 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Similarity: Trustworthy Memory Search for Personal AI Agents
Jun 04, 2026Personal AI agents increasingly rely on long-term memory to provide persistent personalization across sessions. However, existing memory pipelines are largely driven by semantic similarity: memory data close to the current query is retrieved and injected into the model context. This creates a critical trustworthiness gap, since a semantically related memory may still be contextually inappropriate, leading to threats such as cross-domain leakage, sycophancy, tool-call drift, or memory-induced jailbreaks. In this paper, we study memory search as a trust boundary in personal AI agents. We evaluate representative agentic memory frameworks, including A-Mem, Mem0, and MemOS, together with OpenClaw, a real-world personal-agent environment with persistent state and tool-use capability. Our results show that long-term memory is not merely a utility layer, but a durable control channel that can reshape how agents interpret tasks and execute actions, leaving them highly susceptible to the aforementioned threats. To mitigate these vulnerabilities, we propose MemGate, a lightweight and deployable memory plug-in for trustworthy memory search, with only 9M parameters and a 35.1MB footprint. MemGate is inserted between the vector memory store and the backbone LLM, requiring no LLM modification, memory-database rewriting, or inference-time LLM judge. It applies a query-conditioned neural gate to candidate memory representations, turning raw similarity search into task-conditioned memory admission. Across multiple mainstream memory frameworks, real-world agent settings, and diverse LLM backbones, MemGate reduces memory-induced threats while preserving long-term memory utility.
Understanding and Preserving Safety in Fine-Tuned LLMs
Jan 15, 2026Fine-tuning is an essential and pervasive functionality for applying large language models (LLMs) to downstream tasks. However, it has the potential to substantially degrade safety alignment, e.g., by greatly increasing susceptibility to jailbreak attacks, even when the fine-tuning data is entirely harmless. Despite garnering growing attention in defense efforts during the fine-tuning stage, existing methods struggle with a persistent safety-utility dilemma: emphasizing safety compromises task performance, whereas prioritizing utility typically requires deep fine-tuning that inevitably leads to steep safety declination. In this work, we address this dilemma by shedding new light on the geometric interaction between safety- and utility-oriented gradients in safety-aligned LLMs. Through systematic empirical analysis, we uncover three key insights: (I) safety gradients lie in a low-rank subspace, while utility gradients span a broader high-dimensional space; (II) these subspaces are often negatively correlated, causing directional conflicts during fine-tuning; and (III) the dominant safety direction can be efficiently estimated from a single sample. Building upon these novel insights, we propose safety-preserving fine-tuning (SPF), a lightweight approach that explicitly removes gradient components conflicting with the low-rank safety subspace. Theoretically, we show that SPF guarantees utility convergence while bounding safety drift. Empirically, SPF consistently maintains downstream task performance and recovers nearly all pre-trained safety alignment, even under adversarial fine-tuning scenarios. Furthermore, SPF exhibits robust resistance to both deep fine-tuning and dynamic jailbreak attacks. Together, our findings provide new mechanistic understanding and practical guidance toward always-aligned LLM fine-tuning.
AVM: Towards Structure-Preserving Neural Response Modeling in the Visual Cortex Across Stimuli and Individuals
Dec 17, 2025While deep learning models have shown strong performance in simulating neural responses, they often fail to clearly separate stable visual encoding from condition-specific adaptation, which limits their ability to generalize across stimuli and individuals. We introduce the Adaptive Visual Model (AVM), a structure-preserving framework that enables condition-aware adaptation through modular subnetworks, without modifying the core representation. AVM keeps a Vision Transformer-based encoder frozen to capture consistent visual features, while independently trained modulation paths account for neural response variations driven by stimulus content and subject identity. We evaluate AVM in three experimental settings, including stimulus-level variation, cross-subject generalization, and cross-dataset adaptation, all of which involve structured changes in inputs and individuals. Across two large-scale mouse V1 datasets, AVM outperforms the state-of-the-art V1T model by approximately 2% in predictive correlation, demonstrating robust generalization, interpretable condition-wise modulation, and high architectural efficiency. Specifically, AVM achieves a 9.1% improvement in explained variance (FEVE) under the cross-dataset adaptation setting. These results suggest that AVM provides a unified framework for adaptive neural modeling across biological and experimental conditions, offering a scalable solution under structural constraints. Its design may inform future approaches to cortical modeling in both neuroscience and biologically inspired AI systems.
