 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIT: Position-Invariant Transform for Cross-FoV Domain Adaptation
Aug 16, 2021
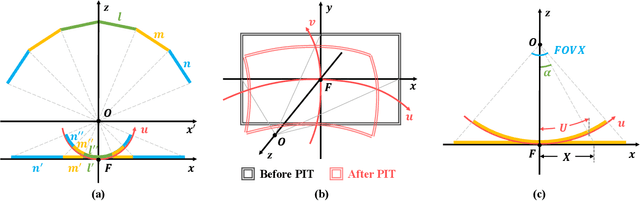
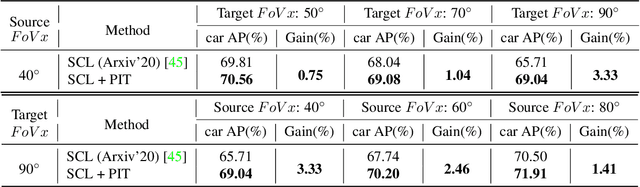
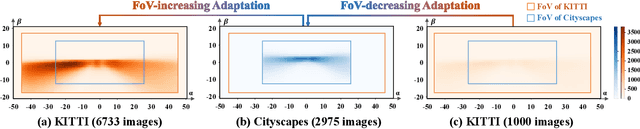
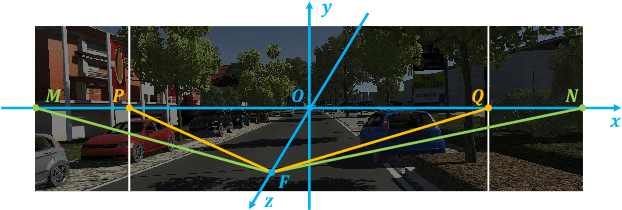
Cross-domain object detection and semantic segmentation have witnessed impressive progress recently. Existing approaches mainly consider the domain shift resulting from external environments including the changes of background, illumination or weather, while distinct camera intrinsic parameters appear commonly in different domains, and their influence for domain adaptation has been very rarely explored. In this paper, we observe that the Field of View (FoV) gap induces noticeable instance appearance differences between the source and target domains. We further discover that the FoV gap between two domains impairs domain adaptation performance under both the FoV-increasing (source FoV < target FoV) and FoV-decreasing cases. Motivated by the observations, we propose the \textbf{Position-Invariant Transform} (PIT) to better align images in different domains. We also introduce a reverse PIT for mapping the transformed/aligned images back to the original image space and design a loss re-weighting strategy to accelerate the training process. Our method can be easily plugged into existing cross-domain detection/segmentation frameworks while bringing about negligible computational overhead. Extensive experiments demonstrate that our method can soundly boost the performance on both cross-domain object detection and segmentation for state-of-the-art techniques. Our code is available at https://github.com/sheepooo/PIT-Position-Invariant-Transform.
Self-Adversarial Disentangling for Specific Domain Adaptation
Aug 11, 2021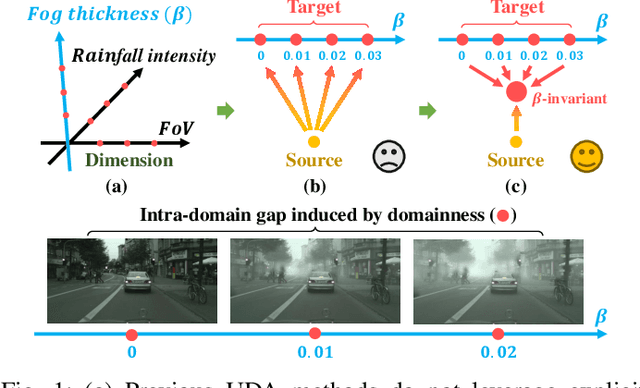
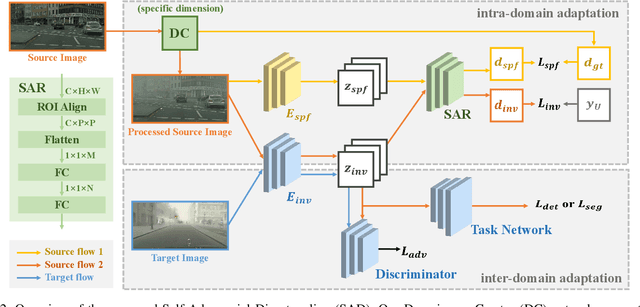

Domain adaptation aims to bridge the domain shifts between the source and target domains. These shifts may span different dimensions such as fog, rainfall, etc. However, recent methods typically do not consider explicit prior knowledge on a specific dimension, thus leading to less desired adaptation performance. In this paper, we study a practical setting called Specific Domain Adaptation (SDA) that aligns the source and target domains in a demanded-specific dimension. Within this setting, we observe the intra-domain gap induced by different domainness (i.e., numerical magnitudes of this dimension) is crucial when adapting to a specific domain. To address the problem, we propose a novel Self-Adversarial Disentangling (SAD) framework. In particular, given a specific dimension, we first enrich the source domain by introducing a domainness creator with providing additional supervisory signals. Guided by the created domainness, we design a self-adversarial regularizer and two loss functions to jointly disentangle the latent representations into domainness-specific and domainness-invariant features, thus mitigating the intra-domain gap. Our method can be easily taken as a plug-and-play framework and does not introduce any extra costs in the inference time. We achieve consistent improvements over state-of-the-art methods in both object detection and semantic segmentation tasks.
