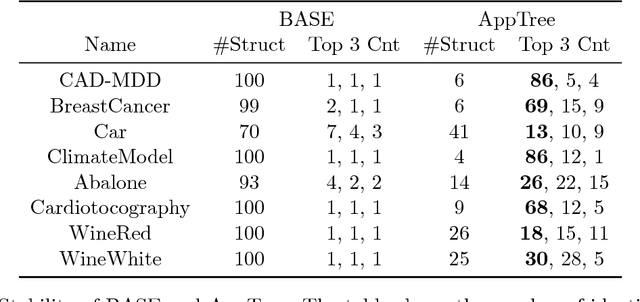
This paper examines the stability of learned explanations for black-box predictions via model distillation with decision trees. One approach to intelligibility in machine learning is to use an understandable `student' model to mimic the output of an accurate `teacher'. Here, we consider the use of regression trees as a student model, in which nodes of the tree can be used as `explanations' for particular predictions, and the whole structure of the tree can be used as a global representation of the resulting function. However, individual trees are sensitive to the particular data sets used to train them, and an interpretation of a student model may be suspect if small changes in the training data have a large effect on it. In this context, access to outcomes from a teacher helps to stabilize the greedy splitting strategy by generating a much larger corpus of training examples than was originally available. We develop tests to ensure that enough examples are generated at each split so that the same splitting rule would be chosen with high probability were the tree to be re trained. Further, we develop a stopping rule to indicate how deep the tree should be built based on recent results on the variability of Random Forests when these are used as the teacher. We provide concrete examples of these procedures on the CAD-MDD and COMPAS data sets.
Boulevard: Regularized Stochastic Gradient Boosted Trees and Their Limiting Distribution
Aug 15, 2018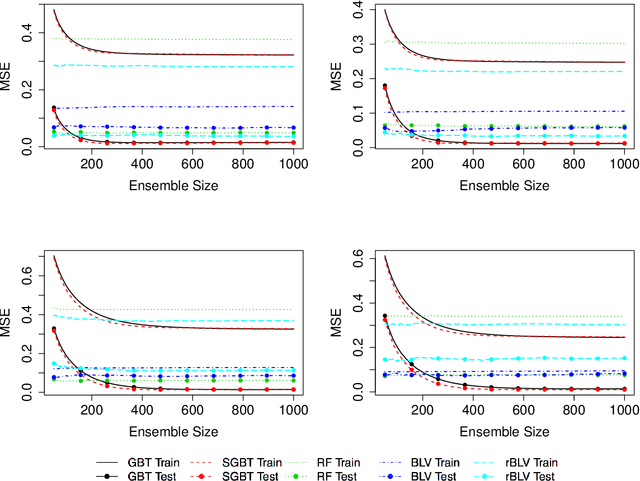
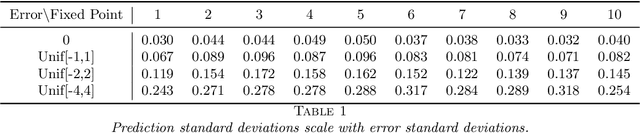
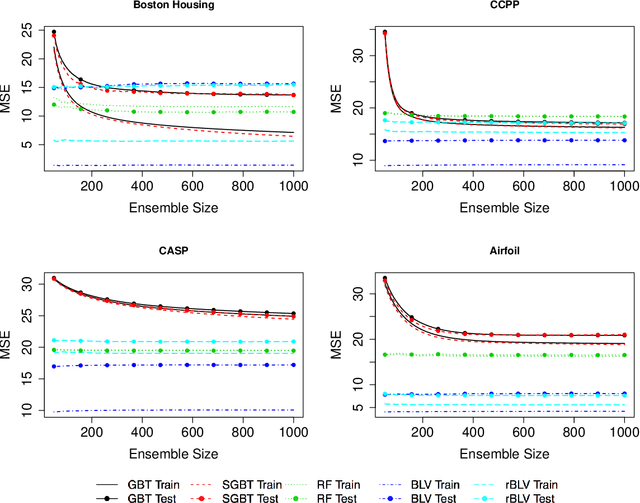
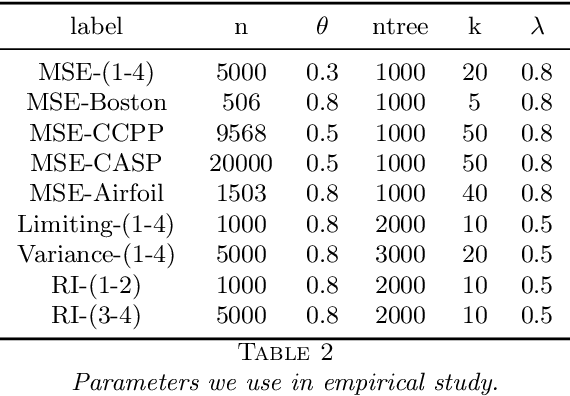
This paper examines a novel gradient boosting framework for regression. We regularize gradient boosted trees by introducing subsampling and employ a modified shrinkage algorithm so that at every boosting stage the estimate is given by an average of trees. The resulting algorithm, titled Boulevard, is shown to converge as the number of trees grows. We also demonstrate a central limit theorem for this limit, allowing a characterization of uncertainty for predictions. A simulation study and real world examples provide support for both the predictive accuracy of the model and its limiting behavior.
Multivariate Time Series Classification Using Dynamic Time Warping Template Selection for Human Activity Recognition
Dec 21, 2015
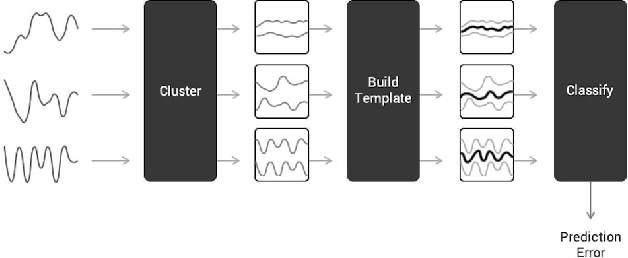
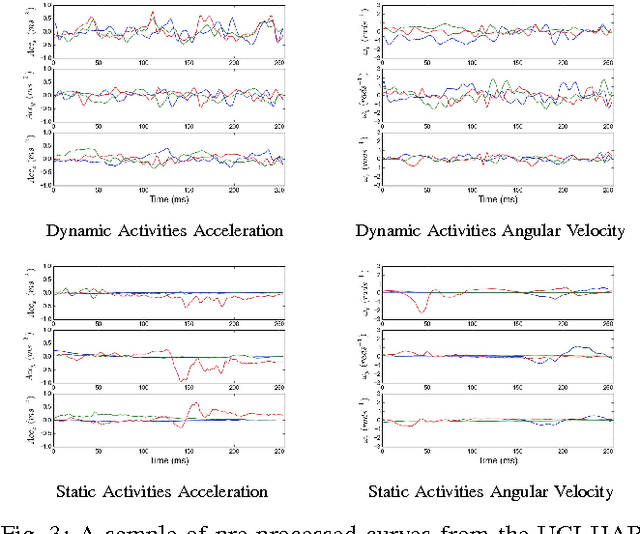
Accurate and computationally efficient means for classifying human activities have been the subject of extensive research efforts. Most current research focuses on extracting complex features to achieve high classification accuracy. We propose a template selection approach based on Dynamic Time Warping, such that complex feature extraction and domain knowledge is avoided. We demonstrate the predictive capability of the algorithm on both simulated and real smartphone data.