 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Interpretable Counterfactual Explanations By Implicit Minimisation of Epistemic and Aleatoric Uncertainties
Mar 16, 2021
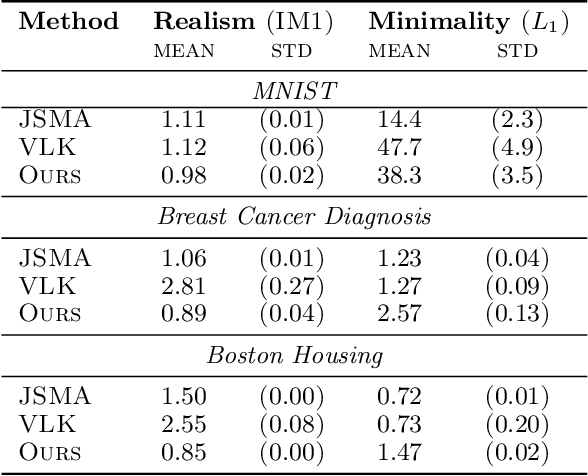


Counterfactual explanations (CEs) are a practical tool for demonstrating why machine learning classifiers make particular decisions. For CEs to be useful, it is important that they are easy for users to interpret. Existing methods for generating interpretable CEs rely on auxiliary generative models, which may not be suitable for complex datasets, and incur engineering overhead. We introduce a simple and fast method for generating interpretable CEs in a white-box setting without an auxiliary model, by using the predictive uncertainty of the classifier. Our experiments show that our proposed algorithm generates more interpretable CEs, according to IM1 scores, than existing methods. Additionally, our approach allows us to estimate the uncertainty of a CE, which may be important in safety-critical applications, such as those in the medical domain.
* 21 pages, 13 Figures
Robustness to Pruning Predicts Generalization in Deep Neural Networks
Mar 10, 2021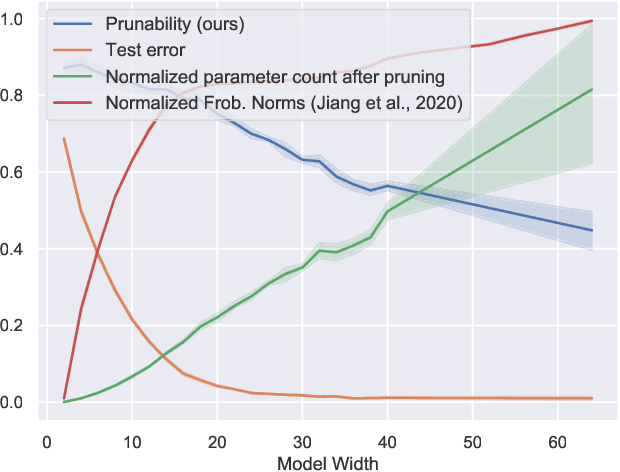
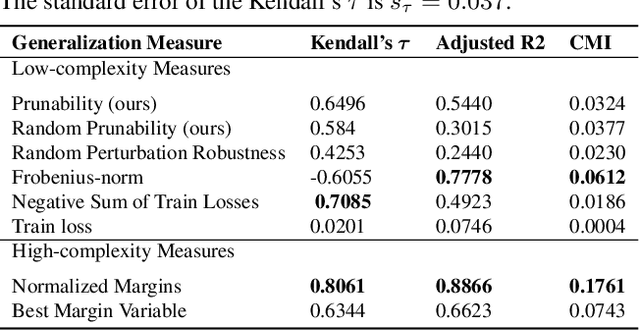
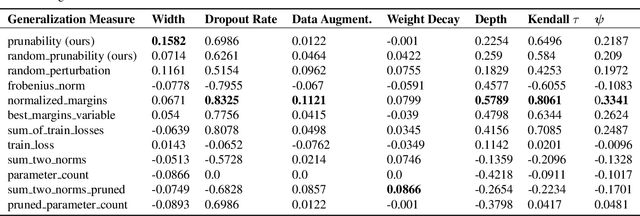
