 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively Parallel Universal Linear Transformations using a Wavelength-Multiplexed Diffractive Optical Network
Aug 13, 2022
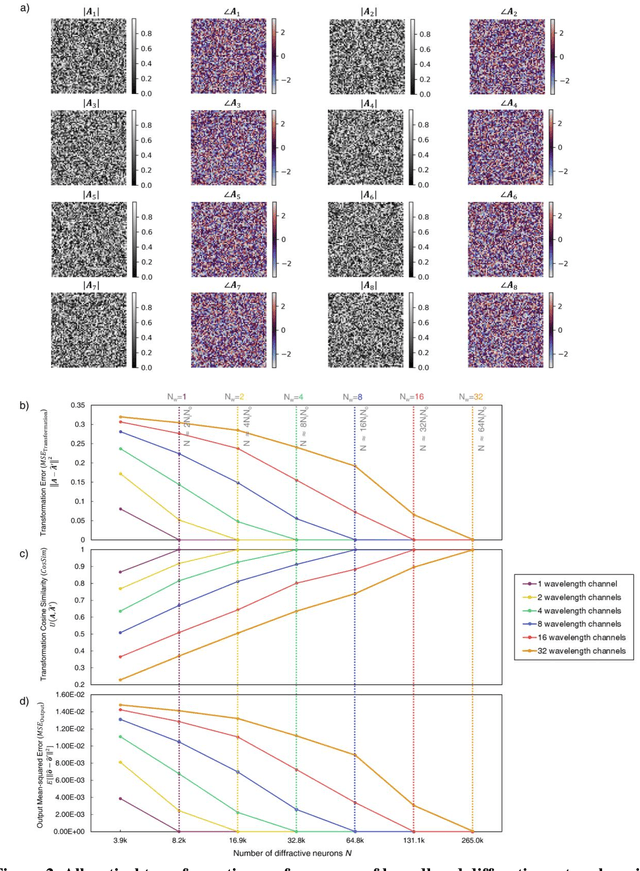
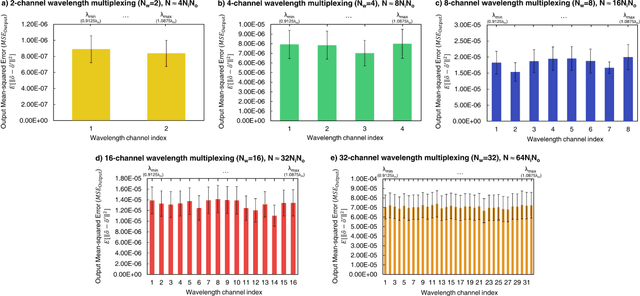
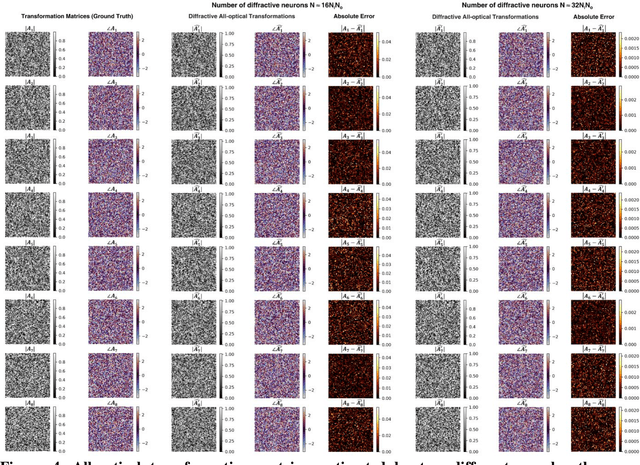
We report deep learning-based design of a massively parallel broadband diffractive neural network for all-optically performing a large group of arbitrarily-selected, complex-valued linear transformations between an input and output field-of-view, each with N_i and N_o pixels, respectively. This broadband diffractive processor is composed of N_w wavelength channels, each of which is uniquely assigned to a distinct target transformation. A large set of arbitrarily-selected linear transformations can be individually performed through the same diffractive network at different illumination wavelengths, either simultaneously or sequentially (wavelength scanning). We demonstrate that such a broadband diffractive network, regardless of its material dispersion, can successfully approximate N_w unique complex-valued linear transforms with a negligible error when the number of diffractive neurons (N) in its design matches or exceeds 2 x N_w x N_i x N_o. We further report that the spectral multiplexing capability (N_w) can be increased by increasing N; our numerical analyses confirm these conclusions for N_w > 180, which can be further increased to e.g., ~2000 depending on the upper bound of the approximation error. Massively parallel, wavelength-multiplexed diffractive networks will be useful for designing high-throughput intelligent machine vision systems and hyperspectral processors that can perform statistical inference and analyze objects/scenes with unique spectral properties.
