 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliceOut: Training Transformers and CNNs faster while using less memory
Jul 21, 2020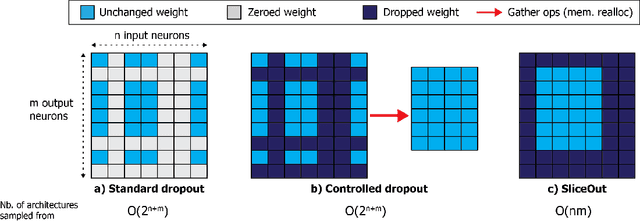
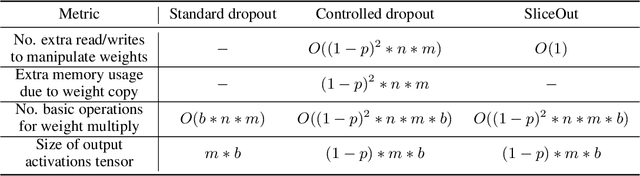
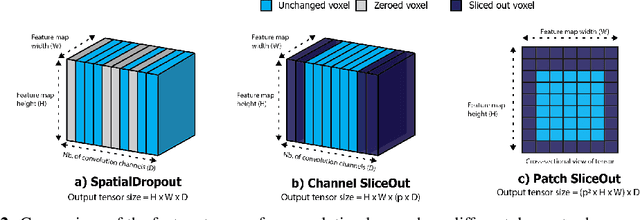
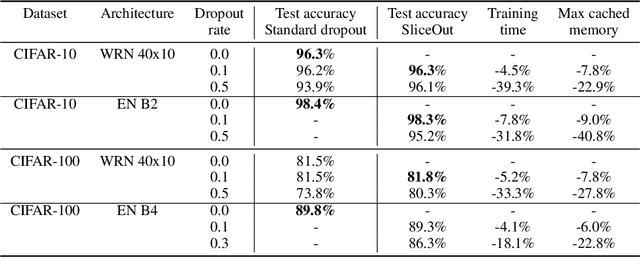
We demonstrate 10-40% speedups and memory reduction with Wide ResNets, EfficientNets, and Transformer models, with minimal to no loss in accuracy, using SliceOut---a new dropout scheme designed to take advantage of GPU memory layout. By dropping contiguous sets of units at random, our method preserves the regularization properties of dropout while allowing for more efficient low-level implementation, resulting in training speedups through (1) fast memory access and matrix multiplication of smaller tensors, and (2) memory savings by avoiding allocating memory to zero units in weight gradients and activations. Despite its simplicity, our method is highly effective. We demonstrate its efficacy at scale with Wide ResNets & EfficientNets on CIFAR10/100 and ImageNet, as well as Transformers on the LM1B dataset. These speedups and memory savings in training can lead to $CO_2$ emissions reduction of up to 40% for training large models.
Single Shot Structured Pruning Before Training
Jul 01, 2020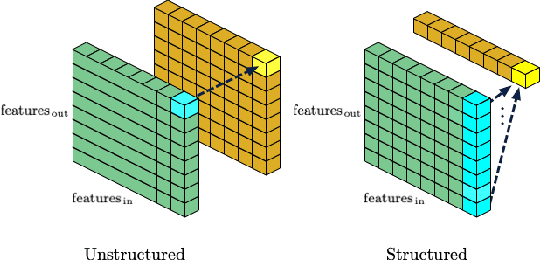
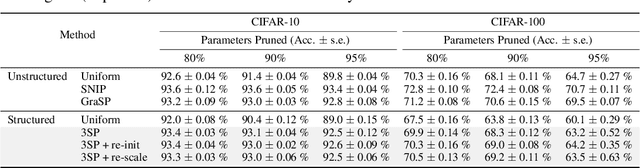
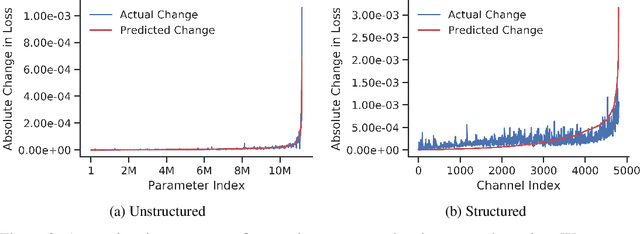

We introduce a method to speed up training by 2x and inference by 3x in deep neural networks using structured pruning applied before training. Unlike previous works on pruning before training which prune individual weights, our work develops a methodology to remove entire channels and hidden units with the explicit aim of speeding up training and inference. We introduce a compute-aware scoring mechanism which enables pruning in units of sensitivity per FLOP removed, allowing even greater speed ups. Our method is fast, easy to implement, and needs just one forward/backward pass on a single batch of data to complete pruning before training begins.