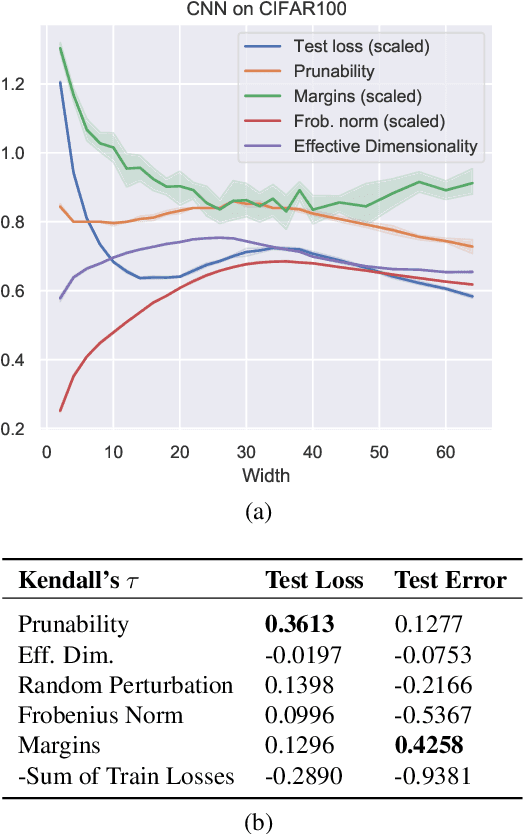
Existing generalization measures that aim to capture a model's simplicity based on parameter counts or norms fail to explain generalization in overparameterized deep neural networks. In this paper, we introduce a new, theoretically motivated measure of a network's simplicity which we call prunability: the smallest \emph{fraction} of the network's parameters that can be kept while pruning without adversely affecting its training loss. We show that this measure is highly predictive of a model's generalization performance across a large set of convolutional networks trained on CIFAR-10, does not grow with network size unlike existing pruning-based measures, and exhibits high correlation with test set loss even in a particularly challenging double descent setting. Lastly, we show that the success of prunability cannot be explained by its relation to known complexity measures based on models' margin, flatness of minima and optimization speed, finding that our new measure is similar to -- but more predictive than -- existing flatness-based measures, and that its predictions exhibit low mutual information with those of other baselines.
Active Testing: Sample-Efficient Model Evaluation
Mar 09, 2021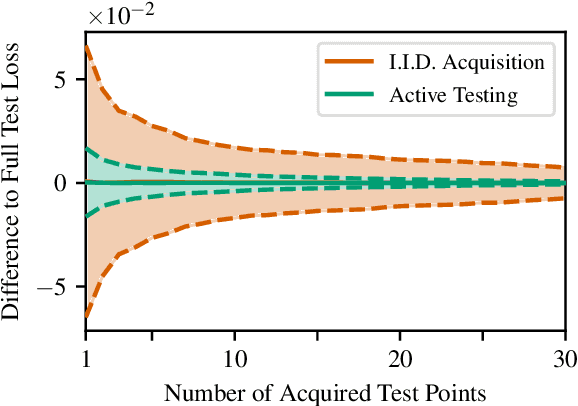
