 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Sinkhorn Attention
Feb 26, 2020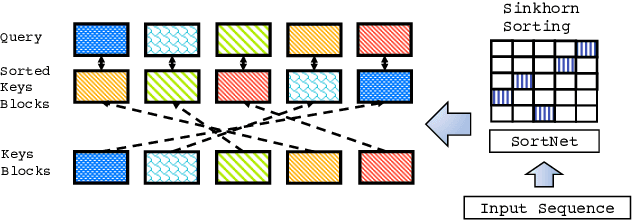
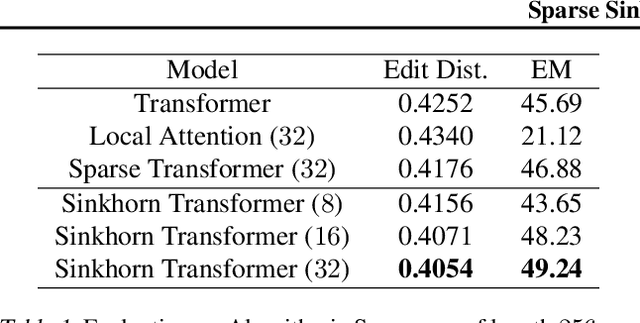
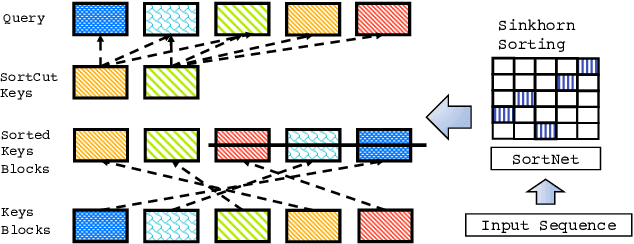
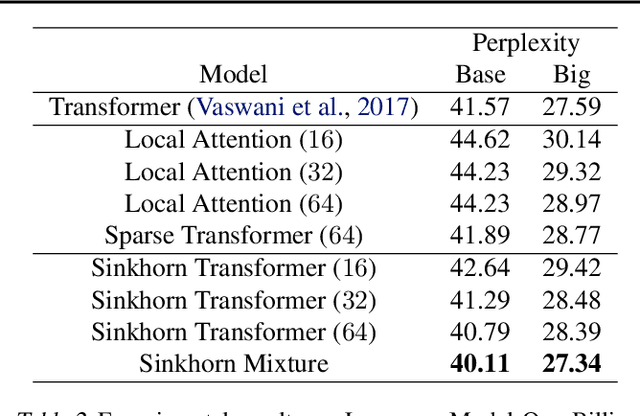
We propose Sparse Sinkhorn Attention, a new efficient and sparse method for learning to attend. Our method is based on differentiable sorting of internal representations. Concretely, we introduce a meta sorting network that learns to generate latent permutations over sequences. Given sorted sequences, we are then able to compute quasi-global attention with only local windows, improving the memory efficiency of the attention module. To this end, we propose new algorithmic innovations such as Causal Sinkhorn Balancing and SortCut, a dynamic sequence truncation method for tailoring Sinkhorn Attention for encoding and/or decoding purposes. Via extensive experiments on algorithmic seq2seq sorting, language modeling, pixel-wise image generation, document classification and natural language inference, we demonstrate that our memory efficient Sinkhorn Attention method is competitive with vanilla attention and consistently outperforms recently proposed efficient Transformer models such as Sparse Transformers.
