 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Diffusion-based Augmentation for Recommendation
Jan 04, 2026Recommendation systems often rely on implicit feedback, where only positive user-item interactions can be observed. Negative sampling is therefore crucial to provide proper negative training signals. However, existing methods tend to mislabel potentially positive but unobserved items as negatives and lack precise control over negative sample selection. We aim to address these by generating controllable negative samples, rather than sampling from the existing item pool. In this context, we propose Adaptive Diffusion-based Augmentation for Recommendation (ADAR), a novel and model-agnostic module that leverages diffusion to synthesize informative negatives. Inspired by the progressive corruption process in diffusion, ADAR simulates a continuous transition from positive to negative, allowing for fine-grained control over sample hardness. To mine suitable negative samples, we theoretically identify the transition point at which a positive sample turns negative and derive a score-aware function to adaptively determine the optimal sampling timestep. By identifying this transition point, ADAR generates challenging negative samples that effectively refine the model's decision boundary. Experiments confirm that ADAR is broadly compatible and boosts the performance of existing recommendation models substantially, including collaborative filtering and sequential recommendation, without architectural modifications.
FxTS-Net: Fixed-Time Stable Learning Framework for Neural ODEs
Nov 14, 2024



Neural Ordinary Differential Equations (Neural ODEs), as a novel category of modeling big data methods, cleverly link traditional neural networks and dynamical systems. However, it is challenging to ensure the dynamics system reaches a correctly predicted state within a user-defined fixed time. To address this problem, we propose a new method for training Neural ODEs using fixed-time stability (FxTS) Lyapunov conditions. Our framework, called FxTS-Net, is based on the novel FxTS loss (FxTS-Loss) designed on Lyapunov functions, which aims to encourage convergence to accurate predictions in a user-defined fixed time. We also provide an innovative approach for constructing Lyapunov functions to meet various tasks and network architecture requirements, achieved by leveraging supervised information during training. By developing a more precise time upper bound estimation for bounded non-vanishingly perturbed systems, we demonstrate that minimizing FxTS-Loss not only guarantees FxTS behavior of the dynamics but also input perturbation robustness. For optimising FxTS-Loss, we also propose a learning algorithm, in which the simulated perturbation sampling method can capture sample points in critical regions to approximate FxTS-Loss. Experimentally, we find that FxTS-Net provides better prediction performance and better robustness under input perturbation.
Transfer Learning in Vocal Education: Technical Evaluation of Limited Samples Describing Mezzo-soprano
Oct 30, 2024



Vocal education in the music field is difficult to quantify due to the individual differences in singers' voices and the different quantitative criteria of singing techniques. Deep learning has great potential to be applied in music education due to its efficiency to handle complex data and perform quantitative analysis. However, accurate evaluations with limited samples over rare vocal types, such as Mezzo-soprano, requires extensive well-annotated data support using deep learning models. In order to attain the objective, we perform transfer learning by employing deep learning models pre-trained on the ImageNet and Urbansound8k datasets for the improvement on the precision of vocal technique evaluation. Furthermore, we tackle the problem of the lack of samples by constructing a dedicated dataset, the Mezzo-soprano Vocal Set (MVS), for vocal technique assessment. Our experimental results indicate that transfer learning increases the overall accuracy (OAcc) of all models by an average of 8.3%, with the highest accuracy at 94.2%. We not only provide a novel approach to evaluating Mezzo-soprano vocal techniques but also introduce a new quantitative assessment method for music education.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020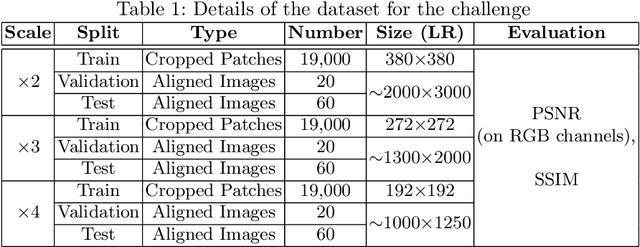
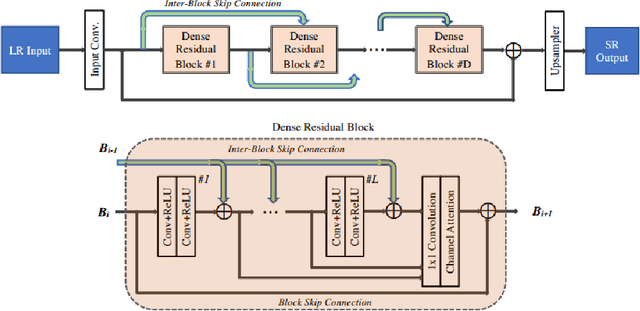
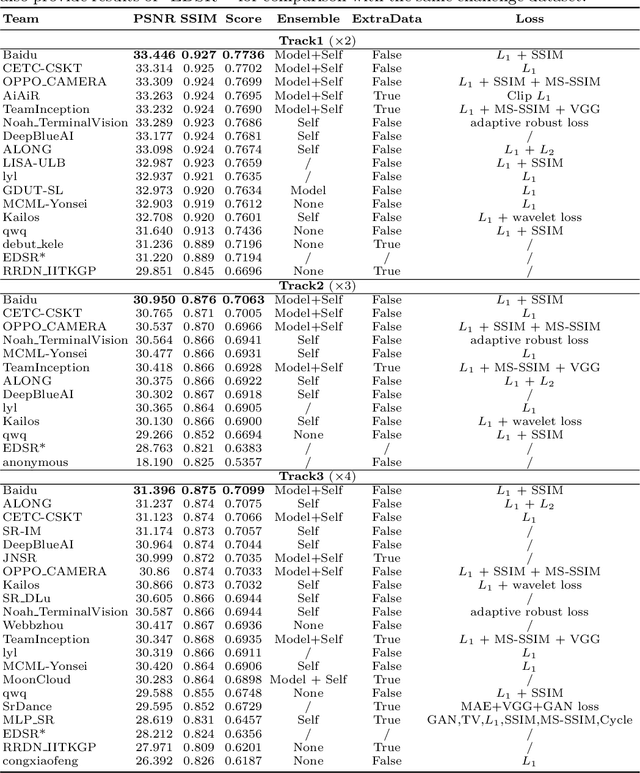
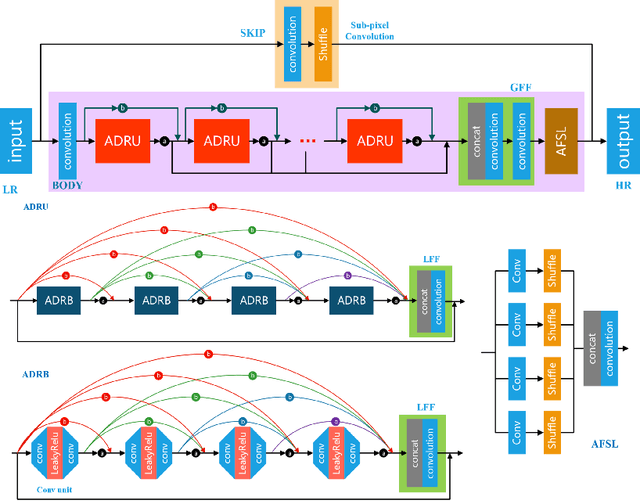
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.