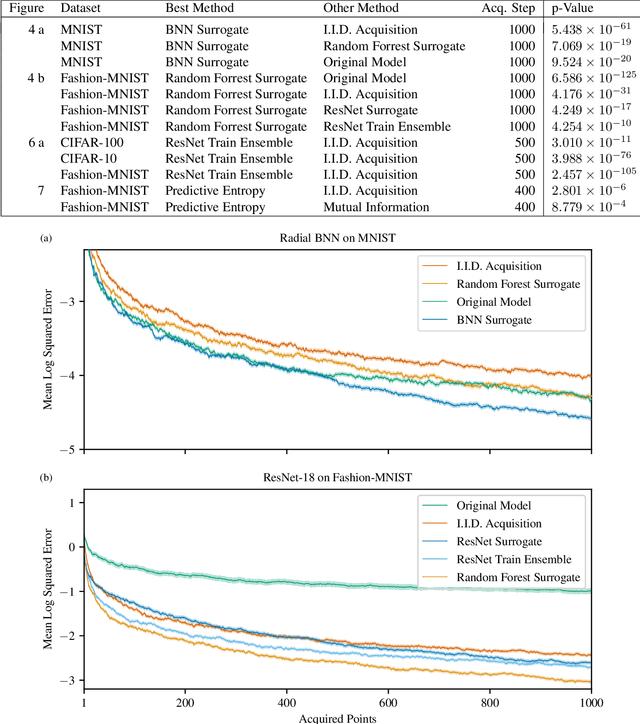
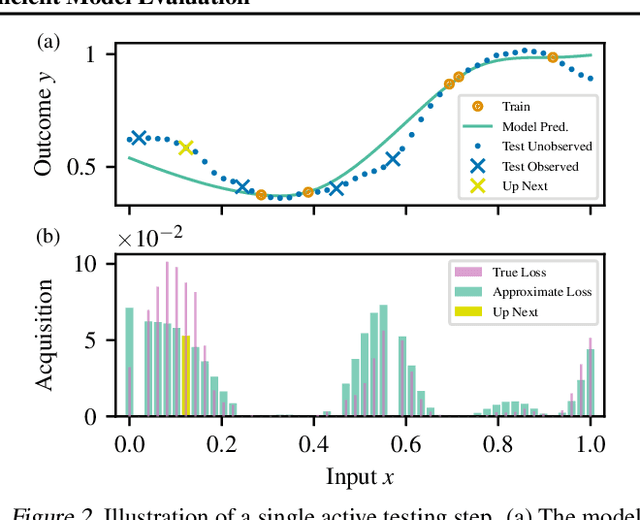
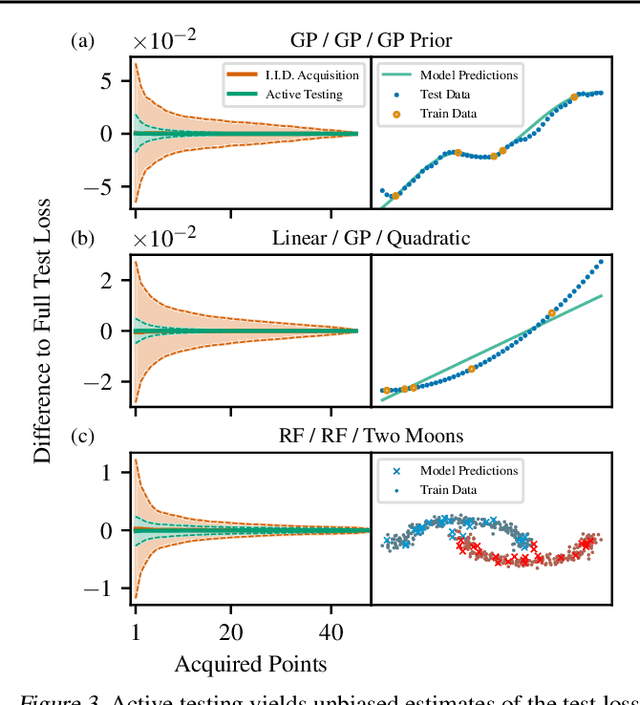
We introduce active testing: a new framework for sample-efficient model evaluation. While approaches like active learning reduce the number of labels needed for model training, existing literature largely ignores the cost of labeling test data, typically unrealistically assuming large test sets for model evaluation. This creates a disconnect to real applications where test labels are important and just as expensive, e.g. for optimizing hyperparameters. Active testing addresses this by carefully selecting the test points to label, ensuring model evaluation is sample-efficient. To this end, we derive theoretically-grounded and intuitive acquisition strategies that are specifically tailored to the goals of active testing, noting these are distinct to those of active learning. Actively selecting labels introduces a bias; we show how to remove that bias while reducing the variance of the estimator at the same time. Active testing is easy to implement, effective, and can be applied to any supervised machine learning method. We demonstrate this on models including WideResNet and Gaussian processes on datasets including CIFAR-100.