Context-Aware Mixup for Domain Adaptive Semantic Segmentation
Aug 11, 2021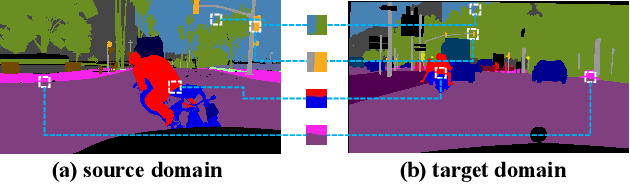
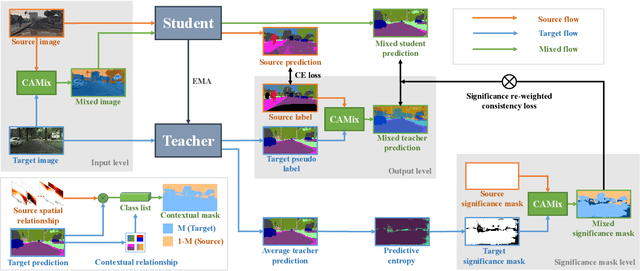

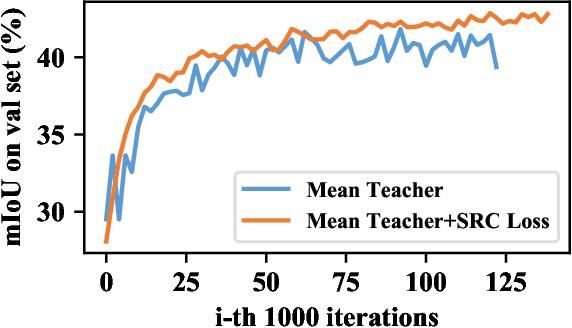
Unsupervised domain adaptation (UDA) aims to adapt a model of the labeled source domain to an unlabeled target domain. Although the domain shifts may exist in various dimensions such as appearance, textures, etc, the contextual dependency, which is generally shared across different domains, is neglected by recent methods. In this paper, we utilize this important clue as explicit prior knowledge and propose end-to-end Context-Aware Mixup (CAMix) for domain adaptive semantic segmentation. Firstly, we design a contextual mask generation strategy by leveraging accumulated spatial distributions and contextual relationships. The generated contextual mask is critical in this work and will guide the domain mixup. In addition, we define the significance mask to indicate where the pixels are credible. To alleviate the over-alignment (e.g., early performance degradation), the source and target significance masks are mixed based on the contextual mask into the mixed significance mask, and we introduce a significance-reweighted consistency loss on it. Experimental results show that the proposed method outperforms the state-of-the-art methods by a large margin on two widely-used domain adaptation benchmarks, i.e., GTAV $\rightarrow $ Cityscapes and SYNTHIA $\rightarrow $ Cityscapes.