FRA-RIR: Fast Random Approximation of the Image-source Method
Aug 08, 2022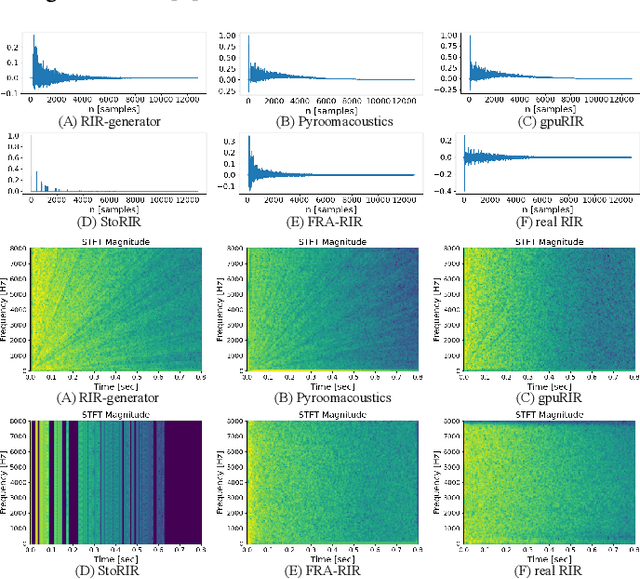
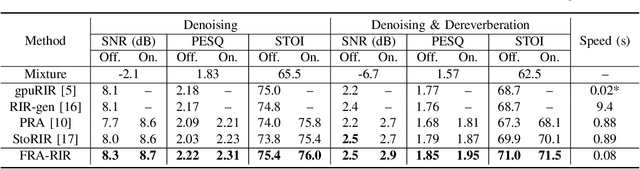
The training of modern speech processing systems often requires a large amount of simulated room impulse response (RIR) data in order to allow the systems to generalize well in real-world, reverberant environments. However, simulating realistic RIR data typically requires accurate physical modeling, and the acceleration of such simulation process typically requires certain computational platforms such as a graphics processing unit (GPU). In this paper, we propose FRA-RIR, a fast random approximation method of the widely-used image-source method (ISM), to efficiently generate realistic RIR data without specific computational devices. FRA-RIR replaces the physical simulation in the standard ISM by a series of random approximations, which significantly speeds up the simulation process and enables its application in on-the-fly data generation pipelines. Experiments show that FRA-RIR can not only be significantly faster than other existing ISM-based RIR simulation tools on standard computational platforms, but also improves the performance of speech denoising systems evaluated on real-world RIR when trained with simulated RIR. A Python implementation of FRA-RIR is available online\footnote{\url{https://github.com/yluo42/FRA-RIR}}.
All-optical image classification through unknown random diffusers using a single-pixel diffractive network
Aug 08, 2022Classification of an object behind a random and unknown scattering medium sets a challenging task for computational imaging and machine vision fields. Recent deep learning-based approaches demonstrated the classification of objects using diffuser-distorted patterns collected by an image sensor. These methods demand relatively large-scale computing using deep neural networks running on digital computers. Here, we present an all-optical processor to directly classify unknown objects through unknown, random phase diffusers using broadband illumination detected with a single pixel. A set of transmissive diffractive layers, optimized using deep learning, forms a physical network that all-optically maps the spatial information of an input object behind a random diffuser into the power spectrum of the output light detected through a single pixel at the output plane of the diffractive network. We numerically demonstrated the accuracy of this framework using broadband radiation to classify unknown handwritten digits through random new diffusers, never used during the training phase, and achieved a blind testing accuracy of 88.53%. This single-pixel all-optical object classification system through random diffusers is based on passive diffractive layers that process broadband input light and can operate at any part of the electromagnetic spectrum by simply scaling the diffractive features proportional to the wavelength range of interest. These results have various potential applications in, e.g., biomedical imaging, security, robotics, and autonomous driving.
