 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Total Capture: Posing Face, Body, and Hands in the Wild
Dec 04, 2018

We present the first method to capture the 3D total motion of a target person from a monocular view input. Given an image or a monocular video, our method reconstructs the motion from body, face, and fingers represented by a 3D deformable mesh model. We use an efficient representation called 3D Part Orientation Fields (POFs), to encode the 3D orientations of all body parts in the common 2D image space. POFs are predicted by a Fully Convolutional Network (FCN), along with the joint confidence maps. To train our network, we collect a new 3D human motion dataset capturing diverse total body motion of 40 subjects in a multiview system. We leverage a 3D deformable human model to reconstruct total body pose from the CNN outputs by exploiting the pose and shape prior in the model. We also present a texture-based tracking method to obtain temporally coherent motion capture output. We perform thorough quantitative evaluations including comparison with the existing body-specific and hand-specific methods, and performance analysis on camera viewpoint and human pose changes. Finally, we demonstrate the results of our total body motion capture on various challenging in-the-wild videos. Our code and newly collected human motion dataset will be publicly shared.
Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields
Nov 29, 2018

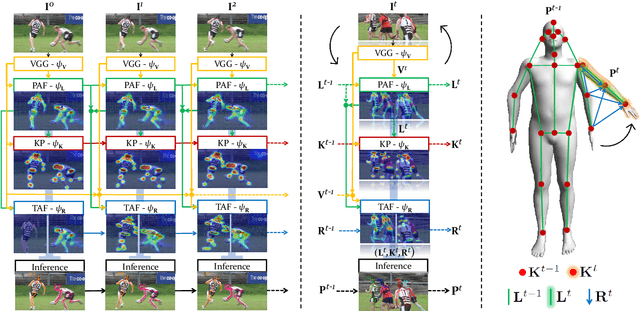
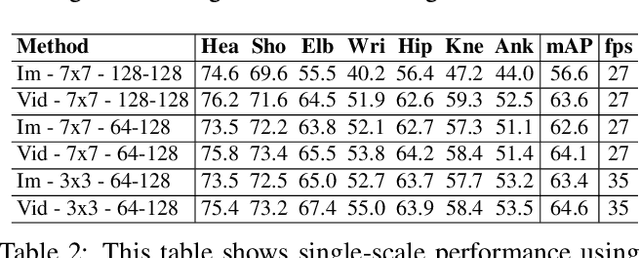
We present an online approach to efficiently and simultaneously detect and track the 2D pose of multiple people in a video sequence. We build upon Part Affinity Field (PAF) representation designed for static images, and propose an architecture that can encode and predict Spatio-Temporal Affinity Fields (STAF) across a video sequence. In particular, we propose a novel temporal topology cross-linked across limbs which can consistently handle body motions of a wide range of magnitudes. Additionally, we make the overall approach recurrent in nature, where the network ingests STAF heatmaps from previous frames and estimates those for the current frame. Our approach uses only online inference and tracking, and is currently the fastest and the most accurate bottom-up approach that is runtime invariant to the number of people in the scene and accuracy invariant to input frame rate of camera. Running at $\sim$30 fps on a single GPU at single scale, it achieves highly competitive results on the PoseTrack benchmarks.