Quantifying Ignorance in Individual-Level Causal-Effect Estimates under Hidden Confounding
Mar 08, 2021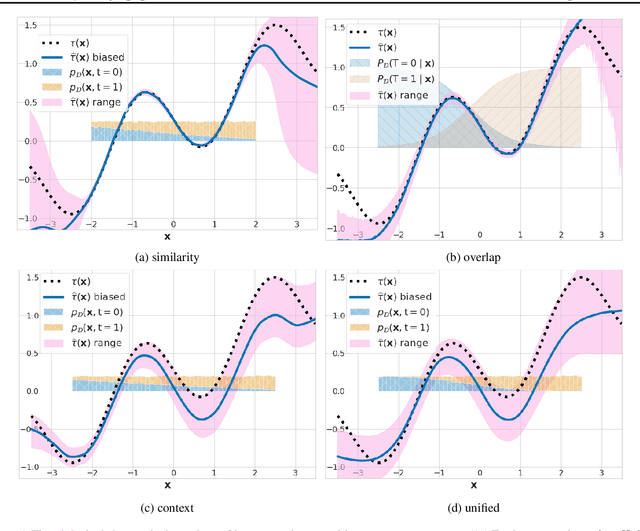

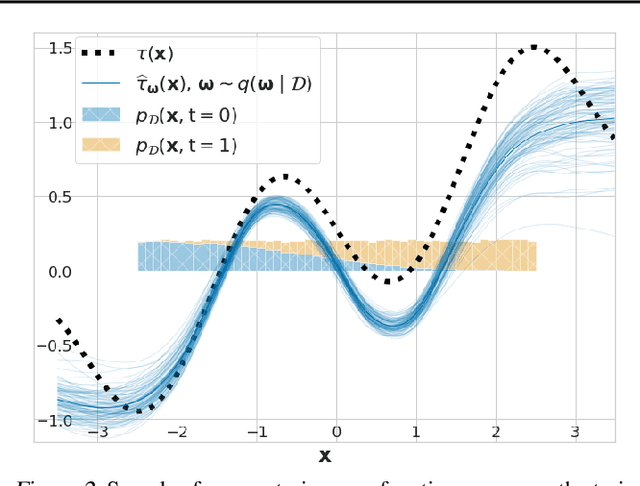
We study the problem of learning conditional average treatment effects (CATE) from high-dimensional, observational data with unobserved confounders. Unobserved confounders introduce ignorance -- a level of unidentifiability -- about an individual's response to treatment by inducing bias in CATE estimates. We present a new parametric interval estimator suited for high-dimensional data, that estimates a range of possible CATE values when given a predefined bound on the level of hidden confounding. Further, previous interval estimators do not account for ignorance about the CATE stemming from samples that may be underrepresented in the original study, or samples that violate the overlap assumption. Our novel interval estimator also incorporates model uncertainty so that practitioners can be made aware of out-of-distribution data. We prove that our estimator converges to tight bounds on CATE when there may be unobserved confounding, and assess it using semi-synthetic, high-dimensional datasets.
PsiPhi-Learning: Reinforcement Learning with Demonstrations using Successor Features and Inverse Temporal Difference Learning
Feb 24, 2021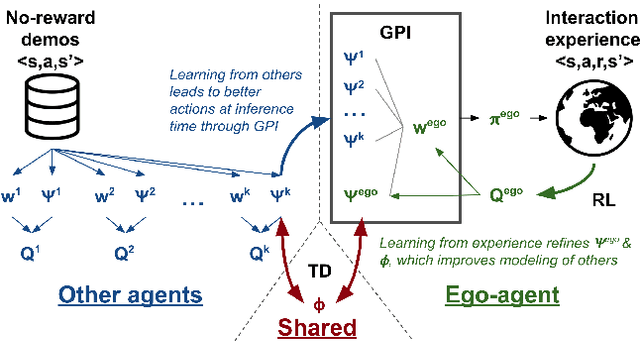
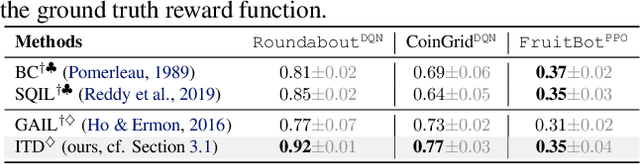
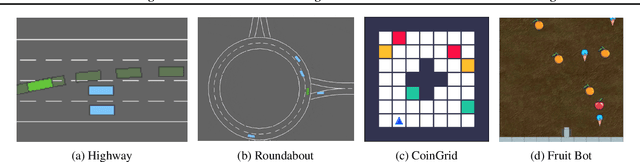

We study reinforcement learning (RL) with no-reward demonstrations, a setting in which an RL agent has access to additional data from the interaction of other agents with the same environment. However, it has no access to the rewards or goals of these agents, and their objectives and levels of expertise may vary widely. These assumptions are common in multi-agent settings, such as autonomous driving. To effectively use this data, we turn to the framework of successor features. This allows us to disentangle shared features and dynamics of the environment from agent-specific rewards and policies. We propose a multi-task inverse reinforcement learning (IRL) algorithm, called \emph{inverse temporal difference learning} (ITD), that learns shared state features, alongside per-agent successor features and preference vectors, purely from demonstrations without reward labels. We further show how to seamlessly integrate ITD with learning from online environment interactions, arriving at a novel algorithm for reinforcement learning with demonstrations, called $\Psi \Phi$-learning (pronounced `Sci-Fi'). We provide empirical evidence for the effectiveness of $\Psi \Phi$-learning as a method for improving RL, IRL, imitation, and few-shot transfer, and derive worst-case bounds for its performance in zero-shot transfer to new tasks.