Identifying Causal Effect Inference Failure with Uncertainty-Aware Models
Jul 01, 2020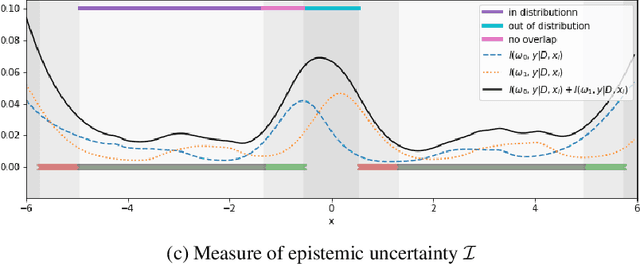
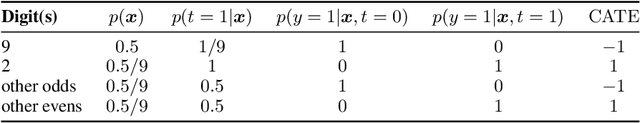
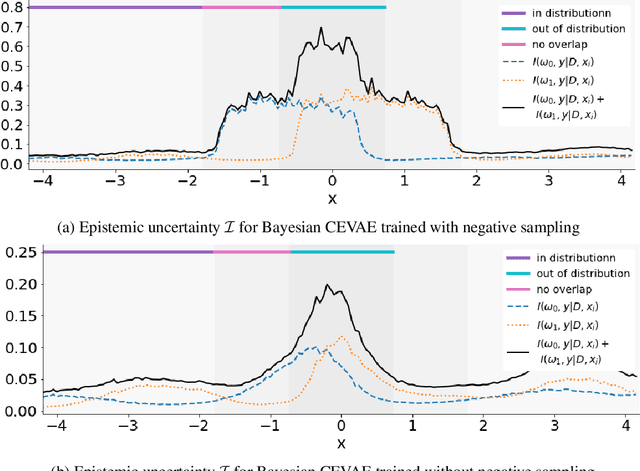
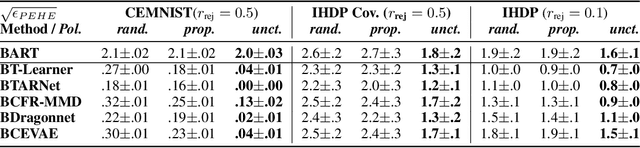
Recommending the best course of action for an individual is a major application of individual-level causal effect estimation. This application is often needed in safety-critical domains such as healthcare, where estimating and communicating uncertainty to decision-makers is crucial. We introduce a practical approach for integrating uncertainty estimation into a class of state-of-the-art neural network methods used for individual-level causal estimates. We show that our methods enable us to deal gracefully with situations of "no-overlap", common in high-dimensional data, where standard applications of causal effect approaches fail. Further, our methods allow us to handle covariate shift, where test distribution differs to train distribution, common when systems are deployed in practice. We show that when such a covariate shift occurs, correctly modeling uncertainty can keep us from giving overconfident and potentially harmful recommendations. We demonstrate our methodology with a range of state-of-the-art models. Under both covariate shift and lack of overlap, our uncertainty-equipped methods can alert decisions makers when predictions are not to be trusted while outperforming their uncertainty-oblivious counterparts.
Can Autonomous Vehicles Identify, Recover From, and Adapt to Distribution Shifts?