Image Deformation Estimation via Multi-Objective Optimization
Jun 08, 2021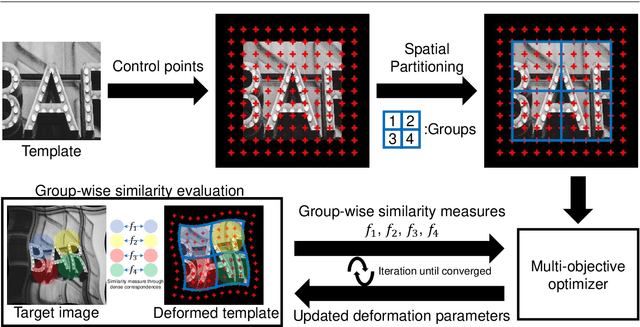
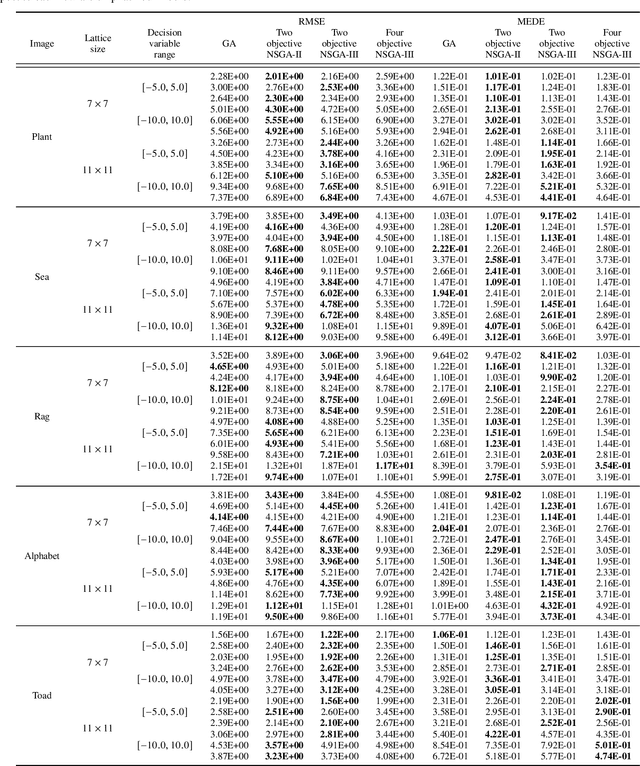
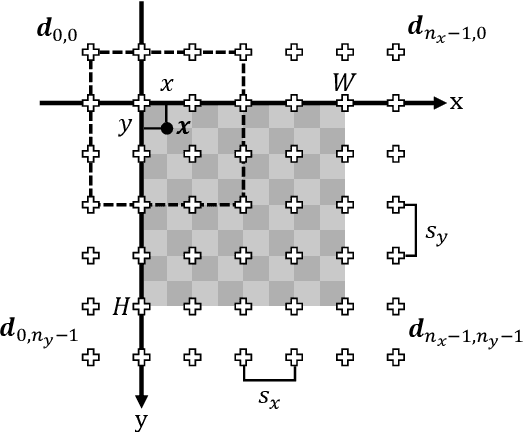

The free-form deformation model can represent a wide range of non-rigid deformations by manipulating a control point lattice over the image. However, due to a large number of parameters, it is challenging to fit the free-form deformation model directly to the deformed image for deformation estimation because of the complexity of the fitness landscape. In this paper, we cast the registration task as a multi-objective optimization problem (MOP) according to the fact that regions affected by each control point overlap with each other. Specifically, by partitioning the template image into several regions and measuring the similarity of each region independently, multiple objectives are built and deformation estimation can thus be realized by solving the MOP with off-the-shelf multi-objective evolutionary algorithms (MOEAs). In addition, a coarse-to-fine strategy is realized by image pyramid combined with control point mesh subdivision. Specifically, the optimized candidate solutions of the current image level are inherited by the next level, which increases the ability to deal with large deformation. Also, a post-processing procedure is proposed to generate a single output utilizing the Pareto optimal solutions. Comparative experiments on both synthetic and real-world images show the effectiveness and usefulness of our deformation estimation method.