On the Use of Deep Mask Estimation Module for Neural Source Separation Systems
Jun 15, 2022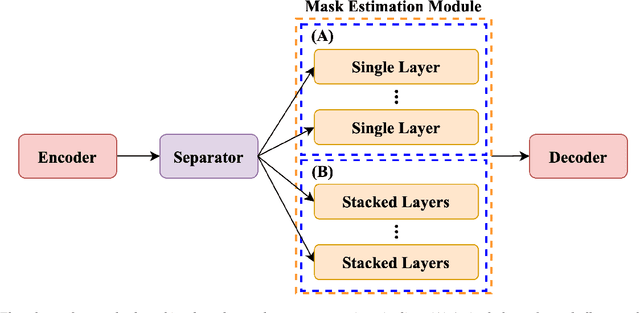
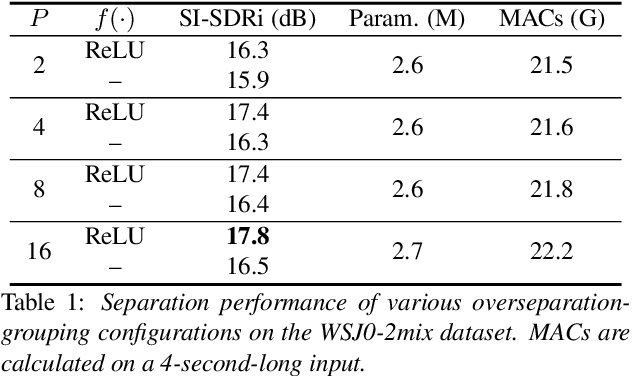
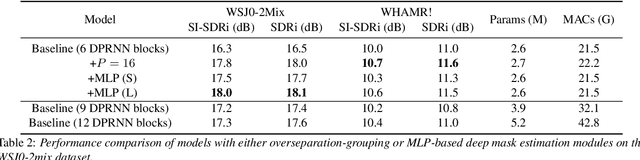

Most of the recent neural source separation systems rely on a masking-based pipeline where a set of multiplicative masks are estimated from and applied to a signal representation of the input mixture. The estimation of such masks, in almost all network architectures, is done by a single layer followed by an optional nonlinear activation function. However, recent literatures have investigated the use of a deep mask estimation module and observed performance improvement compared to a shallow mask estimation module. In this paper, we analyze the role of such deeper mask estimation module by connecting it to a recently proposed unsupervised source separation method, and empirically show that the deep mask estimation module is an efficient approximation of the so-called overseparation-grouping paradigm with the conventional shallow mask estimation layers.
On the Design and Training Strategies for RNN-based Online Neural Speech Separation Systems
Jun 15, 2022
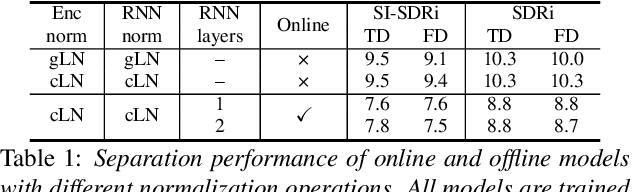
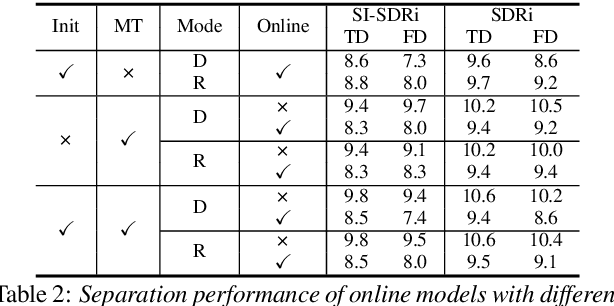
While the performance of offline neural speech separation systems has been greatly advanced by the recent development of novel neural network architectures, there is typically an inevitable performance gap between the systems and their online variants. In this paper, we investigate how RNN-based offline neural speech separation systems can be changed into their online counterparts while mitigating the performance degradation. We decompose or reorganize the forward and backward RNN layers in a bidirectional RNN layer to form an online path and an offline path, which enables the model to perform both online and offline processing with a same set of model parameters. We further introduce two training strategies for improving the online model via either a pretrained offline model or a multitask training objective. Experiment results show that compared to the online models that are trained from scratch, the proposed layer decomposition and reorganization schemes and training strategies can effectively mitigate the performance gap between two RNN-based offline separation models and their online variants.