Jun 26, 2020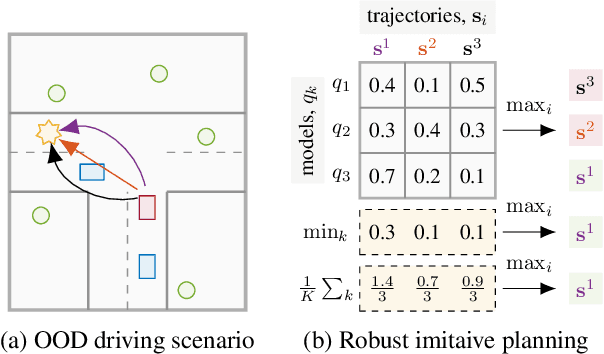


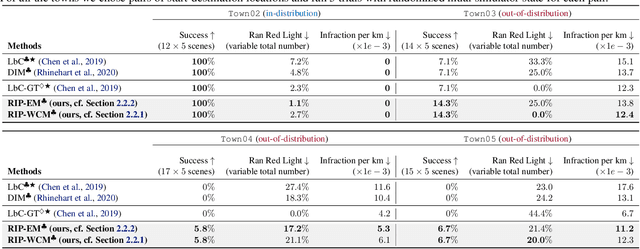
Out-of-training-distribution (OOD) scenarios are a common challenge of learning agents at deployment, typically leading to arbitrary deductions and poorly-informed decisions. In principle, detection of and adaptation to OOD scenes can mitigate their adverse effects. In this paper, we highlight the limitations of current approaches to novel driving scenes and propose an epistemic uncertainty-aware planning method, called \emph{robust imitative planning} (RIP). Our method can detect and recover from some distribution shifts, reducing the overconfident and catastrophic extrapolations in OOD scenes. If the model's uncertainty is too great to suggest a safe course of action, the model can instead query the expert driver for feedback, enabling sample-efficient online adaptation, a variant of our method we term \emph{adaptive robust imitative planning} (AdaRIP). Our methods outperform current state-of-the-art approaches in the nuScenes \emph{prediction} challenge, but since no benchmark evaluating OOD detection and adaption currently exists to assess \emph{control}, we introduce an autonomous car novel-scene benchmark, \texttt{CARNOVEL}, to evaluate the robustness of driving agents to a suite of tasks with distribution shifts.
Learning Invariant Representations for Reinforcement Learning without Reconstruction
Jun 18, 2020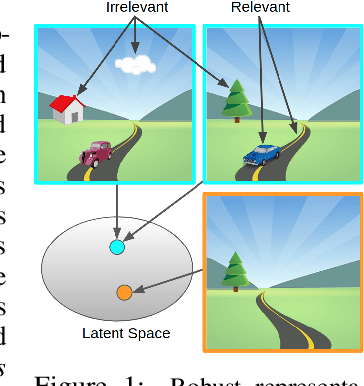
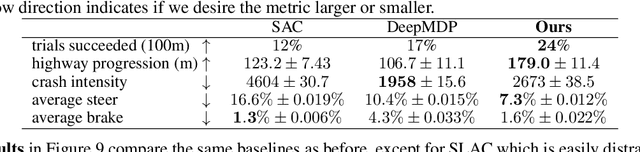

We study how representation learning can accelerate reinforcement learning from rich observations, such as images, without relying either on domain knowledge or pixel-reconstruction. Our goal is to learn representations that both provide for effective downstream control and invariance to task-irrelevant details. Bisimulation metrics quantify behavioral similarity between states in continuous MDPs, which we propose using to learn robust latent representations which encode only the task-relevant information from observations. Our method trains encoders such that distances in latent space equal bisimulation distances in state space. We demonstrate the effectiveness of our method at disregarding task-irrelevant information using modified visual MuJoCo tasks, where the background is replaced with moving distractors and natural videos, while achieving SOTA performance. We also test a first-person highway driving task where our method learns invariance to clouds, weather, and time of day. Finally, we provide generalization results drawn from properties of bisimulation metrics, and links to causal inference.
Wat zei je? Detecting Out-of-Distribution Translations with Variational Transformers
Jun 08, 2020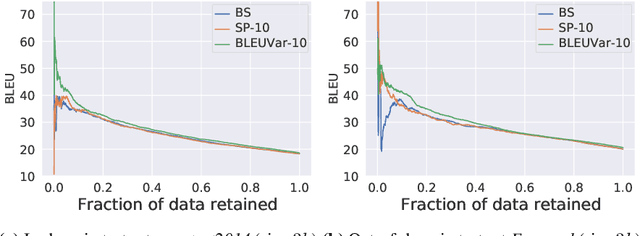
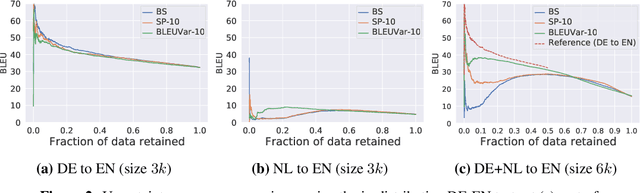
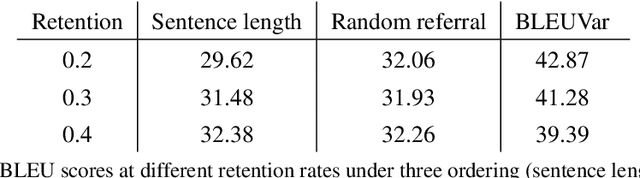
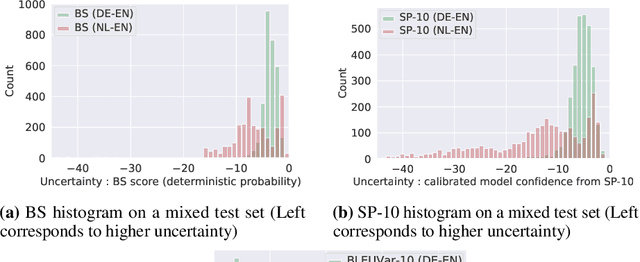
We detect out-of-training-distribution sentences in Neural Machine Translation using the Bayesian Deep Learning equivalent of Transformer models. For this we develop a new measure of uncertainty designed specifically for long sequences of discrete random variables -- i.e. words in the output sentence. Our new measure of uncertainty solves a major intractability in the naive application of existing approaches on long sentences. We use our new measure on a Transformer model trained with dropout approximate inference. On the task of German-English translation using WMT13 and Europarl, we show that with dropout uncertainty our measure is able to identify when Dutch source sentences, sentences which use the same word types as German, are given to the model instead of German.