DeepfakeUCL: Deepfake Detection via Unsupervised Contrastive Learning
Apr 23, 2021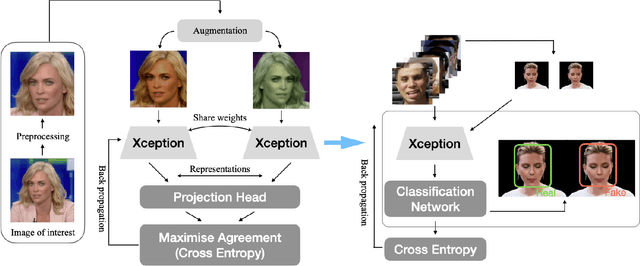
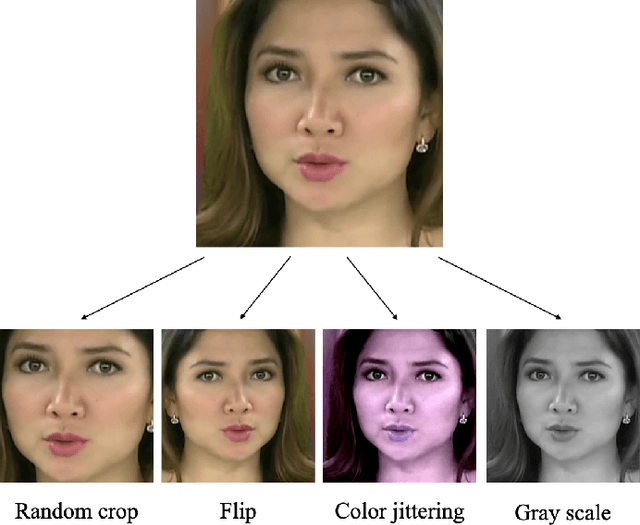

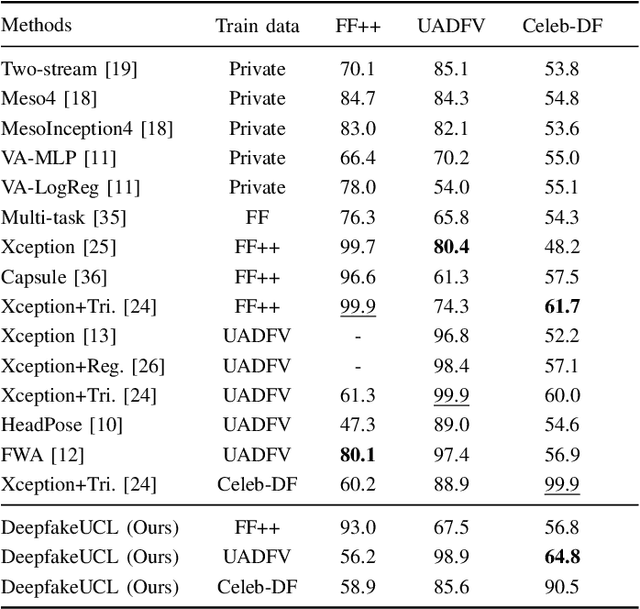
Face deepfake detection has seen impressive results recently. Nearly all existing deep learning techniques for face deepfake detection are fully supervised and require labels during training. In this paper, we design a novel deepfake detection method via unsupervised contrastive learning. We first generate two different transformed versions of an image and feed them into two sequential sub-networks, i.e., an encoder and a projection head. The unsupervised training is achieved by maximizing the correspondence degree of the outputs of the projection head. To evaluate the detection performance of our unsupervised method, we further use the unsupervised features to train an efficient linear classification network. Extensive experiments show that our unsupervised learning method enables comparable detection performance to state-of-the-art supervised techniques, in both the intra- and inter-dataset settings. We also conduct ablation studies for our method.