Recycle-GAN: Unsupervised Video Retargeting
Aug 15, 2018
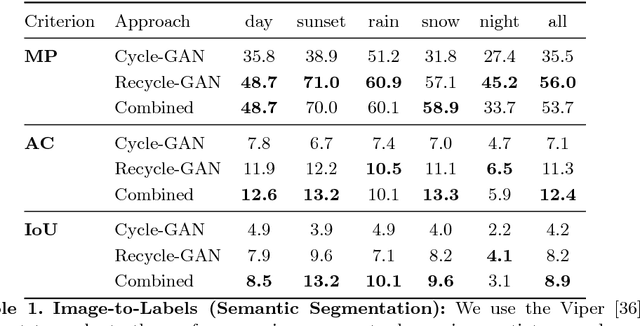
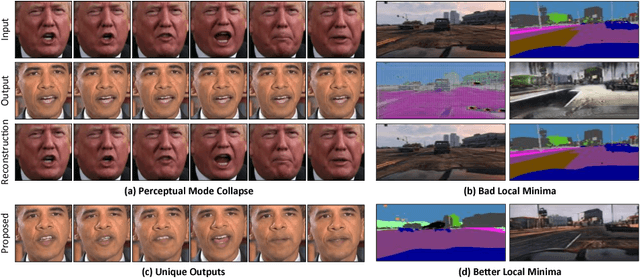
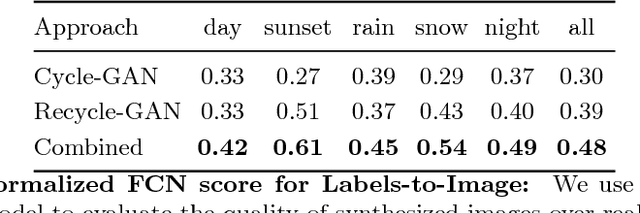
We introduce a data-driven approach for unsupervised video retargeting that translates content from one domain to another while preserving the style native to a domain, i.e., if contents of John Oliver's speech were to be transferred to Stephen Colbert, then the generated content/speech should be in Stephen Colbert's style. Our approach combines both spatial and temporal information along with adversarial losses for content translation and style preservation. In this work, we first study the advantages of using spatiotemporal constraints over spatial constraints for effective retargeting. We then demonstrate the proposed approach for the problems where information in both space and time matters such as face-to-face translation, flower-to-flower, wind and cloud synthesis, sunrise and sunset.
Deep Appearance Models for Face Rendering
Aug 01, 2018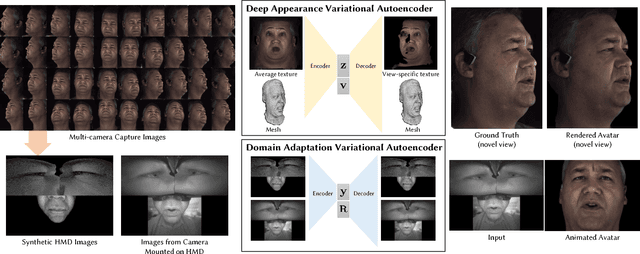
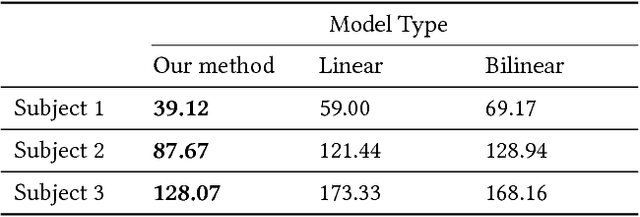
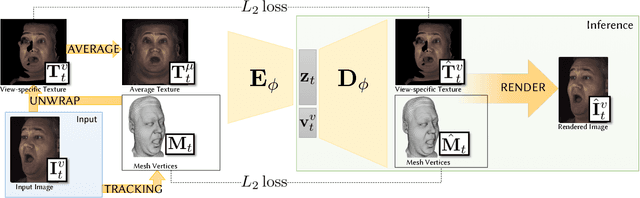

We introduce a deep appearance model for rendering the human face. Inspired by Active Appearance Models, we develop a data-driven rendering pipeline that learns a joint representation of facial geometry and appearance from a multiview capture setup. Vertex positions and view-specific textures are modeled using a deep variational autoencoder that captures complex nonlinear effects while producing a smooth and compact latent representation. View-specific texture enables the modeling of view-dependent effects such as specularity. In addition, it can also correct for imperfect geometry stemming from biased or low resolution estimates. This is a significant departure from the traditional graphics pipeline, which requires highly accurate geometry as well as all elements of the shading model to achieve realism through physically-inspired light transport. Acquiring such a high level of accuracy is difficult in practice, especially for complex and intricate parts of the face, such as eyelashes and the oral cavity. These are handled naturally by our approach, which does not rely on precise estimates of geometry. Instead, the shading model accommodates deficiencies in geometry though the flexibility afforded by the neural network employed. At inference time, we condition the decoding network on the viewpoint of the camera in order to generate the appropriate texture for rendering. The resulting system can be implemented simply using existing rendering engines through dynamic textures with flat lighting. This representation, together with a novel unsupervised technique for mapping images to facial states, results in a system that is naturally suited to real-time interactive settings such as Virtual Reality (VR).
