 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
New Paradigm of Adversarial Training: Breaking Inherent Trade-Off between Accuracy and Robustness via Dummy Classes
Oct 16, 2024



Adversarial Training (AT) is one of the most effective methods to enhance the robustness of DNNs. However, existing AT methods suffer from an inherent trade-off between adversarial robustness and clean accuracy, which seriously hinders their real-world deployment. While this problem has been widely studied within the current AT paradigm, existing AT methods still typically experience a reduction in clean accuracy by over 10% to date, without significant improvements in robustness compared with simple baselines like PGD-AT. This inherent trade-off raises a question: whether the current AT paradigm, which assumes to learn the corresponding benign and adversarial samples as the same class, inappropriately combines clean and robust objectives that may be essentially inconsistent. In this work, we surprisingly reveal that up to 40% of CIFAR-10 adversarial samples always fail to satisfy such an assumption across various AT methods and robust models, explicitly indicating the improvement room for the current AT paradigm. Accordingly, to relax the tension between clean and robust learning derived from this overstrict assumption, we propose a new AT paradigm by introducing an additional dummy class for each original class, aiming to accommodate the hard adversarial samples with shifted distribution after perturbation. The robustness w.r.t. these adversarial samples can be achieved by runtime recovery from the predicted dummy classes to their corresponding original ones, eliminating the compromise with clean learning. Building on this new paradigm, we propose a novel plug-and-play AT technology named DUmmy Classes-based Adversarial Training (DUCAT). Extensive experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet demonstrate that the DUCAT concurrently improves clean accuracy and adversarial robustness compared with state-of-the-art benchmarks, effectively breaking the existing inherent trade-off.
Alignment-Aware Model Extraction Attacks on Large Language Models
Sep 04, 2024



Model extraction attacks (MEAs) on large language models (LLMs) have received increasing research attention lately. Existing attack methods on LLMs inherit the extraction strategies from those designed for deep neural networks (DNNs) yet neglect the inconsistency of training tasks between MEA and LLMs' alignments. As such, they result in poor attack performances. To tackle this issue, we present Locality Reinforced Distillation (LoRD), a novel model extraction attack algorithm specifically for LLMs. In particular, we design a policy-gradient-style training task, which utilizes victim models' responses as a signal to guide the crafting of preference for the local model. Theoretical analysis has shown that i) LoRD's convergence procedure in MEAs is consistent with the alignments of LLMs, and ii) LoRD can reduce query complexity while mitigating watermark protection through exploration-based stealing. Extensive experiments on domain-specific extractions demonstrate the superiority of our method by examining the extraction of various state-of-the-art commercial LLMs.
Meta Pattern Concern Score: A Novel Metric for Customizable Evaluation of Multi-classification
Sep 14, 2022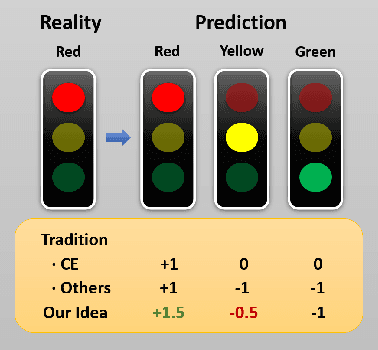
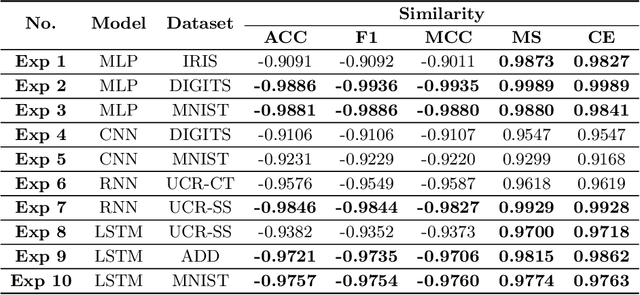