Revisiting the Train Loss: an Efficient Performance Estimator for Neural Architecture Search
Jun 08, 2020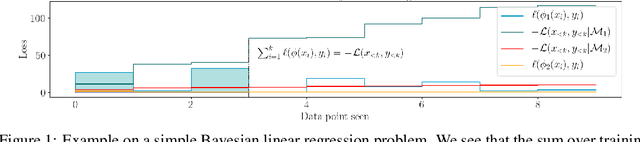
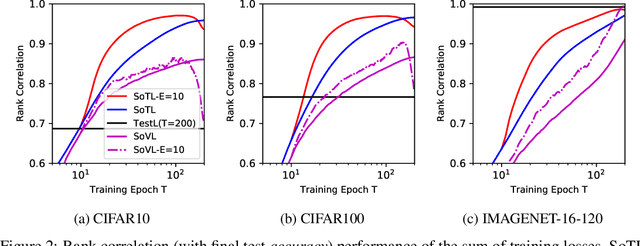
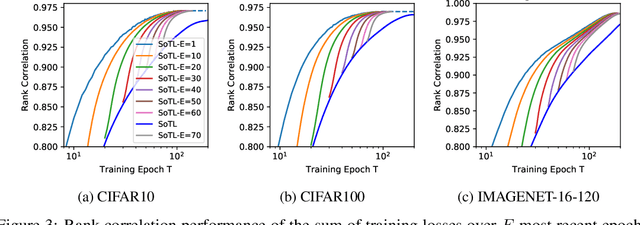
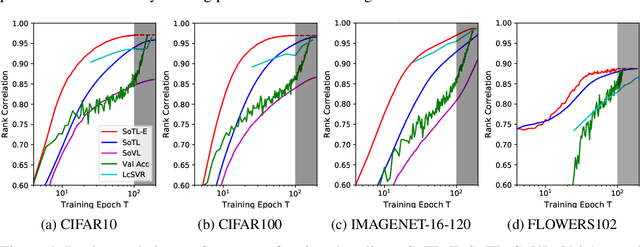
Reliable yet efficient evaluation of generalisation performance of a proposed architecture is crucial to the success of neural architecture search (NAS). Traditional approaches face a variety of limitations: training each architecture to completion is prohibitively expensive, early stopping estimates may correlate poorly with fully trained performance, and model-based estimators require large training sets. Instead, motivated by recent results linking training speed and generalisation with stochastic gradient descent, we propose to estimate the final test performance based on the sum of training losses. Our estimator is inspired by the marginal likelihood, which is used for Bayesian model selection. Our model-free estimator is simple, efficient, and cheap to implement, and does not require hyperparameter-tuning or surrogate training before deployment. We demonstrate empirically that our estimator consistently outperforms other baselines and can achieve a rank correlation of 0.95 with final test accuracy on the NAS-Bench201 dataset within 50 epochs.