* Accepted to SIGGRAPH 2018
Supervision-by-Registration: An Unsupervised Approach to Improve the Precision of Facial Landmark Detectors
Jul 04, 2018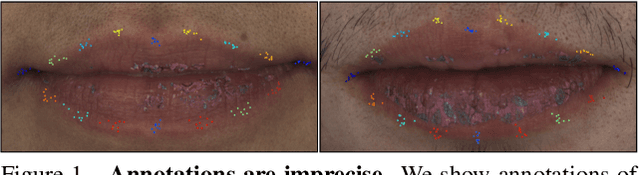
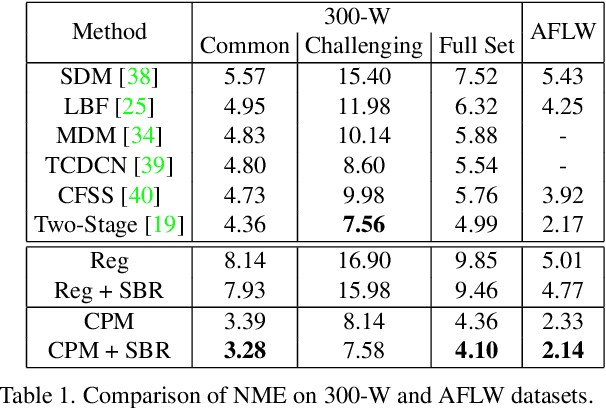
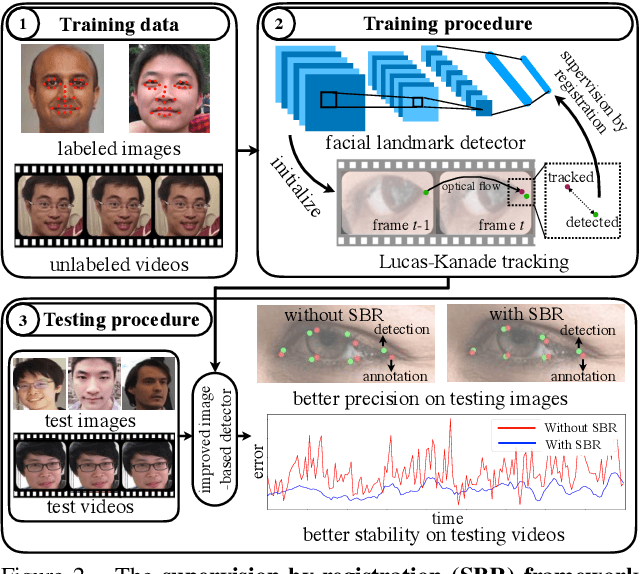
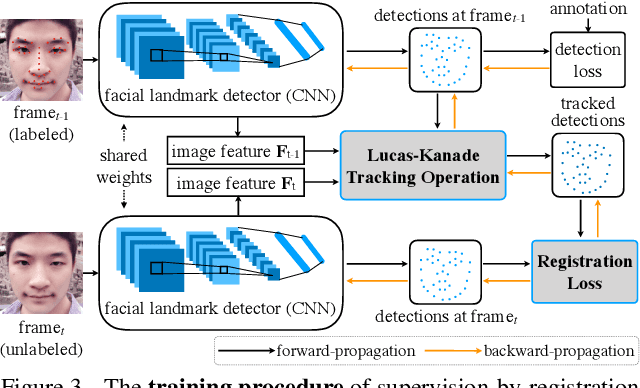
In this paper, we present supervision-by-registration, an unsupervised approach to improve the precision of facial landmark detectors on both images and video. Our key observation is that the detections of the same landmark in adjacent frames should be coherent with registration, i.e., optical flow. Interestingly, the coherency of optical flow is a source of supervision that does not require manual labeling, and can be leveraged during detector training. For example, we can enforce in the training loss function that a detected landmark at frame$_{t-1}$ followed by optical flow tracking from frame$_{t-1}$ to frame$_t$ should coincide with the location of the detection at frame$_t$. Essentially, supervision-by-registration augments the training loss function with a registration loss, thus training the detector to have output that is not only close to the annotations in labeled images, but also consistent with registration on large amounts of unlabeled videos. End-to-end training with the registration loss is made possible by a differentiable Lucas-Kanade operation, which computes optical flow registration in the forward pass, and back-propagates gradients that encourage temporal coherency in the detector. The output of our method is a more precise image-based facial landmark detector, which can be applied to single images or video. With supervision-by-registration, we demonstrate (1) improvements in facial landmark detection on both images (300W, ALFW) and video (300VW, Youtube-Celebrities), and (2) significant reduction of jittering in video detections.