I-Nema: A Biological Image Dataset for Nematode Recognition
Mar 15, 2021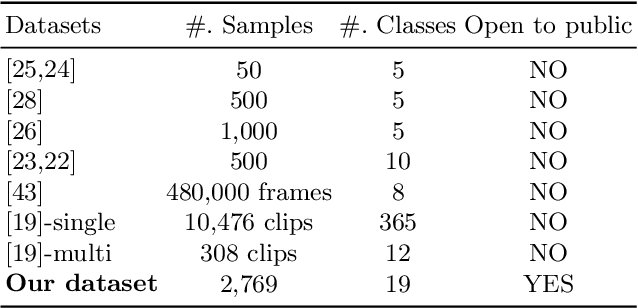
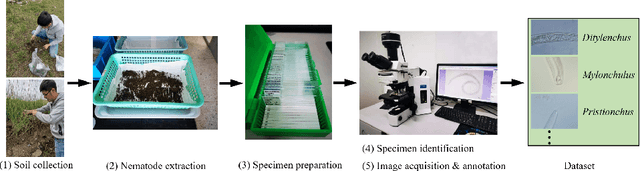
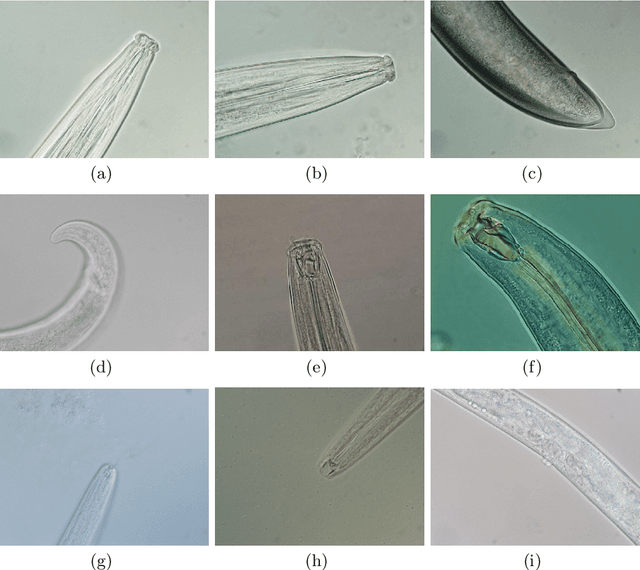
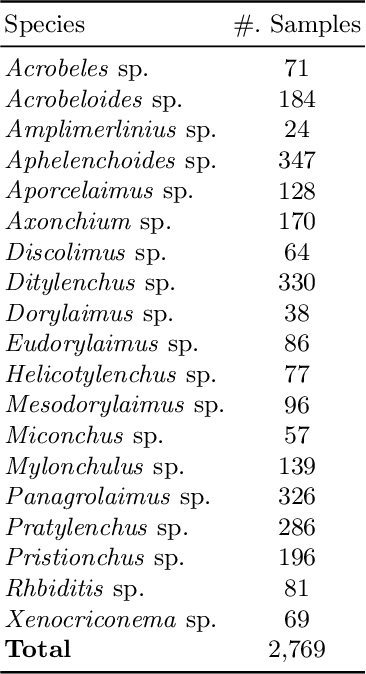
Nematode worms are one of most abundant metazoan groups on the earth, occupying diverse ecological niches. Accurate recognition or identification of nematodes are of great importance for pest control, soil ecology, bio-geography, habitat conservation and against climate changes. Computer vision and image processing have witnessed a few successes in species recognition of nematodes; however, it is still in great demand. In this paper, we identify two main bottlenecks: (1) the lack of a publicly available imaging dataset for diverse species of nematodes (especially the species only found in natural environment) which requires considerable human resources in field work and experts in taxonomy, and (2) the lack of a standard benchmark of state-of-the-art deep learning techniques on this dataset which demands the discipline background in computer science. With these in mind, we propose an image dataset consisting of diverse nematodes (both laboratory cultured and naturally isolated), which, to our knowledge, is the first time in the community. We further set up a species recognition benchmark by employing state-of-the-art deep learning networks on this dataset. We discuss the experimental results, compare the recognition accuracy of different networks, and show the challenges of our dataset. We make our dataset publicly available at: https://github.com/xuequanlu/I-Nema
Chaotic-to-Fine Clustering for Unlabeled Plant Disease Images
Jan 18, 2021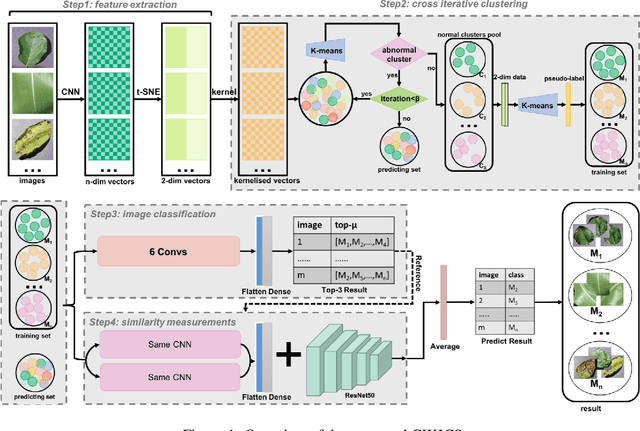
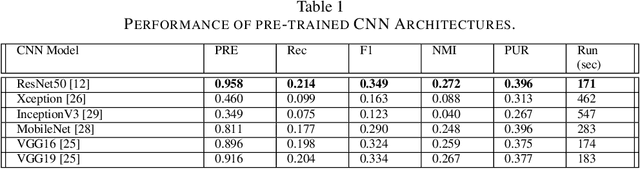
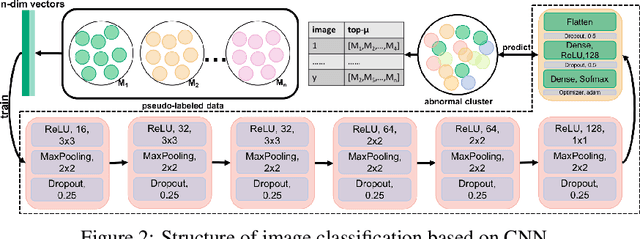