Deterministic Neural Networks with Appropriate Inductive Biases Capture Epistemic and Aleatoric Uncertainty
Feb 23, 2021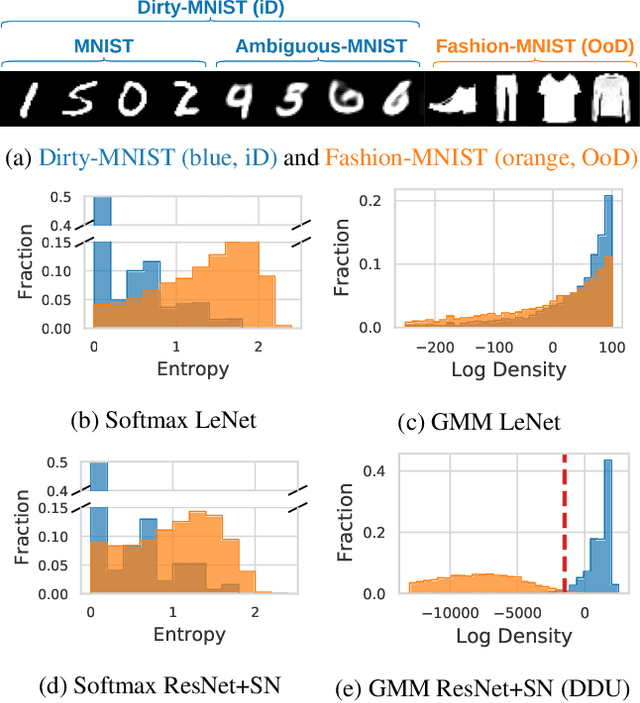

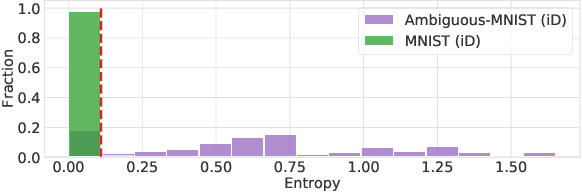
We show that a single softmax neural net with minimal changes can beat the uncertainty predictions of Deep Ensembles and other more complex single-forward-pass uncertainty approaches. Softmax neural nets cannot capture epistemic uncertainty reliably because for OoD points they extrapolate arbitrarily and suffer from feature collapse. This results in arbitrary softmax entropies for OoD points which can have high entropy, low, or anything in between. We study why, and show that with the right inductive biases, softmax neural nets trained with maximum likelihood reliably capture epistemic uncertainty through the feature-space density. This density is obtained using Gaussian Discriminant Analysis, but it cannot disentangle uncertainties. We show that it is necessary to combine this density with the softmax entropy to disentangle aleatoric and epistemic uncertainty -- crucial e.g. for active learning. We examine the quality of epistemic uncertainty on active learning and OoD detection, where we obtain SOTA ~0.98 AUROC on CIFAR-10 vs SVHN.