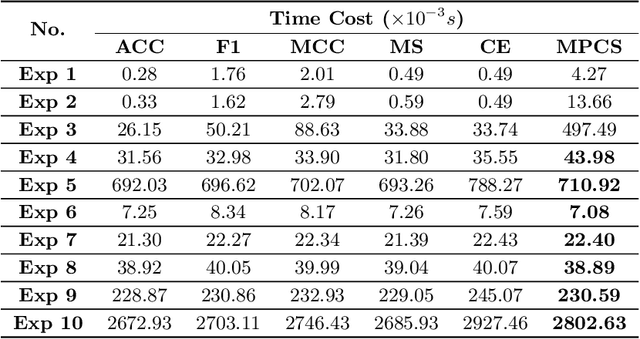
Classifiers have been widely implemented in practice, while how to evaluate them properly remains a problem. Commonly used two types of metrics respectively based on confusion matrix and loss function have different advantages in flexibility and mathematical completeness, while they struggle in different dilemmas like the insensitivity to slight improvements or the lack of customizability in different tasks. In this paper, we propose a novel metric named Meta Pattern Concern Score based on the abstract representation of the probabilistic prediction, as well as the targeted design for processing negative classes in multi-classification and reducing the discreteness of metric value, to achieve advantages of both the two kinds of metrics and avoid their weaknesses. Our metric provides customizability to pick out the model for specific requirements in different practices, and make sure it is also fine under traditional metrics at the same time. Evaluation in four kinds of models and six datasets demonstrates the effectiveness and efficiency of our metric, and a case study shows it can select a model to reduce 0.53% of dangerous misclassifications by sacrificing only 0.04% of training accuracy.
TSFool: Crafting High-quality Adversarial Time Series through Multi-objective Optimization to Fool Recurrent Neural Network Classifiers
Sep 14, 2022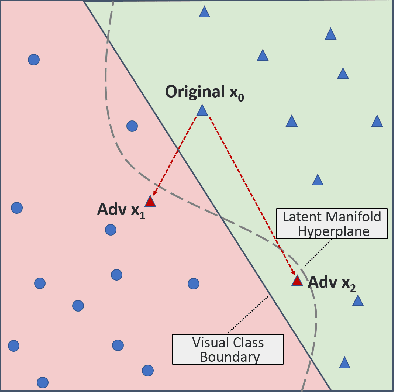
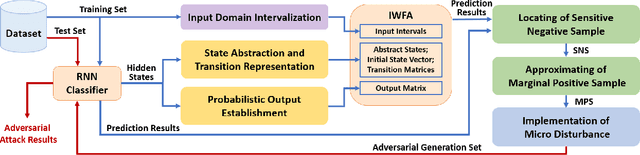
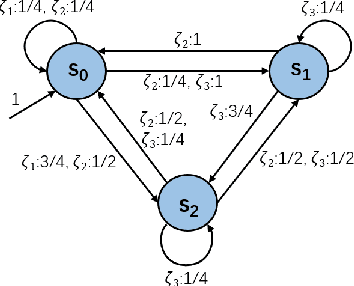
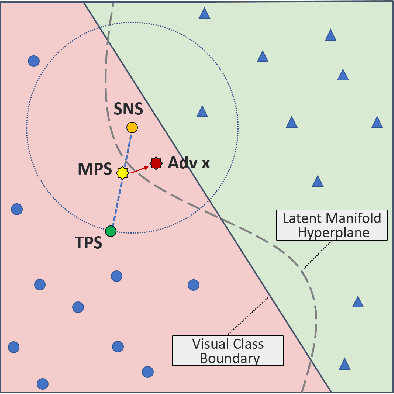
Deep neural network (DNN) classifiers are vulnerable to adversarial attacks. Although the existing gradient-based attacks have achieved good performance in feed-forward model and image recognition tasks, the extension for time series classification in the recurrent neural network (RNN) remains a dilemma, because the cyclical structure of RNN prevents direct model differentiation and the visual sensitivity to perturbations of time series data challenges the traditional local optimization objective to minimize perturbation. In this paper, an efficient and widely applicable approach called TSFool for crafting high-quality adversarial time series for the RNN classifier is proposed. We propose a novel global optimization objective named Camouflage Coefficient to consider how well the adversarial samples hide in class clusters, and accordingly redefine the high-quality adversarial attack as a multi-objective optimization problem. We also propose a new idea to use intervalized weighted finite automata (IWFA) to capture deeply embedded vulnerable samples having otherness between features and latent manifold to guide the approximation to the optimization solution. Experiments on 22 UCR datasets are conducted to confirm that TSFool is a widely effective, efficient and high-quality approach with 93.22% less local perturbation, 32.33% better global camouflage, and 1.12 times speedup to existing methods.