Automatic Adaptation of Person Association for Multiview Tracking in Group Activities
May 22, 2018


Reliable markerless motion tracking of multiple people participating in complex group activity from multiple handheld cameras is challenging due to frequent occlusions, strong viewpoint and appearance variations, and asynchronous video streams. The key to solving this problem is to reliably associate the same person across distant viewpoint and temporal instances. In this work, we combine motion tracking, mutual exclusion constraints, and multiview geometry in a multitask learning framework to automatically adapt a generic person appearance descriptor to the domain videos. Tracking is formulated as a spatiotemporally constrained clustering using the adapted person descriptor. Physical human constraints are exploited to reconstruct accurate and consistent 3D skeletons for every person across the entire sequence. We show significant improvement in association accuracy (up to 18%) in events with up to 60 people and 3D human skeleton reconstruction (5 to 10 times) over the baseline for events captured "in the wild".
Structure from Recurrent Motion: From Rigidity to Recurrency
Apr 18, 2018

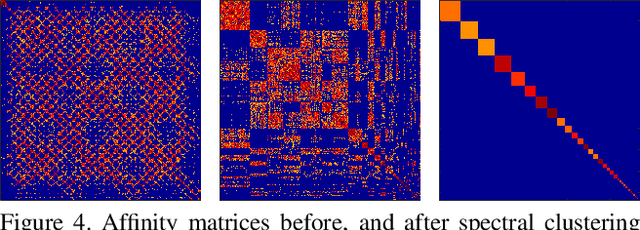
This paper proposes a new method for Non-Rigid Structure-from-Motion (NRSfM) from a long monocular video sequence observing a non-rigid object performing recurrent and possibly repetitive dynamic action. Departing from the traditional idea of using linear low-order or lowrank shape model for the task of NRSfM, our method exploits the property of shape recurrency (i.e., many deforming shapes tend to repeat themselves in time). We show that recurrency is in fact a generalized rigidity. Based on this, we reduce NRSfM problems to rigid ones provided that certain recurrency condition is satisfied. Given such a reduction, standard rigid-SfM techniques are directly applicable (without any change) to the reconstruction of non-rigid dynamic shapes. To implement this idea as a practical approach, this paper develops efficient algorithms for