Fast-SNN: Fast Spiking Neural Network by Converting Quantized ANN
May 31, 2023Spiking neural networks (SNNs) have shown advantages in computation and energy efficiency over traditional artificial neural networks (ANNs) thanks to their event-driven representations. SNNs also replace weight multiplications in ANNs with additions, which are more energy-efficient and less computationally intensive. However, it remains a challenge to train deep SNNs due to the discrete spike function. A popular approach to circumvent this challenge is ANN-to-SNN conversion. However, due to the quantization error and accumulating error, it often requires lots of time steps (high inference latency) to achieve high performance, which negates SNN's advantages. To this end, this paper proposes Fast-SNN that achieves high performance with low latency. We demonstrate the equivalent mapping between temporal quantization in SNNs and spatial quantization in ANNs, based on which the minimization of the quantization error is transferred to quantized ANN training. With the minimization of the quantization error, we show that the sequential error is the primary cause of the accumulating error, which is addressed by introducing a signed IF neuron model and a layer-wise fine-tuning mechanism. Our method achieves state-of-the-art performance and low latency on various computer vision tasks, including image classification, object detection, and semantic segmentation. Codes are available at: https://github.com/yangfan-hu/Fast-SNN.
Spiking Deep Residual Network
Apr 28, 2018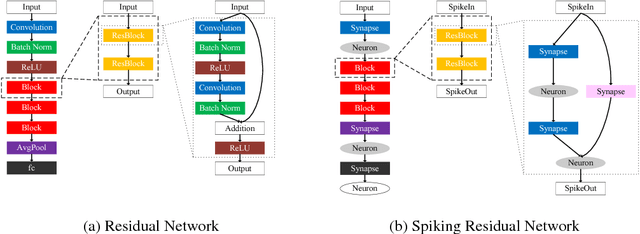
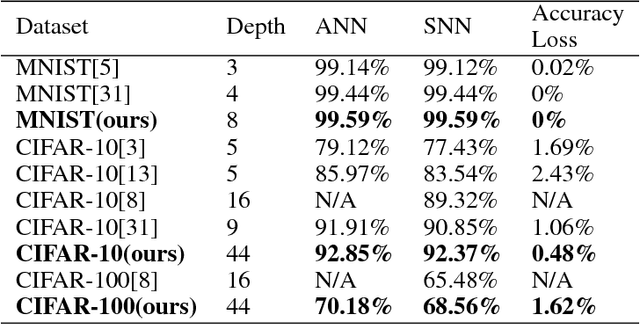
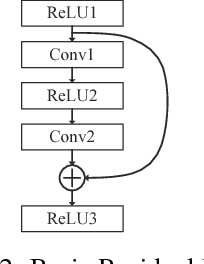
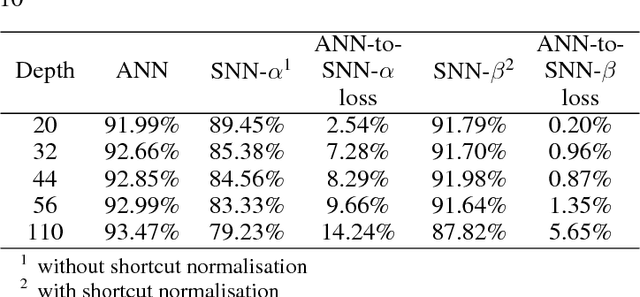
Recently, spiking neural network (SNN) has received significant attentions for its biological plausibility. SNN theoretically has at least the same computational power as traditional artificial neural networks (ANNs), and it has the potential to achieve revolutionary energy-efficiency. However, at current stage, it is still a big challenge to train a very deep SNN. In this paper, we propose an efficient approach to build a spiking version of deep residual network (ResNet), which represents the state-of-the-art convolutional neural networks (CNNs). We employ the idea of converting a trained ResNet to a network of spiking neurons named Spiking ResNet. To address the conversion problem, we propose a shortcut normalisation mechanism to appropriately scale continuous-valued activations to match firing rates in SNN, and a layer-wise error compensation approach to reduce the error caused by discretisation. Experimental results on MNIST, CIFAR-10, and CIFAR-100 demonstrate that the proposed Spiking ResNet yields the state-of-the-art performance of SNNs.