Jacobian Adversarially Regularized Networks for Robustness
Jan 29, 2020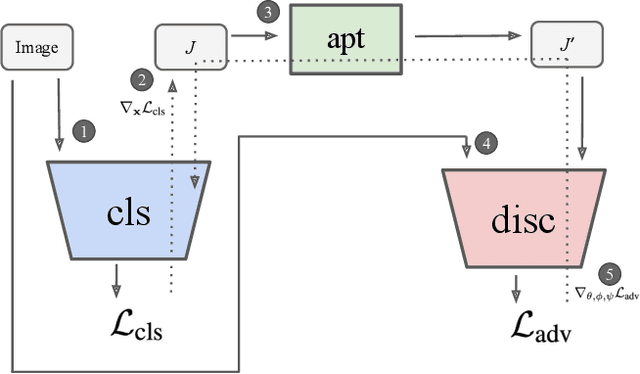
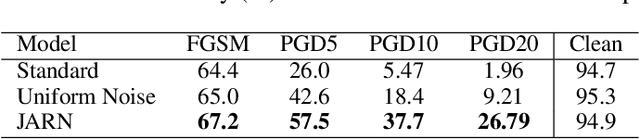
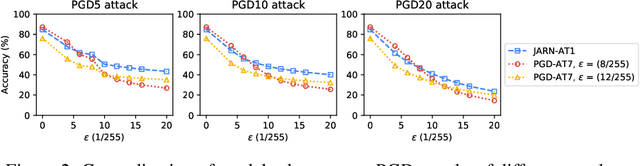
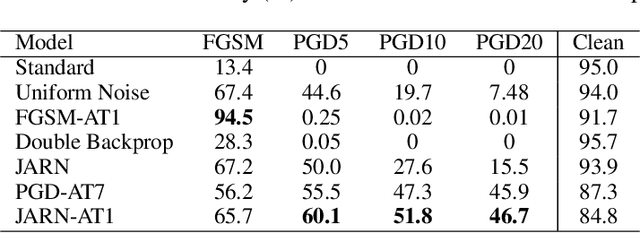
Adversarial examples are crafted with imperceptible perturbations with the intent to fool neural networks. Against such attacks, adversarial training and its variants stand as the strongest defense to date. Previous studies have pointed out that robust models that have undergone adversarial training tend to produce more salient and interpretable Jacobian matrices than their non-robust counterparts. A natural question is whether a model trained with an objective to produce salient Jacobian can result in better robustness. This paper answers this question with affirmative empirical results. We propose Jacobian Adversarially Regularized Networks (JARN) as a method to optimize the saliency of a classifier's Jacobian by adversarially regularizing the model's Jacobian to resemble natural training images. Image classifiers trained with JARN show improved robust accuracy compared to standard models on the MNIST, SVHN and CIFAR-10 datasets, uncovering a new angle to boost robustness without using adversarial training examples.
Multi-level Head-wise Match and Aggregation in Transformer for Textual Sequence Matching
Jan 20, 2020
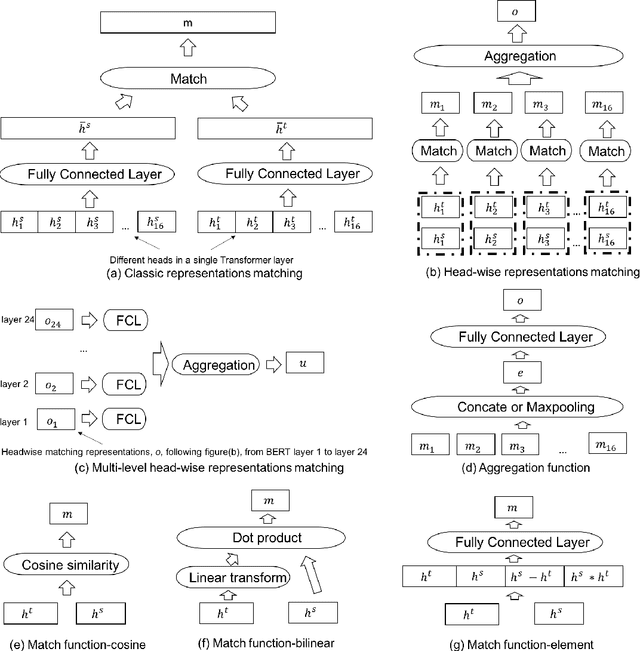
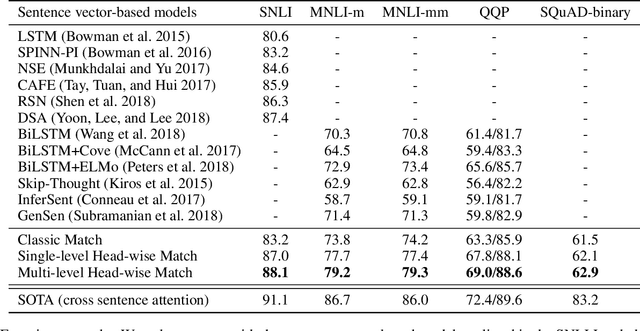
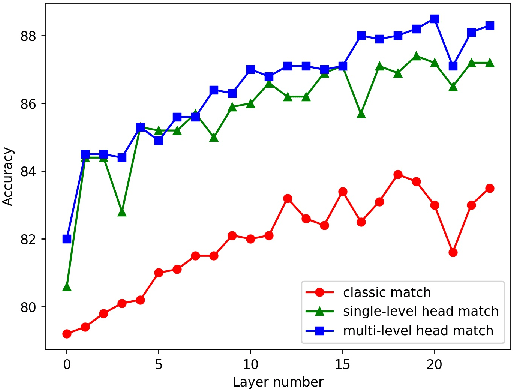