automatic recurrency detection, as well as camera view clustering via a rigidity-check. Experiments on both simulated sequences and real data demonstrate the effectiveness of the method. Since this paper offers a novel perspective on rethinking structure-from-motion, we hope it will inspire other new problems in the field.
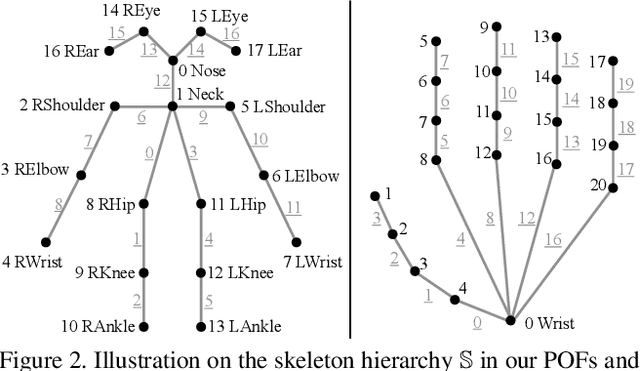
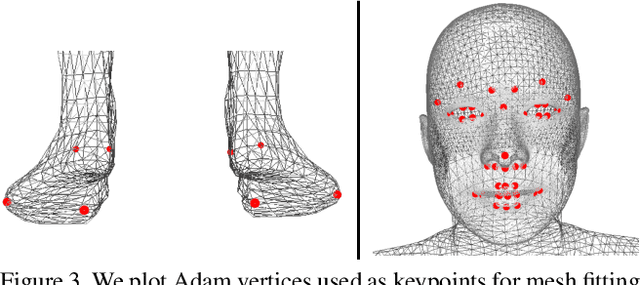
Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies
Jan 05, 2018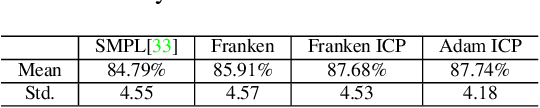
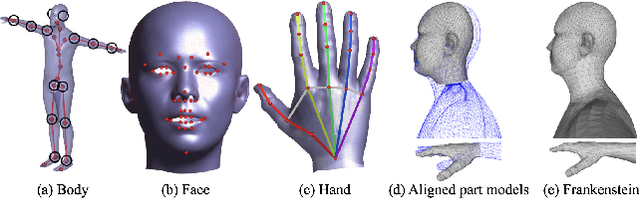
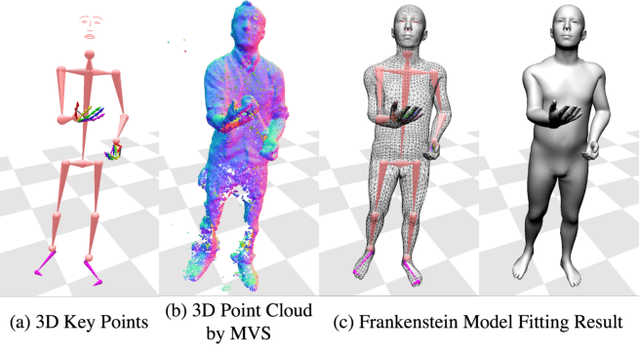
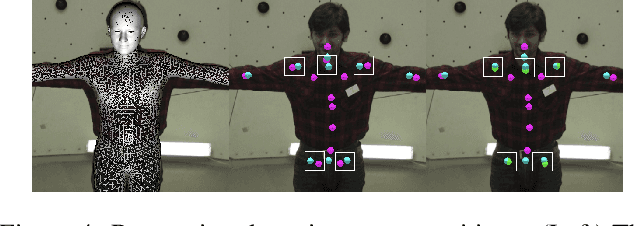
We present a unified deformation model for the markerless capture of multiple scales of human movement, including facial expressions, body motion, and hand gestures. An initial model is generated by locally stitching together models of the individual parts of the human body, which we refer to as the "Frankenstein" model. This model enables the full expression of part movements, including face and hands by a single seamless model. Using a large-scale capture of people wearing everyday clothes, we optimize the Frankenstein model to create "Adam". Adam is a calibrated model that shares the same skeleton hierarchy as the initial model but can express hair and clothing geometry, making it directly usable for fitting people as they normally appear in everyday life. Finally, we demonstrate the use of these models for total motion tracking, simultaneously capturing the large-scale body movements and the subtle face and hand motion of a social group of people.
PixelNN: Example-based Image Synthesis
Aug 17, 2017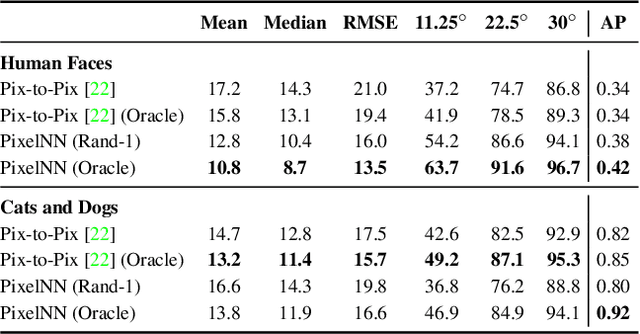
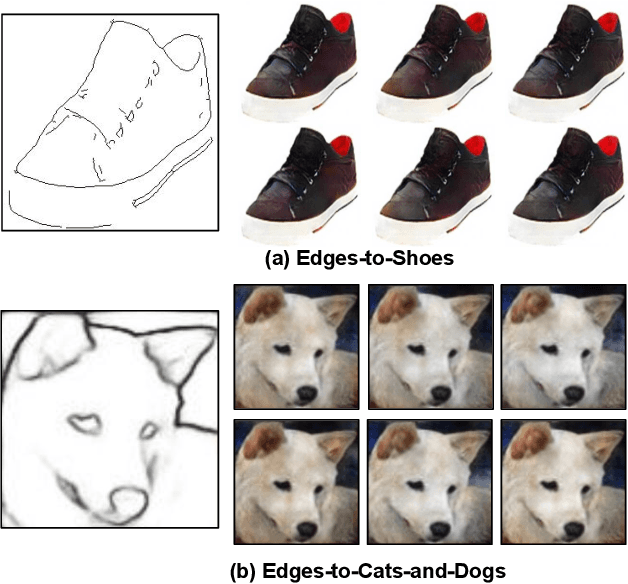
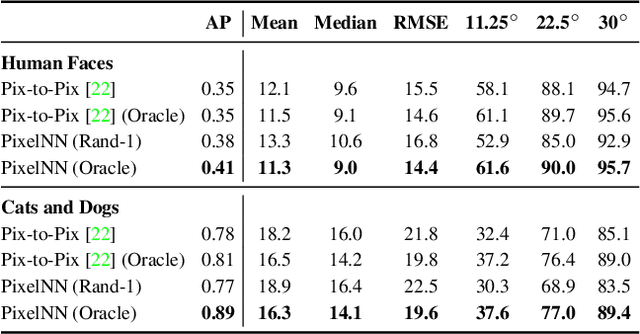