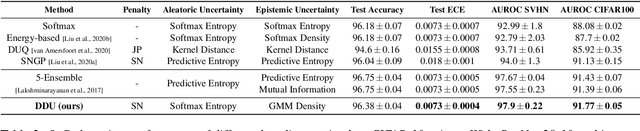
Improving Deterministic Uncertainty Estimation in Deep Learning for Classification and Regression
Feb 22, 2021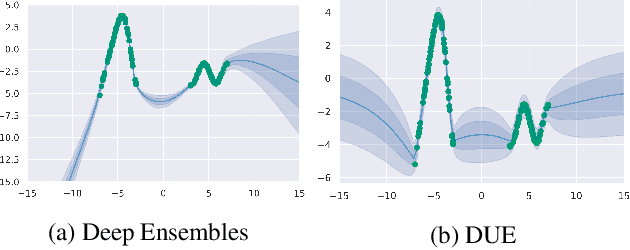

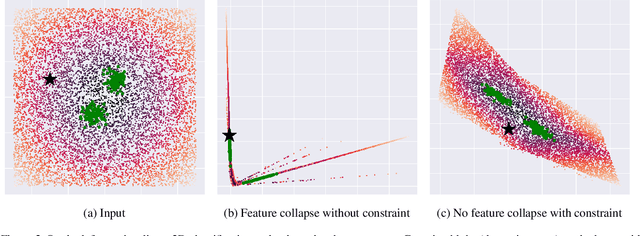
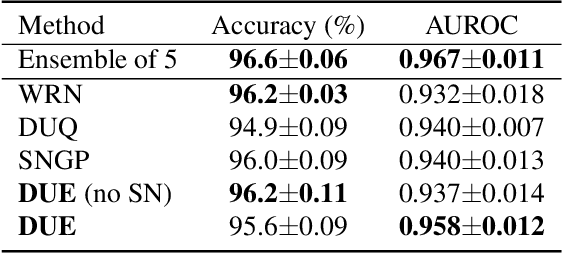
We propose a new model that estimates uncertainty in a single forward pass and works on both classification and regression problems. Our approach combines a bi-Lipschitz feature extractor with an inducing point approximate Gaussian process, offering robust and principled uncertainty estimation. This can be seen as a refinement of Deep Kernel Learning (DKL), with our changes allowing DKL to match softmax neural networks accuracy. Our method overcomes the limitations of previous work addressing deterministic uncertainty quantification, such as the dependence of uncertainty on ad hoc hyper-parameters. Our method matches SotA accuracy, 96.2% on CIFAR-10, while maintaining the speed of softmax models, and provides uncertainty estimates that outperform previous single forward pass uncertainty models. Finally, we demonstrate our method on a recently introduced benchmark for uncertainty in regression: treatment deferral in causal models for personalized medicine.
Domain Invariant Representation Learning with Domain Density Transformations
Feb 14, 2021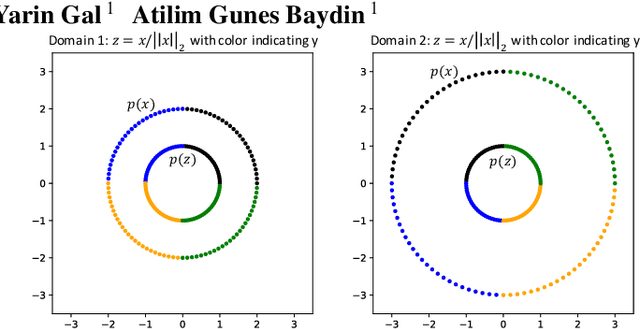
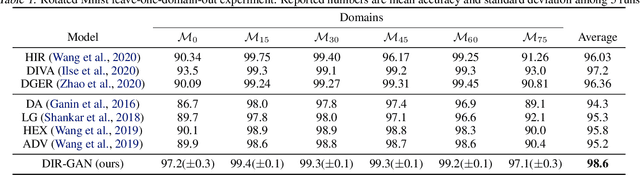
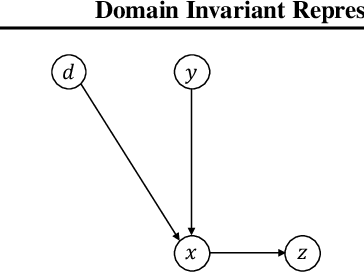
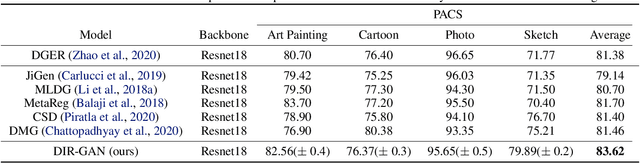
Domain generalization refers to the problem where we aim to train a model on data from a set of source domains so that the model can generalize to unseen target domains. Naively training a model on the aggregate set of data (pooled from all source domains) has been shown to perform suboptimally, since the information learned by that model might be domain-specific and generalize imperfectly to target domains. To tackle this problem, a predominant approach is to find and learn some domain-invariant information in order to use it for the prediction task. In this paper, we propose a theoretically grounded method to learn a domain-invariant representation by enforcing the representation network to be invariant under all transformation functions among domains. We also show how to use generative adversarial networks to learn such domain transformations to implement our method in practice. We demonstrate the effectiveness of our method on several widely used datasets for the domain generalization problem, on all of which we achieve competitive results with state-of-the-art models.