Transformer has been successfully applied to many natural language processing tasks. However, for textual sequence matching, simple matching between the representation of a pair of sequences might bring in unnecessary noise. In this paper, we propose a new approach to sequence pair matching with Transformer, by learning head-wise matching representations on multiple levels. Experiments show that our proposed approach can achieve new state-of-the-art performance on multiple tasks that rely only on pre-computed sequence-vector-representation, such as SNLI, MNLI-match, MNLI-mismatch, QQP, and SQuAD-binary.
What it Thinks is Important is Important: Robustness Transfers through Input Gradients
Dec 11, 2019
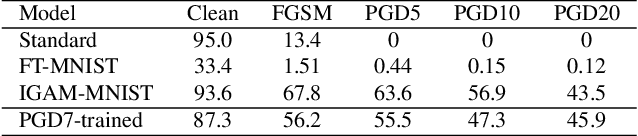
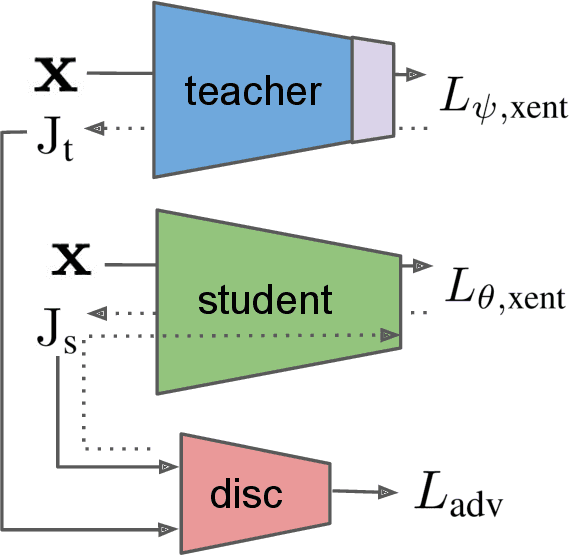
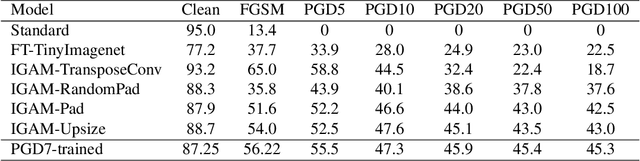
Adversarial perturbations are imperceptible changes to input pixels that can change the prediction of deep learning models. Learned weights of models robust to such perturbations are previously found to be transferable across different tasks but this applies only if the model architecture for the source and target tasks is the same. Input gradients characterize how small changes at each input pixel affect the model output. Using only natural images, we show here that training a student model's input gradients to match those of a robust teacher model can gain robustness close to a strong baseline that is robustly trained from scratch. Through experiments in MNIST, CIFAR-10, CIFAR-100 and Tiny-ImageNet, we show that our proposed method, input gradient adversarial matching, can transfer robustness across different tasks and even across different model architectures. This demonstrates that directly targeting the semantics of input gradients is a feasible way towards adversarial robustness.