Super-resolution image display using diffractive decoders
Jun 15, 2022
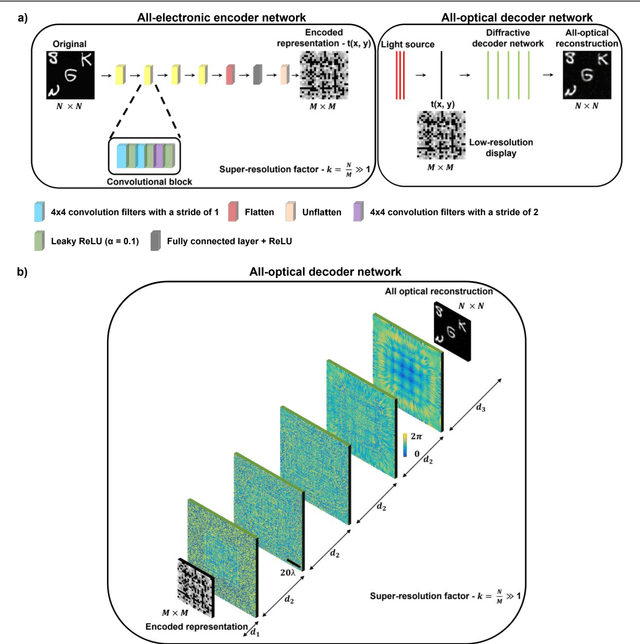
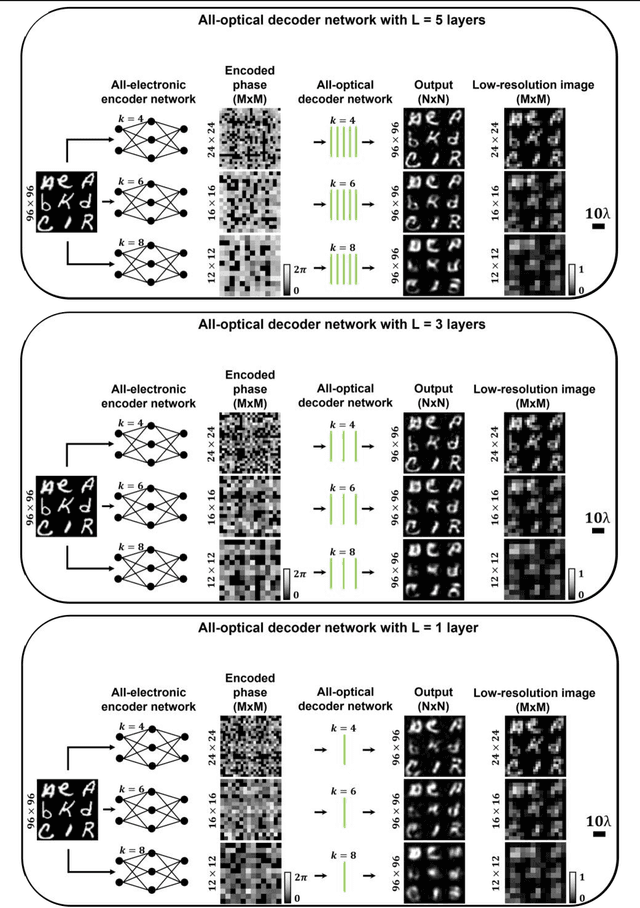
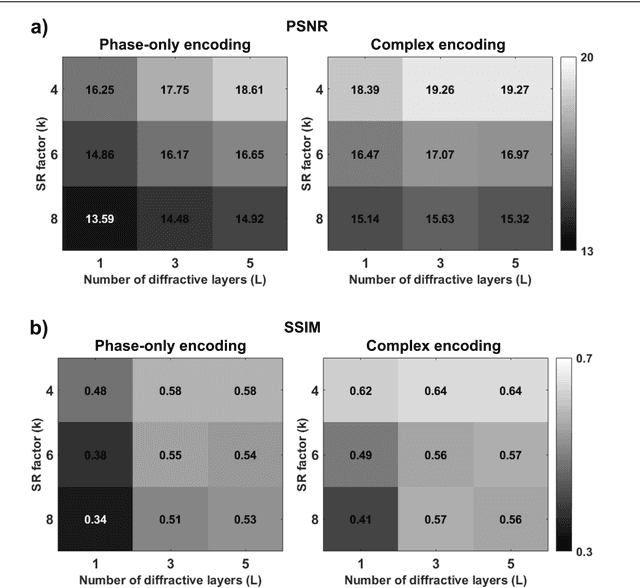
High-resolution synthesis/projection of images over a large field-of-view (FOV) is hindered by the restricted space-bandwidth-product (SBP) of wavefront modulators. We report a deep learning-enabled diffractive display design that is based on a jointly-trained pair of an electronic encoder and a diffractive optical decoder to synthesize/project super-resolved images using low-resolution wavefront modulators. The digital encoder, composed of a trained convolutional neural network (CNN), rapidly pre-processes the high-resolution images of interest so that their spatial information is encoded into low-resolution (LR) modulation patterns, projected via a low SBP wavefront modulator. The diffractive decoder processes this LR encoded information using thin transmissive layers that are structured using deep learning to all-optically synthesize and project super-resolved images at its output FOV. Our results indicate that this diffractive image display can achieve a super-resolution factor of ~4, demonstrating a ~16-fold increase in SBP. We also experimentally validate the success of this diffractive super-resolution display using 3D-printed diffractive decoders that operate at the THz spectrum. This diffractive image decoder can be scaled to operate at visible wavelengths and inspire the design of large FOV and high-resolution displays that are compact, low-power, and computationally efficient.