Current annotation for plant disease images depends on manual sorting and handcrafted features by agricultural experts, which is time-consuming and labour-intensive. In this paper, we propose a self-supervised clustering framework for grouping plant disease images based on the vulnerability of Kernel K-means. The main idea is to establish a cross iterative under-clustering algorithm based on Kernel K-means to produce the pseudo-labeled training set and a chaotic cluster to be further classified by a deep learning module. In order to verify the effectiveness of our proposed framework, we conduct extensive experiments on three different plant disease datatsets with five plants and 17 plant diseases. The experimental results show the high superiority of our method to do image-based plant disease classification over balanced and unbalanced datasets by comparing with five state-of-the-art existing works in terms of different metrics.
Deep Detection for Face Manipulation
Sep 13, 2020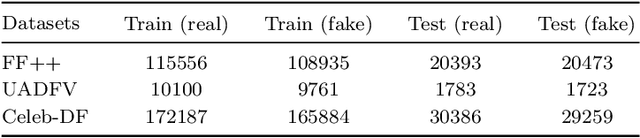
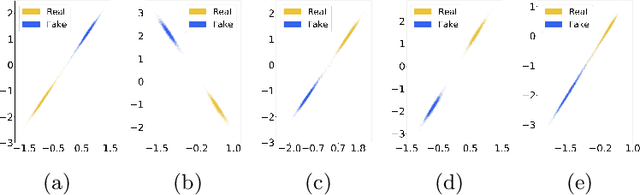

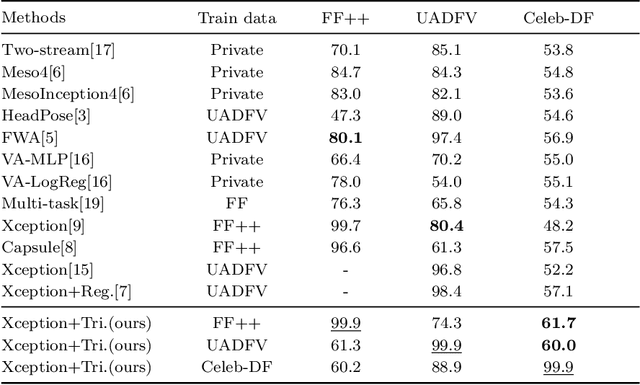
It has become increasingly challenging to distinguish real faces from their visually realistic fake counterparts, due to the great advances of deep learning based face manipulation techniques in recent years. In this paper, we introduce a deep learning method to detect face manipulation. It consists of two stages: feature extraction and binary classification. To better distinguish fake faces from real faces, we resort to the triplet loss function in the first stage. We then design a simple linear classification network to bridge the learned contrastive features with the real/fake faces. Experimental results on public benchmark datasets demonstrate the effectiveness of this method, and show that it generates better performance than state-of-the-art techniques in most cases.