Interactive Machine Comprehension with Information Seeking Agents
Sep 04, 2019
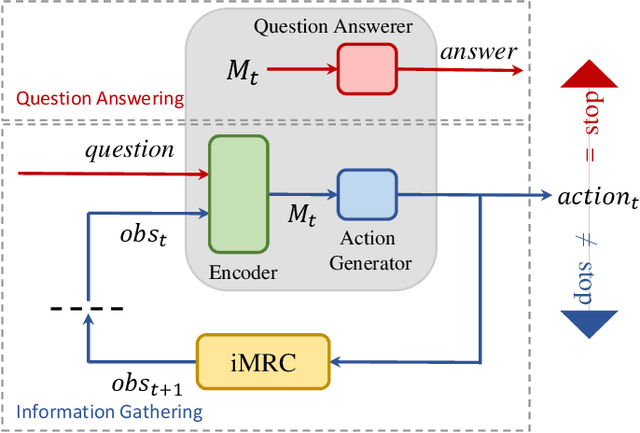
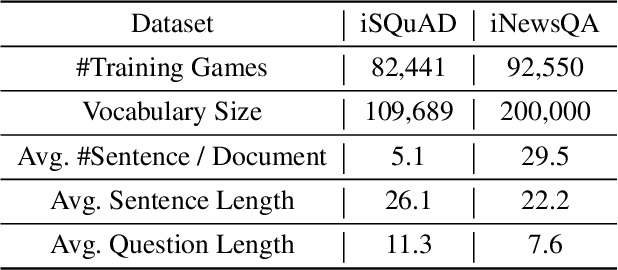
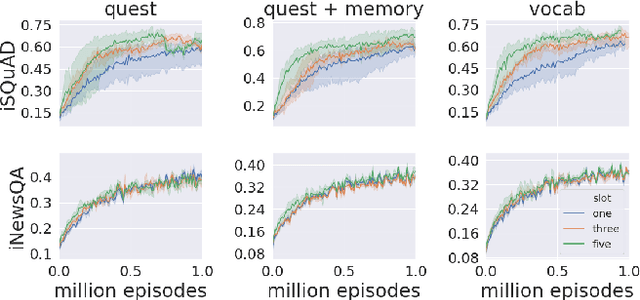
Existing machine reading comprehension (MRC) models do not scale effectively to real-world applications like web-level information retrieval and question answering (QA). We argue that this stems from the nature of MRC datasets: most of these are static environments wherein the supporting documents and all necessary information are fully observed. In this paper, we propose a simple method that reframes existing MRC datasets as interactive, partially observable environments. Specifically, we "occlude" the majority of a document's text and add context-sensitive commands that reveal "glimpses" of the hidden text to a model. We repurpose SQuAD and NewsQA as an initial case study, and then show how the interactive corpora can be used to train a model that seeks relevant information through sequential decision making. We believe that this setting can contribute in scaling models to web-level QA scenarios.
Lightweight and Efficient Neural Natural Language Processing with Quaternion Networks
Jun 11, 2019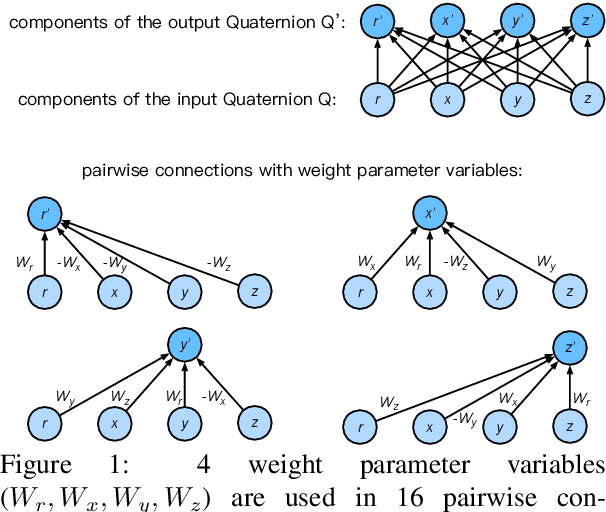



Many state-of-the-art neural models for NLP are heavily parameterized and thus memory inefficient. This paper proposes a series of lightweight and memory efficient neural architectures for a potpourri of natural language processing (NLP) tasks. To this end, our models exploit computation using Quaternion algebra and hypercomplex spaces, enabling not only expressive inter-component interactions but also significantly ($75\%$) reduced parameter size due to lesser degrees of freedom in the Hamilton product. We propose Quaternion variants of models, giving rise to new architectures such as the Quaternion attention Model and Quaternion Transformer. Extensive experiments on a battery of NLP tasks demonstrates the utility of proposed Quaternion-inspired models, enabling up to $75\%$ reduction in parameter size without significant loss in performance.