Uncertainty Evaluation Metric for Brain Tumour Segmentation
May 28, 2020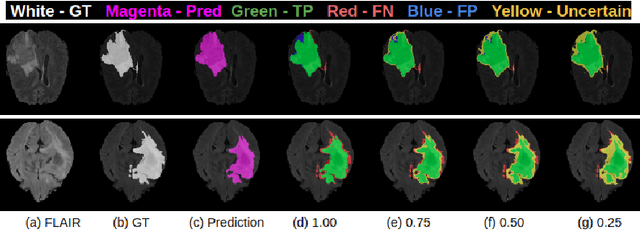
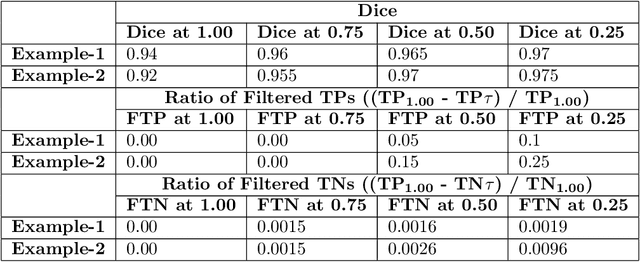
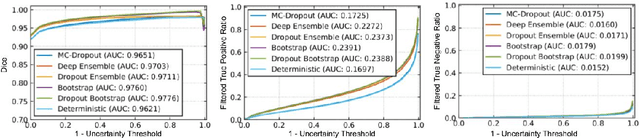
In this paper, we develop a metric designed to assess and rank uncertainty measures for the task of brain tumour sub-tissue segmentation in the BraTS 2019 sub-challenge on uncertainty quantification. The metric is designed to: (1) reward uncertainty measures where high confidence is assigned to correct assertions, and where incorrect assertions are assigned low confidence and (2) penalize measures that have higher percentages of under-confident correct assertions. Here, the workings of the components of the metric are explored based on a number of popular uncertainty measures evaluated on the BraTS 2019 dataset.
On the Benefits of Invariance in Neural Networks
May 01, 2020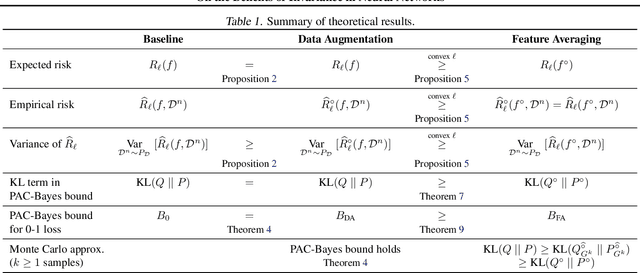
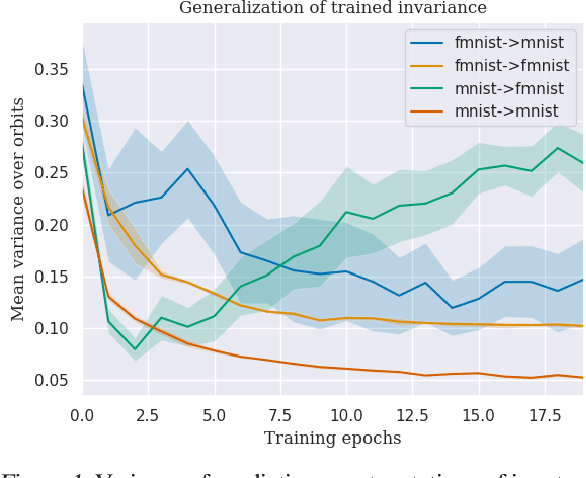
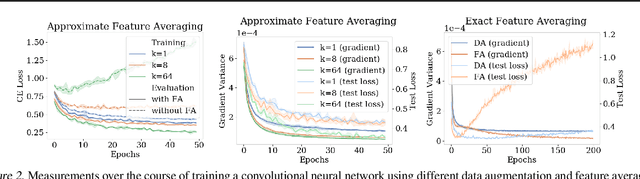
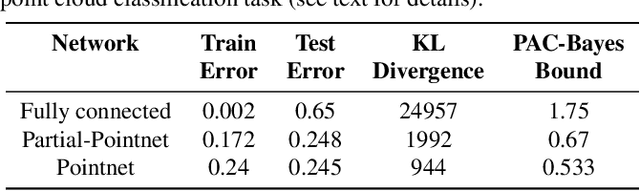
Many real world data analysis problems exhibit invariant structure, and models that take advantage of this structure have shown impressive empirical performance, particularly in deep learning. While the literature contains a variety of methods to incorporate invariance into models, theoretical understanding is poor and there is no way to assess when one method should be preferred over another. In this work, we analyze the benefits and limitations of two widely used approaches in deep learning in the presence of invariance: data augmentation and feature averaging. We prove that training with data augmentation leads to better estimates of risk and gradients thereof, and we provide a PAC-Bayes generalization bound for models trained with data augmentation. We also show that compared to data augmentation, feature averaging reduces generalization error when used with convex losses, and tightens PAC-Bayes bounds. We provide empirical support of these theoretical results, including a demonstration of why generalization may not improve by training with data augmentation: the `learned invariance' fails outside of the training distribution.