We present a simple nearest-neighbor (NN) approach that synthesizes high-frequency photorealistic images from an "incomplete" signal such as a low-resolution image, a surface normal map, or edges. Current state-of-the-art deep generative models designed for such conditional image synthesis lack two important things: (1) they are unable to generate a large set of diverse outputs, due to the mode collapse problem. (2) they are not interpretable, making it difficult to control the synthesized output. We demonstrate that NN approaches potentially address such limitations, but suffer in accuracy on small datasets. We design a simple pipeline that combines the best of both worlds: the first stage uses a convolutional neural network (CNN) to maps the input to a (overly-smoothed) image, and the second stage uses a pixel-wise nearest neighbor method to map the smoothed output to multiple high-quality, high-frequency outputs in a controllable manner. We demonstrate our approach for various input modalities, and for various domains ranging from human faces to cats-and-dogs to shoes and handbags.
Hand Keypoint Detection in Single Images using Multiview Bootstrapping
Apr 25, 2017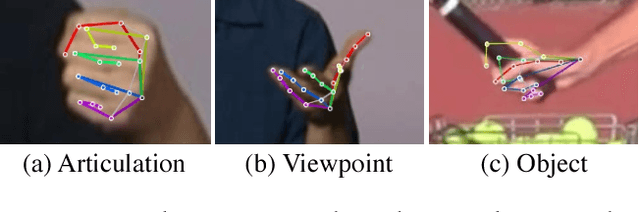
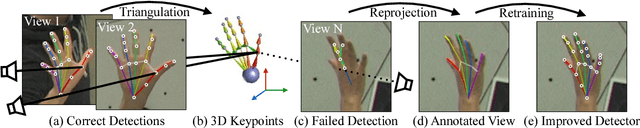
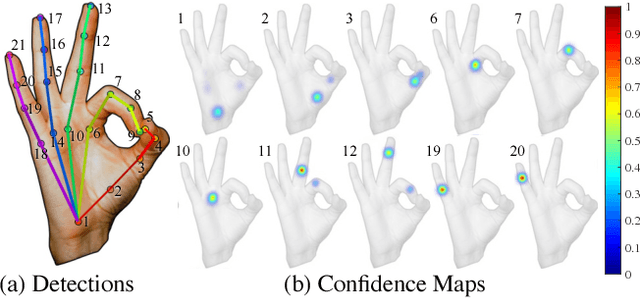
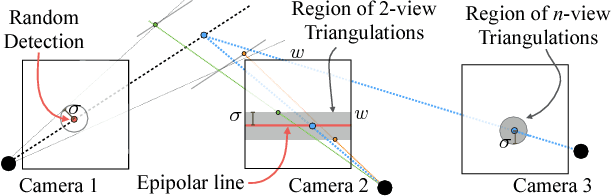
We present an approach that uses a multi-camera system to train fine-grained detectors for keypoints that are prone to occlusion, such as the joints of a hand. We call this procedure multiview bootstrapping: first, an initial keypoint detector is used to produce noisy labels in multiple views of the hand. The noisy detections are then triangulated in 3D using multiview geometry or marked as outliers. Finally, the reprojected triangulations are used as new labeled training data to improve the detector. We repeat this process, generating more labeled data in each iteration. We derive a result analytically relating the minimum number of views to achieve target true and false positive rates for a given detector. The method is used to train a hand keypoint detector for single images. The resulting keypoint detector runs in realtime on RGB images and has accuracy comparable to methods that use depth sensors. The single view detector, triangulated over multiple views, enables 3D markerless hand motion capture with complex object interactions.