 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-Aware Regularized Quantization Calibration for Large Language Models
May 07, 2026Post-training quantization (PTQ) is an effective approach for deploying large language models (LLMs) under memory and latency constraints. Most existing PTQ methods determine quantization parameters by minimizing a layer-wise reconstruction error on a predetermined calibration dataset, usually optimized via either scale search or Gram-based methods. However, from the perspective of generalization risk, existing calibration objectives of PTQ based only on empirical reconstruction error on limited or unrepresentative calibration data could move the quantized weights away from the original weights. This may cause the generalization risk to diverge, potentially degrading downstream performance. To address this issue, we propose \emph{Saliency-Aware Regularized Quantization Calibration} (SARQC) a unified framework that augments the standard PTQ objective with a saliency-aware regularization term. This term encourages quantized weights to stay close to the original weights during calibration, leading to improved generalization during inference. SARQC integrates seamlessly into existing PTQ pipelines, enhancing both scale search and Gram-based methods under a unified formulation. Extensive experiments on dense and Mixture-of-Experts LLMs demonstrate consistent improvements in perplexity and zero-shot accuracy, without additional computational overhead during inference.
MetaHGNIE: Meta-Path Induced Hypergraph Contrastive Learning in Heterogeneous Knowledge Graphs
Dec 13, 2025Node importance estimation (NIE) in heterogeneous knowledge graphs is a critical yet challenging task, essential for applications such as recommendation, knowledge reasoning, and question answering. Existing methods often rely on pairwise connections, neglecting high-order dependencies among multiple entities and relations, and they treat structural and semantic signals independently, hindering effective cross-modal integration. To address these challenges, we propose MetaHGNIE, a meta-path induced hypergraph contrastive learning framework for disentangling and aligning structural and semantic information. MetaHGNIE constructs a higher-order knowledge graph via meta-path sequences, where typed hyperedges capture multi-entity relational contexts. Structural dependencies are aggregated with local attention, while semantic representations are encoded through a hypergraph transformer equipped with sparse chunking to reduce redundancy. Finally, a multimodal fusion module integrates structural and semantic embeddings under contrastive learning with auxiliary supervision, ensuring robust cross-modal alignment. Extensive experiments on benchmark NIE datasets demonstrate that MetaHGNIE consistently outperforms state-of-the-art baselines. These results highlight the effectiveness of explicitly modeling higher-order interactions and cross-modal alignment in heterogeneous knowledge graphs. Our code is available at https://github.com/SEU-WENJIA/DualHNIE
Consensus-Based Distributed Nonlinear Filtering with Kernel Mean Embedding
Dec 04, 2023This paper proposes a consensus-based distributed nonlinear filter with kernel mean embedding (KME). This fills with gap of posterior density approximation with KME for distributed nonlinear dynamic systems. To approximate the posterior density, the system state is embedded into a higher-dimensional reproducing kernel Hilbert space (RKHS), and then the nonlinear measurement function is linearly converted. As a result, an update rule of KME of posterior distribution is established in the RKHS. To show the proposed distributed filter being capable of achieving the centralized estimation accuracy, a centralized filter, serving as an extension of the standard Kalman filter in the state space to the RKHS, is developed first. Benefited from the KME, the proposed distributed filter converges to the centralized one while maintaining the distributed pattern. Two examples are introduced to demonstrate the effectiveness of the developed filters in target tracking scenarios including nearly constantly moving target and turning target, respectively, with bearing-only, range and bearing measurements.