Unpacking Information Bottlenecks: Unifying Information-Theoretic Objectives in Deep Learning
Apr 09, 2020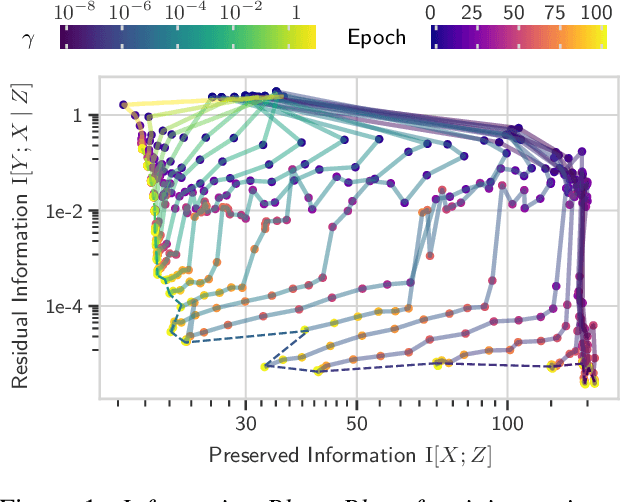
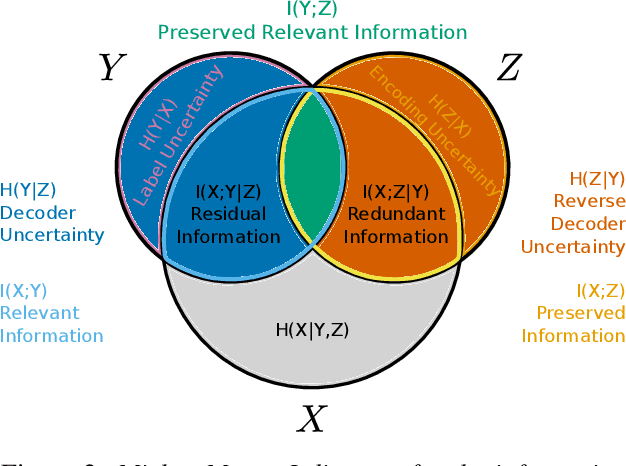
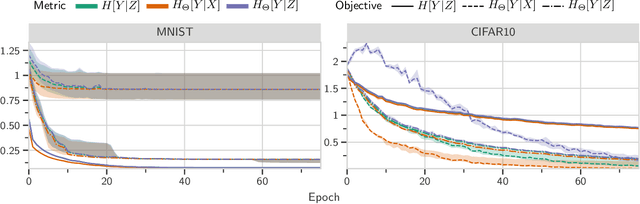
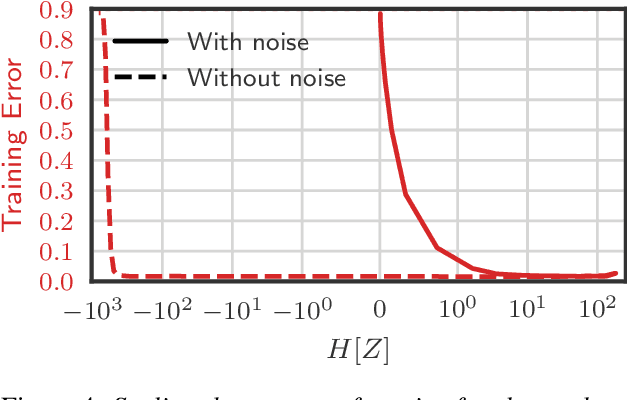
The information bottleneck (IB) principle offers both a mechanism to explain how deep neural networks train and generalize, as well as a regularized objective with which to train models. However, multiple competing objectives have been proposed based on this principle, and the information-theoretic quantities in these objectives are difficult to compute for large deep neural networks. This, in turn, limits their use as a training objective. In this work, we review these quantities, compare and unify previously proposed objectives and relate them to surrogate objectives more friendly to optimization. We find that these surrogate objectives allow us to apply the information bottleneck to modern neural network architectures. We demonstrate our insights on Permutation-MNIST, MNIST and CIFAR10.