Quaternion Collaborative Filtering for Recommendation
Jun 06, 2019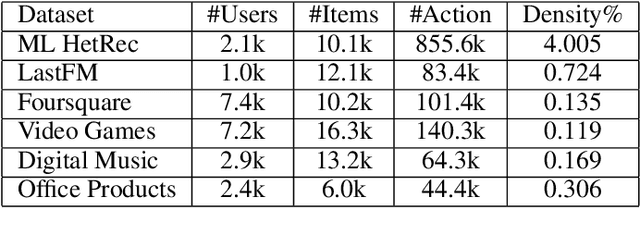
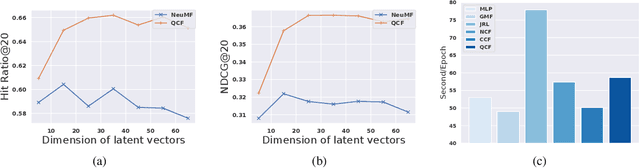
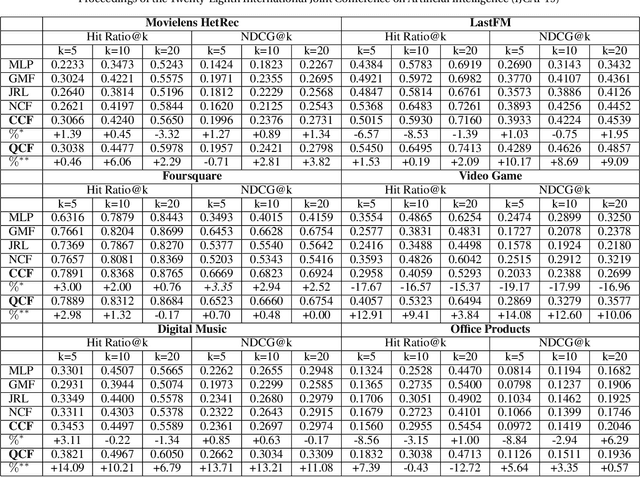
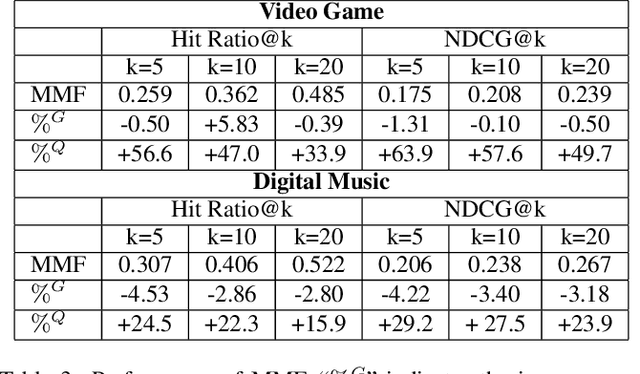
This paper proposes Quaternion Collaborative Filtering (QCF), a novel representation learning method for recommendation. Our proposed QCF relies on and exploits computation with Quaternion algebra, benefiting from the expressiveness and rich representation learning capability of Hamilton products. Quaternion representations, based on hypercomplex numbers, enable rich inter-latent dependencies between imaginary components. This encourages intricate relations to be captured when learning user-item interactions, serving as a strong inductive bias as compared with the real-space inner product. All in all, we conduct extensive experiments on six real-world datasets, demonstrating the effectiveness of Quaternion algebra in recommender systems. The results exhibit that QCF outperforms a wide spectrum of strong neural baselines on all datasets. Ablative experiments confirm the effectiveness of Hamilton-based composition over multi-embedding composition in real space.