Global Earth Magnetic Field Modeling and Forecasting with Spherical Harmonics Decomposition
Feb 02, 2021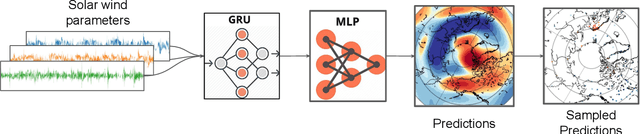


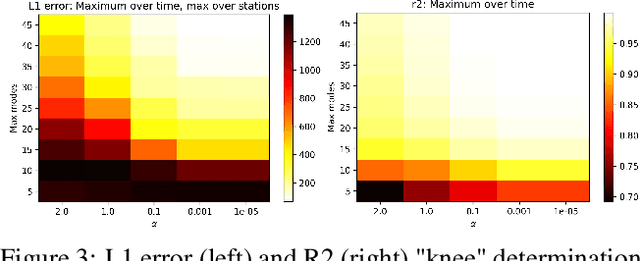
Modeling and forecasting the solar wind-driven global magnetic field perturbations is an open challenge. Current approaches depend on simulations of computationally demanding models like the Magnetohydrodynamics (MHD) model or sampling spatially and temporally through sparse ground-based stations (SuperMAG). In this paper, we develop a Deep Learning model that forecasts in Spherical Harmonics space 2, replacing reliance on MHD models and providing global coverage at one minute cadence, improving over the current state-of-the-art which relies on feature engineering. We evaluate the performance in SuperMAG dataset (improved by 14.53%) and MHD simulations (improved by 24.35%). Additionally, we evaluate the extrapolation performance of the spherical harmonics reconstruction based on sparse ground-based stations (SuperMAG), showing that spherical harmonics can reliably reconstruct the global magnetic field as evaluated on MHD simulation.
Multi-Channel Auto-Calibration for the Atmospheric Imaging Assembly using Machine Learning
Feb 01, 2021
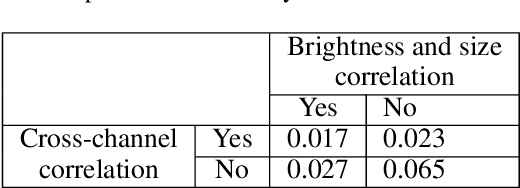

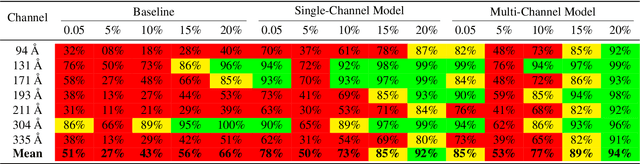
Solar activity plays a quintessential role in influencing the interplanetary medium and space-weather around the Earth. Remote sensing instruments onboard heliophysics space missions provide a pool of information about the Sun's activity via the measurement of its magnetic field and the emission of light from the multi-layered, multi-thermal, and dynamic solar atmosphere. Extreme UV (EUV) wavelength observations from space help in understanding the subtleties of the outer layers of the Sun, namely the chromosphere and the corona. Unfortunately, such instruments, like the Atmospheric Imaging Assembly (AIA) onboard NASA's Solar Dynamics Observatory (SDO), suffer from time-dependent degradation, reducing their sensitivity. Current state-of-the-art calibration techniques rely on periodic sounding rockets, which can be infrequent and rather unfeasible for deep-space missions. We present an alternative calibration approach based on convolutional neural networks (CNNs). We use SDO-AIA data for our analysis. Our results show that CNN-based models could comprehensively reproduce the sounding rocket experiments' outcomes within a reasonable degree of accuracy, indicating that it performs equally well compared with the current techniques. Furthermore, a comparison with a standard "astronomer's technique" baseline model reveals that the CNN approach significantly outperforms this baseline. Our approach establishes the framework for a novel technique to calibrate EUV instruments and advance our understanding of the cross-channel relation between different EUV channels.