To image, or not to image: Class-specific diffractive cameras with all-optical erasure of undesired objects
May 26, 2022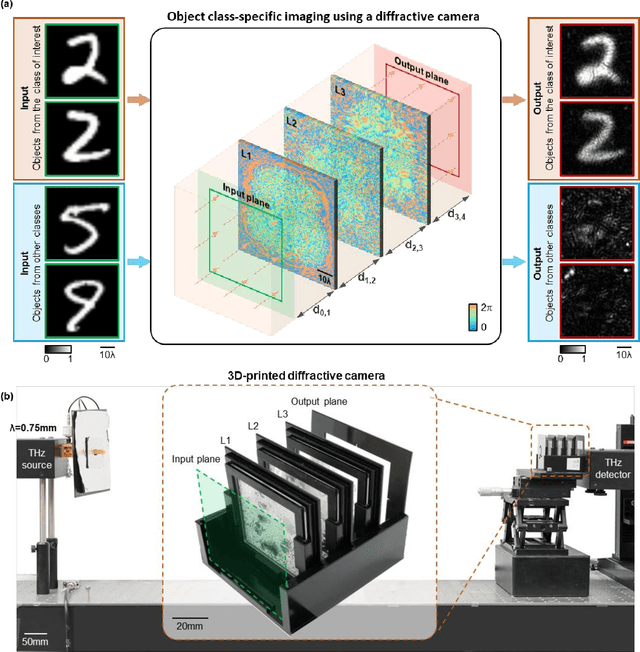
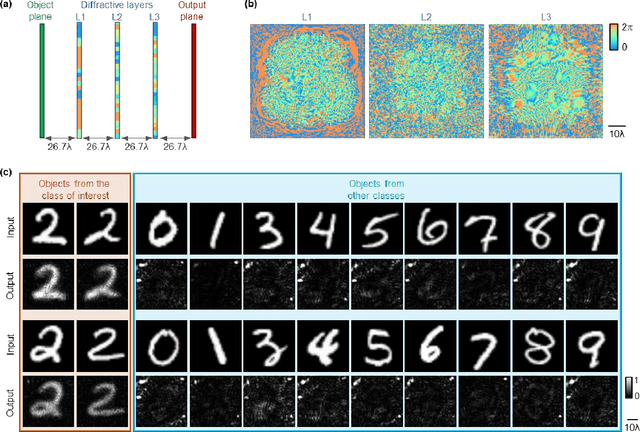
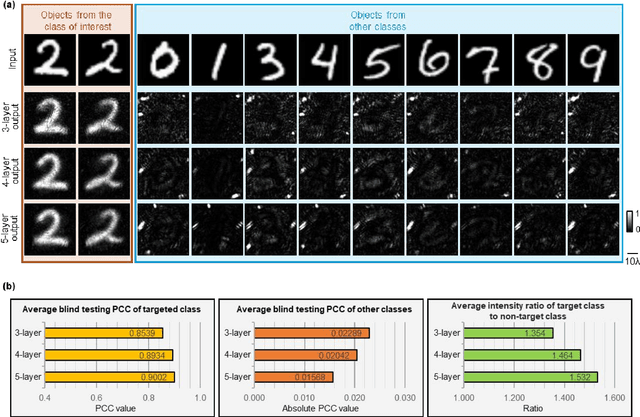
Privacy protection is a growing concern in the digital era, with machine vision techniques widely used throughout public and private settings. Existing methods address this growing problem by, e.g., encrypting camera images or obscuring/blurring the imaged information through digital algorithms. Here, we demonstrate a camera design that performs class-specific imaging of target objects with instantaneous all-optical erasure of other classes of objects. This diffractive camera consists of transmissive surfaces structured using deep learning to perform selective imaging of target classes of objects positioned at its input field-of-view. After their fabrication, the thin diffractive layers collectively perform optical mode filtering to accurately form images of the objects that belong to a target data class or group of classes, while instantaneously erasing objects of the other data classes at the output field-of-view. Using the same framework, we also demonstrate the design of class-specific permutation cameras, where the objects of a target data class are pixel-wise permuted for all-optical class-specific encryption, while the other objects are irreversibly erased from the output image. The success of class-specific diffractive cameras was experimentally demonstrated using terahertz (THz) waves and 3D-printed diffractive layers that selectively imaged only one class of the MNIST handwritten digit dataset, all-optically erasing the other handwritten digits. This diffractive camera design can be scaled to different parts of the electromagnetic spectrum, including, e.g., the visible and infrared wavelengths, to provide transformative opportunities for privacy-preserving digital cameras and task-specific data-efficient imaging.