Simple and Effective Curriculum Pointer-Generator Networks for Reading Comprehension over Long Narratives
May 26, 2019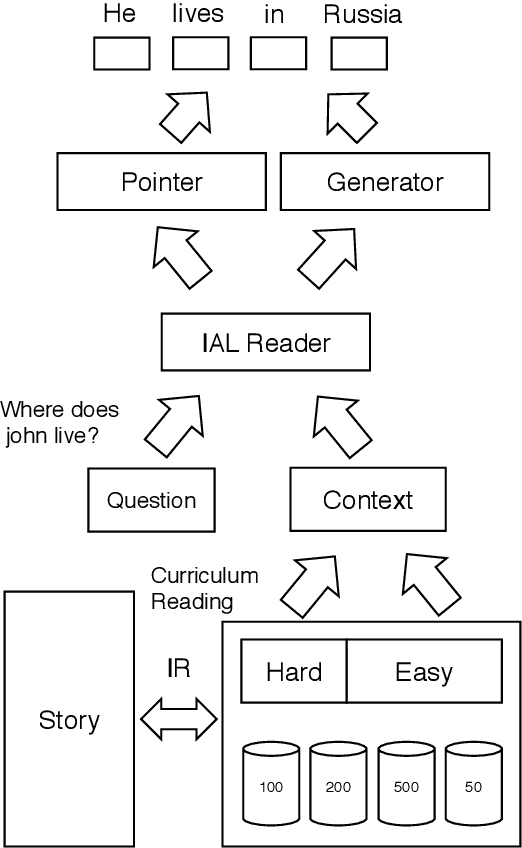
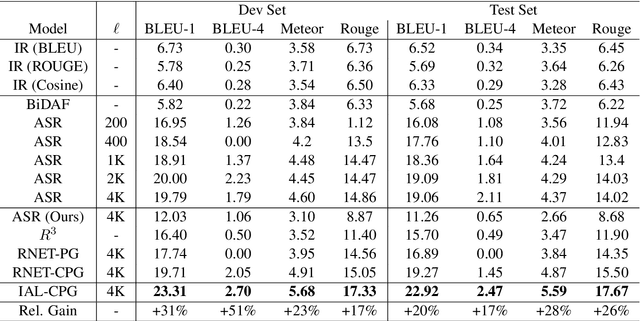
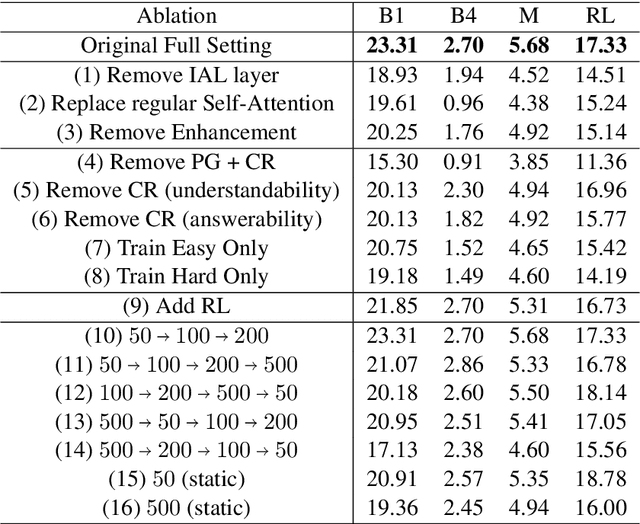

This paper tackles the problem of reading comprehension over long narratives where documents easily span over thousands of tokens. We propose a curriculum learning (CL) based Pointer-Generator framework for reading/sampling over large documents, enabling diverse training of the neural model based on the notion of alternating contextual difficulty. This can be interpreted as a form of domain randomization and/or generative pretraining during training. To this end, the usage of the Pointer-Generator softens the requirement of having the answer within the context, enabling us to construct diverse training samples for learning. Additionally, we propose a new Introspective Alignment Layer (IAL), which reasons over decomposed alignments using block-based self-attention. We evaluate our proposed method on the NarrativeQA reading comprehension benchmark, achieving state-of-the-art performance, improving existing baselines by $51\%$ relative improvement on BLEU-4 and $17\%$ relative improvement on Rouge-L. Extensive ablations confirm the effectiveness of our proposed IAL and CL components.
