 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflecting with Two Voices: A Co-Adaptive Dual-Strategy Framework for LLM-Based Agent Decision Making
Dec 09, 2025Large language model (LLM) agents often rely on external demonstrations or retrieval-augmented planning, leading to brittleness, poor generalization, and high computational overhead. Inspired by human problem-solving, we propose DuSAR (Dual-Strategy Agent with Reflecting) - a demonstration-free framework that enables a single frozen LLM to perform co-adaptive reasoning via two complementary strategies: a high-level holistic plan and a context-grounded local policy. These strategies interact through a lightweight reflection mechanism, where the agent continuously assesses progress via a Strategy Fitness Score and dynamically revises its global plan when stuck or refines it upon meaningful advancement, mimicking human metacognitive behavior. On ALFWorld and Mind2Web, DuSAR achieves state-of-the-art performance with open-source LLMs (7B-70B), reaching 37.1% success on ALFWorld (Llama3.1-70B) - more than doubling the best prior result (13.0%) - and 4.02% on Mind2Web, also more than doubling the strongest baseline. Remarkably, it reduces per-step token consumption by 3-9X while maintaining strong performance. Ablation studies confirm the necessity of dual-strategy coordination. Moreover, optional integration of expert demonstrations further boosts results, highlighting DuSAR's flexibility and compatibility with external knowledge.
Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization
Mar 23, 2022
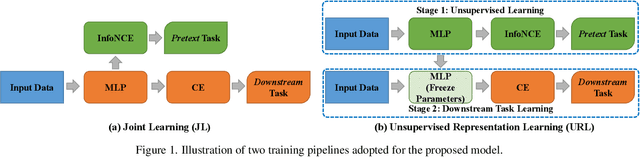
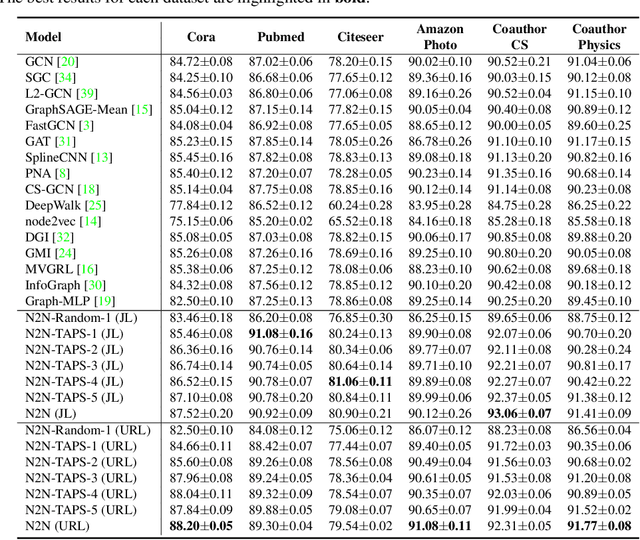
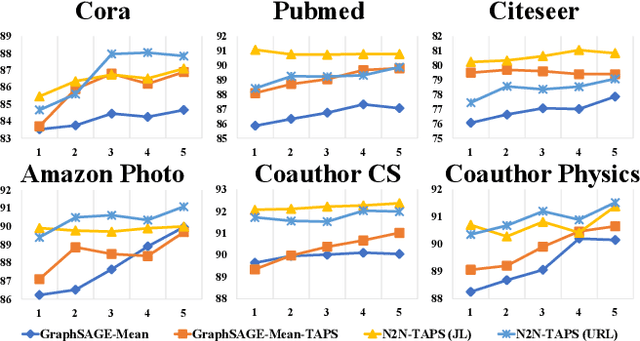
The key towards learning informative node representations in graphs lies in how to gain contextual information from the neighbourhood. In this work, we present a simple-yet-effective self-supervised node representation learning strategy via directly maximizing the mutual information between the hidden representations of nodes and their neighbourhood, which can be theoretically justified by its link to graph smoothing. Following InfoNCE, our framework is optimized via a surrogate contrastive loss, where the positive selection underpins the quality and efficiency of representation learning. To this end, we propose a topology-aware positive sampling strategy, which samples positives from the neighbourhood by considering the structural dependencies between nodes and thus enables positive selection upfront. In the extreme case when only one positive is sampled, we fully avoid expensive neighbourhood aggregation. Our methods achieve promising performance on various node classification datasets. It is also worth mentioning by applying our loss function to MLP based node encoders, our methods can be orders of faster than existing solutions. Our codes and supplementary materials are available at https://github.com/dongwei156/n2n.