Identification and Adaptation with Binary-Valued Observations under Non-Persistent Excitation Condition
Jul 08, 2021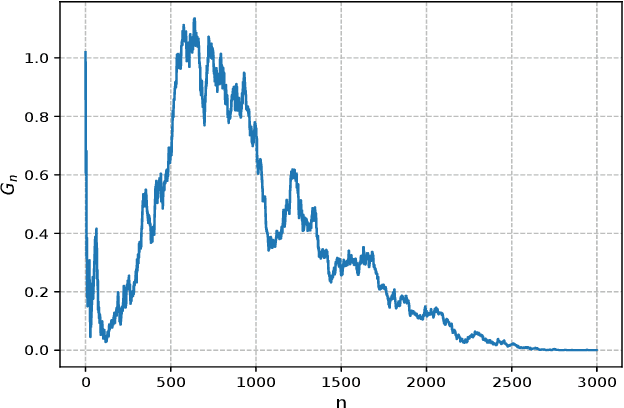
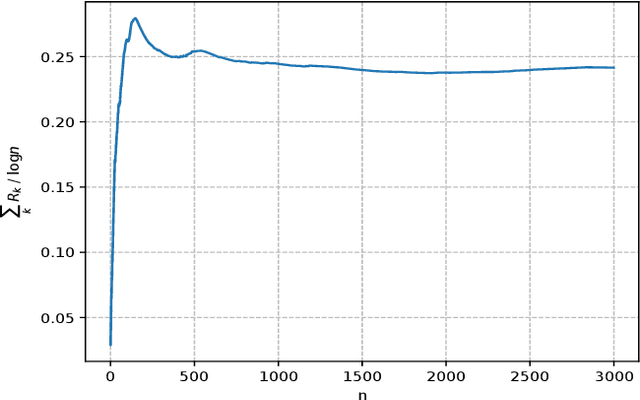
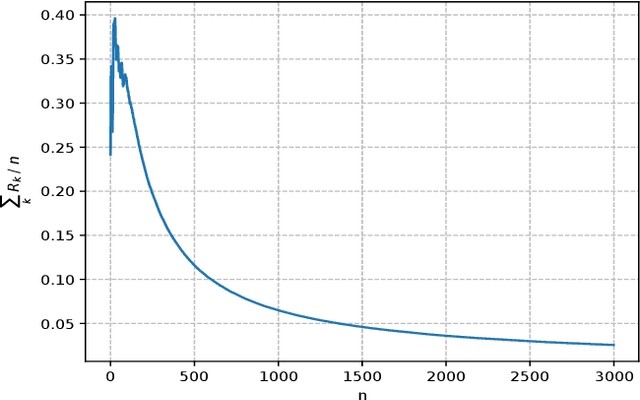
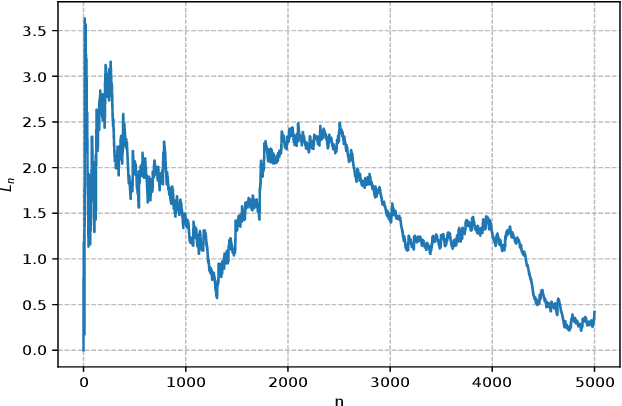
Dynamical systems with binary-valued observations are widely used in information industry, technology of biological pharmacy and other fields. Though there have been much efforts devoted to the identification of such systems, most of the previous investigations are based on first-order gradient algorithm which usually has much slower convergence rate than the Quasi-Newton algorithm. Moreover, persistence of excitation(PE) conditions are usually required to guarantee consistent parameter estimates in the existing literature, which are hard to be verified or guaranteed for feedback control systems. In this paper, we propose an online projected Quasi-Newton type algorithm for parameter estimation of stochastic regression models with binary-valued observations and varying thresholds. By using both the stochastic Lyapunov function and martingale estimation methods, we establish the strong consistency of the estimation algorithm and provide the convergence rate, under a signal condition which is considerably weaker than the traditional PE condition and coincides with the weakest possible excitation known for the classical least square algorithm of stochastic regression models. Convergence of adaptive predictors and their applications in adaptive control are also discussed.