DeepRec: An Open-source Toolkit for Deep Learning based Recommendation
May 25, 2019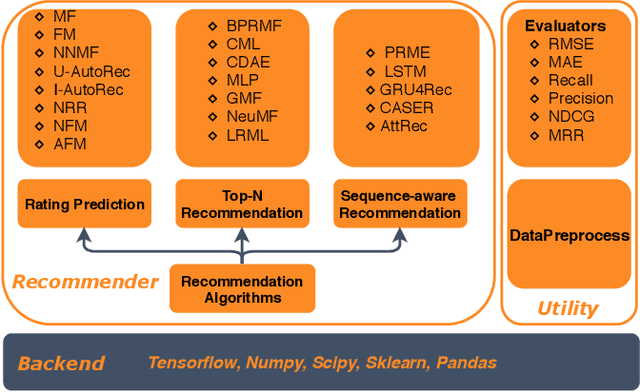
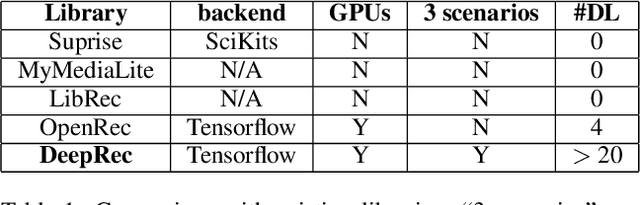
Deep learning based recommender systems have been extensively explored in recent years. However, the large number of models proposed each year poses a big challenge for both researchers and practitioners in reproducing the results for further comparisons. Although a portion of papers provides source code, they adopted different programming languages or different deep learning packages, which also raises the bar in grasping the ideas. To alleviate this problem, we released the open source project: \textbf{DeepRec}. In this toolkit, we have implemented a number of deep learning based recommendation algorithms using Python and the widely used deep learning package - Tensorflow. Three major recommendation scenarios: rating prediction, top-N recommendation (item ranking) and sequential recommendation, were considered. Meanwhile, DeepRec maintains good modularity and extensibility to easily incorporate new models into the framework. It is distributed under the terms of the GNU General Public License. The source code is available at github: \url{https://github.com/cheungdaven/DeepRec}
Quaternion Knowledge Graph Embedding
May 25, 2019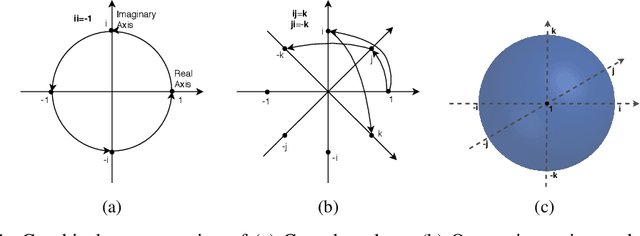


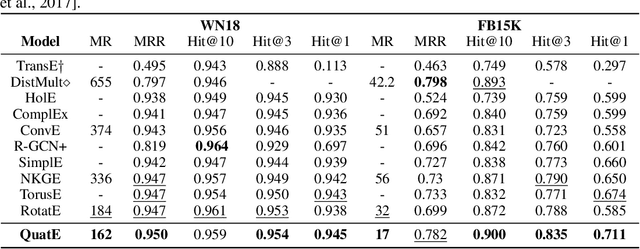
In this work, we move beyond the traditional complex-valued representations, introducing more expressive hypercomplex representations to model entities and relations for knowledge graph embeddings. More specifically, quaternion embeddings, hypercomplex-valued embeddings with three imaginary components, are utilized to represent entities. Relations are modelled as rotations in the quaternion space. The advantages of the proposed approach are: (1) Latent inter-dependencies (between all components) are aptly captured with Hamilton product, encouraging a more compact interaction between entities and relations; (2) Quaternions enable expressive rotation in four-dimensional space and have more degree of freedom than rotation in complex plane; (3) The proposed framework is a generalization of ComplEx on hypercomplex space while offering better geometrical interpretations, concurrently satisfying the key desiderata of relational representation learning (i.e., modeling symmetry, anti-symmetry and inversion). Experimental results demonstrate that our method achieves state-of-the-art performance on four well-established knowledge graph completion benchmarks.