Analysis of Diffractive Neural Networks for Seeing Through Random Diffusers
May 01, 2022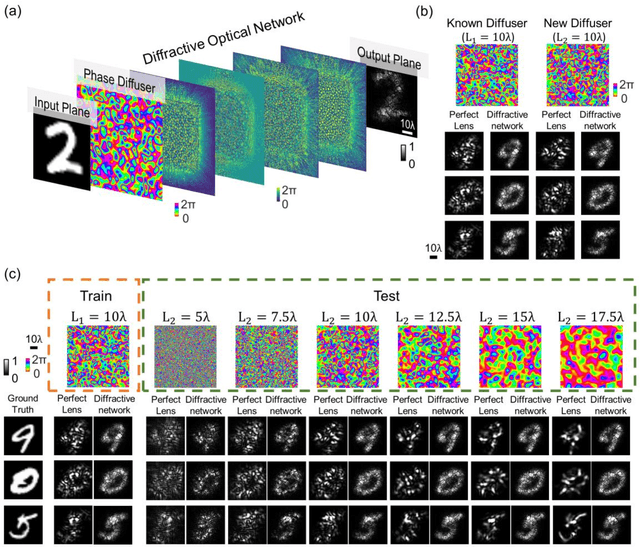
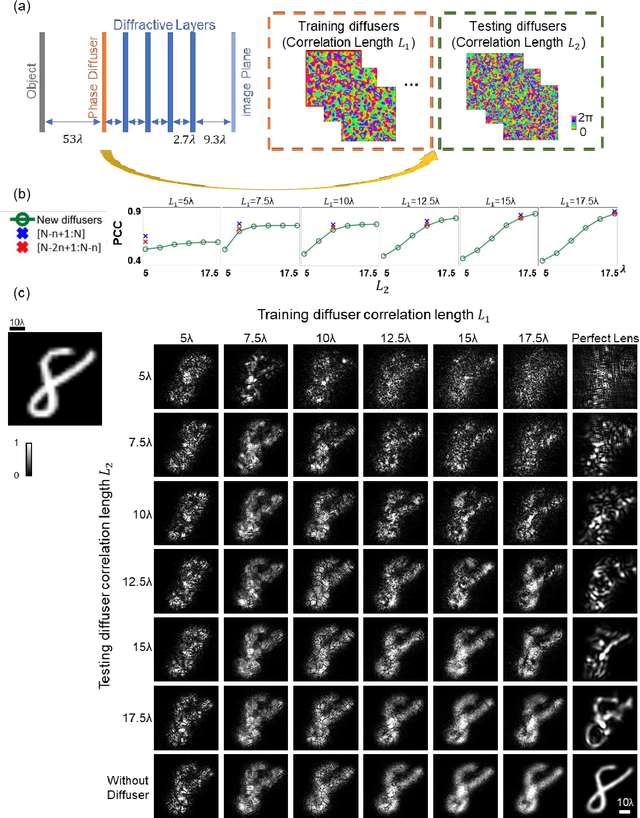
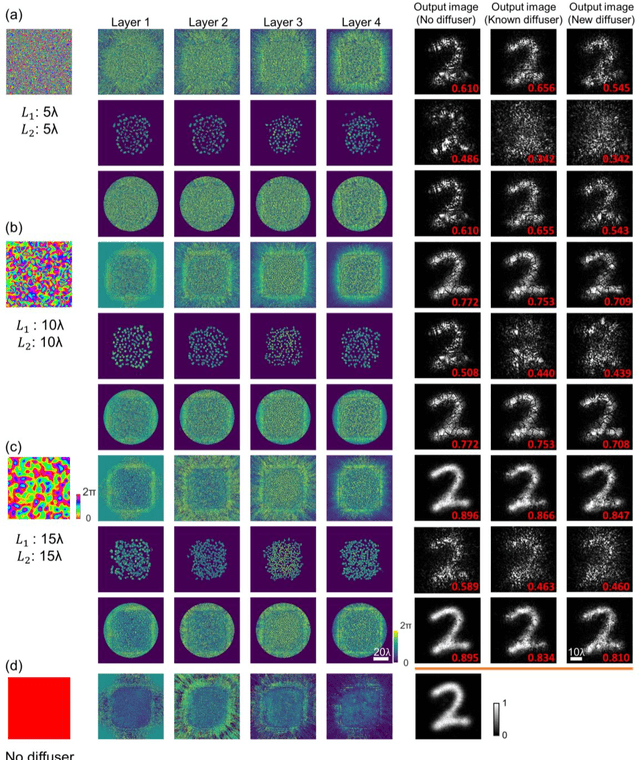
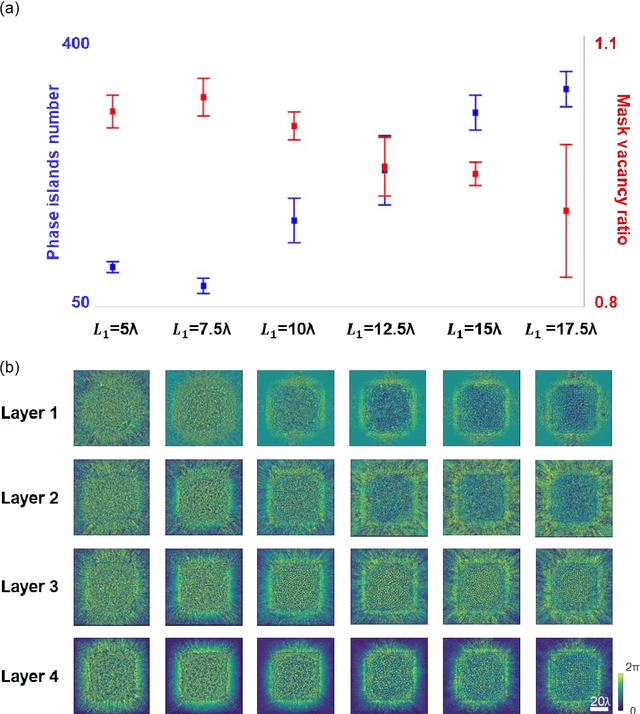
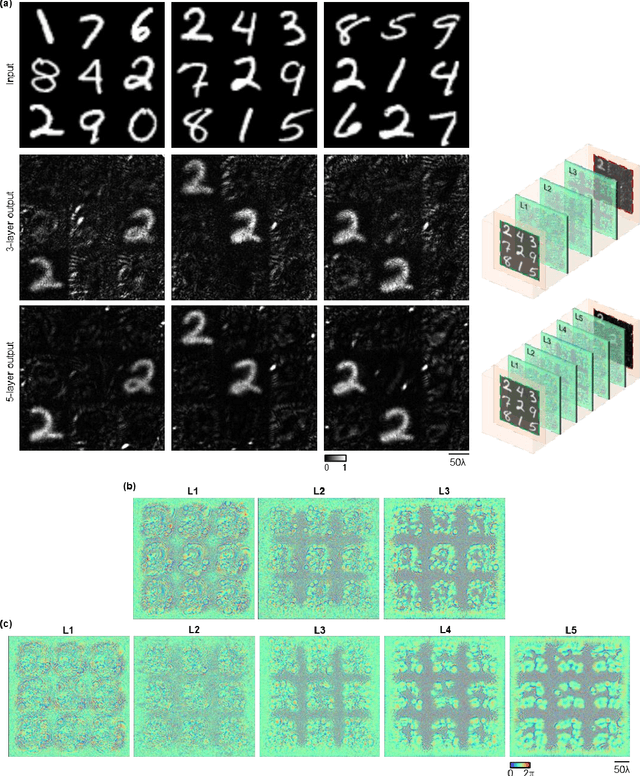
Imaging through diffusive media is a challenging problem, where the existing solutions heavily rely on digital computers to reconstruct distorted images. We provide a detailed analysis of a computer-free, all-optical imaging method for seeing through random, unknown phase diffusers using diffractive neural networks, covering different deep learning-based training strategies. By analyzing various diffractive networks designed to image through random diffusers with different correlation lengths, a trade-off between the image reconstruction fidelity and distortion reduction capability of the diffractive network was observed. During its training, random diffusers with a range of correlation lengths were used to improve the diffractive network's generalization performance. Increasing the number of random diffusers used in each epoch reduced the overfitting of the diffractive network's imaging performance to known diffusers. We also demonstrated that the use of additional diffractive layers improved the generalization capability to see through new, random diffusers. Finally, we introduced deliberate misalignments in training to 'vaccinate' the network against random layer-to-layer shifts that might arise due to the imperfect assembly of the diffractive networks. These analyses provide a comprehensive guide in designing diffractive networks to see through random diffusers, which might profoundly impact many fields, such as biomedical imaging, atmospheric physics, and autonomous driving.
Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization
Mar 23, 2022
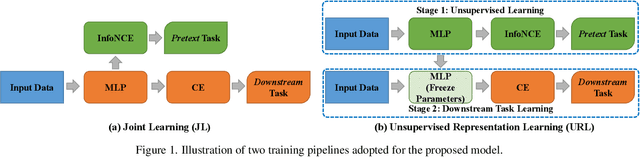
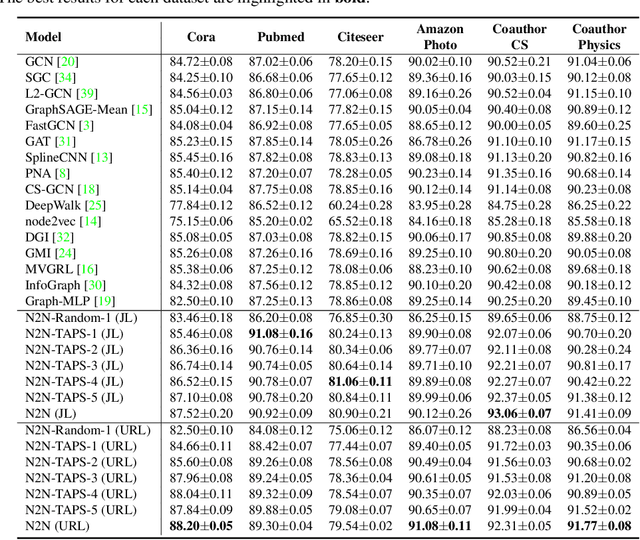
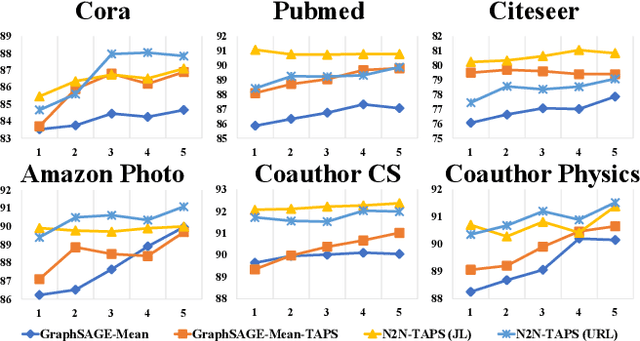
The key towards learning informative node representations in graphs lies in how to gain contextual information from the neighbourhood. In this work, we present a simple-yet-effective self-supervised node representation learning strategy via directly maximizing the mutual information between the hidden representations of nodes and their neighbourhood, which can be theoretically justified by its link to graph smoothing. Following InfoNCE, our framework is optimized via a surrogate contrastive loss, where the positive selection underpins the quality and efficiency of representation learning. To this end, we propose a topology-aware positive sampling strategy, which samples positives from the neighbourhood by considering the structural dependencies between nodes and thus enables positive selection upfront. In the extreme case when only one positive is sampled, we fully avoid expensive neighbourhood aggregation. Our methods achieve promising performance on various node classification datasets. It is also worth mentioning by applying our loss function to MLP based node encoders, our methods can be orders of faster than existing solutions. Our codes and supplementary materials are available at https://github.com/dongwei156/n2n.
A Time-domain Generalized Wiener Filter for Multi-channel Speech Separation
Dec 07, 2021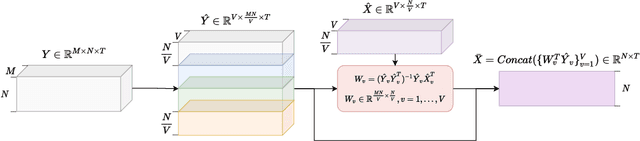
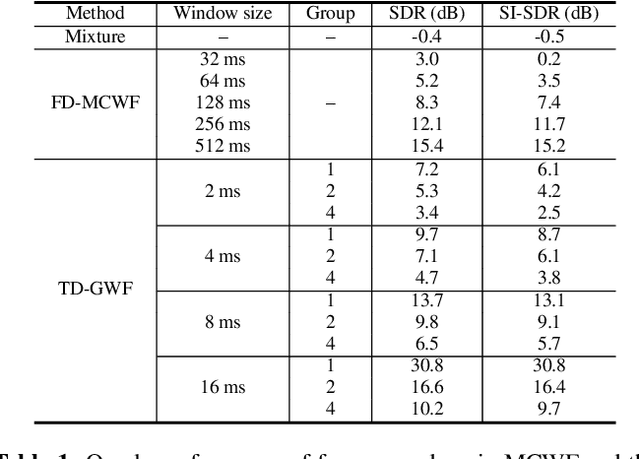
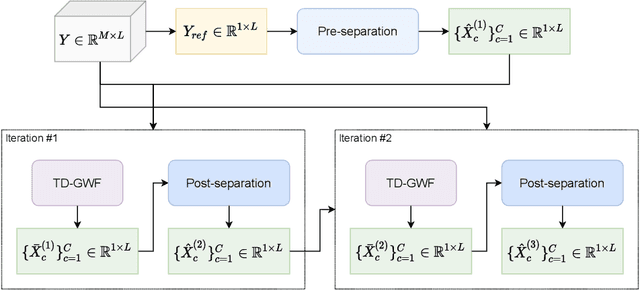

Frequency-domain neural beamformers are the mainstream methods for recent multi-channel speech separation models. Despite their well-defined behaviors and the effectiveness, such frequency-domain beamformers still have the limitations of a bounded oracle performance and the difficulties of designing proper networks for the complex-valued operations. In this paper, we propose a time-domain generalized Wiener filter (TD-GWF), an extension to the conventional frequency-domain beamformers that has higher oracle performance and only involves real-valued operations. We also provide discussions on how TD-GWF can be connected to conventional frequency-domain beamformers. Experiment results show that a significant performance improvement can be achieved by replacing frequency-domain beamformers by the TD-GWF in the recently proposed sequential neural beamforming pipelines.