Continuous Color Transfer
Aug 31, 2020

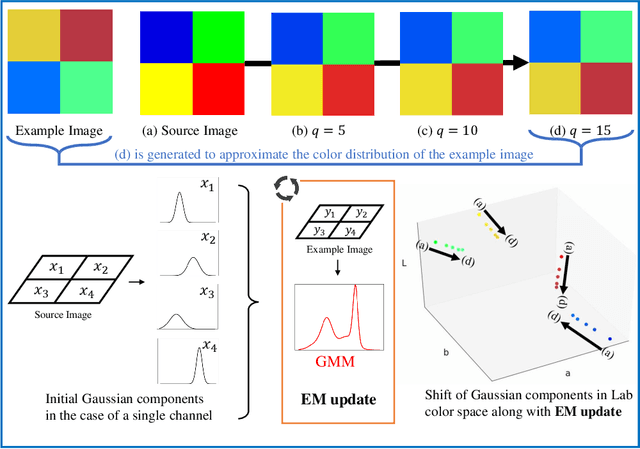

Color transfer, which plays a key role in image editing, has attracted noticeable attention recently. It has remained a challenge to date due to various issues such as time-consuming manual adjustments and prior segmentation issues. In this paper, we propose to model color transfer under a probability framework and cast it as a parameter estimation problem. In particular, we relate the transferred image with the example image under the Gaussian Mixture Model (GMM) and regard the transferred image color as the GMM centroids. We employ the Expectation-Maximization (EM) algorithm (E-step and M-step) for optimization. To better preserve gradient information, we introduce a Laplacian based regularization term to the objective function at the M-step which is solved by deriving a gradient descent algorithm. Given the input of a source image and an example image, our method is able to generate continuous color transfer results with increasing EM iterations. Various experiments show that our approach generally outperforms other competitive color transfer methods, both visually and quantitatively.
Deep Patch-based Human Segmentation
Jul 11, 2020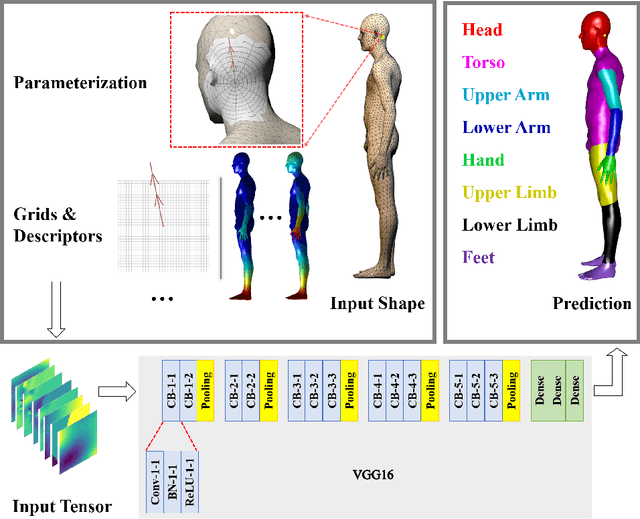
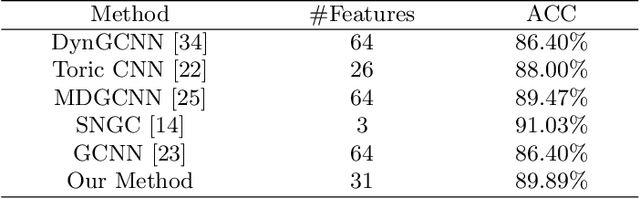
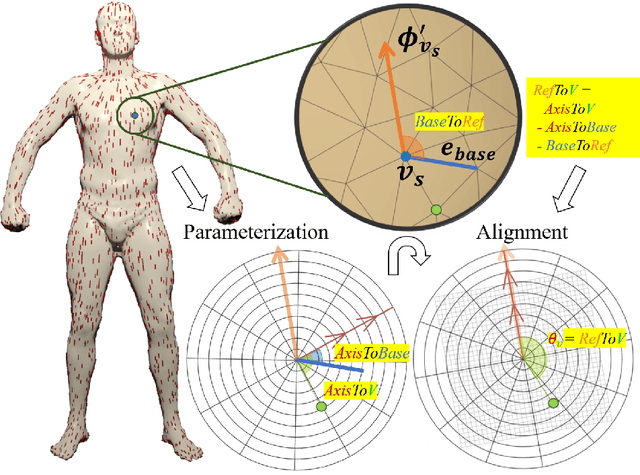

3D human segmentation has seen noticeable progress in re-cent years. It, however, still remains a challenge to date. In this paper, weintroduce a deep patch-based method for 3D human segmentation. Wefirst extract a local surface patch for each vertex and then parameterizeit into a 2D grid (or image). We then embed identified shape descriptorsinto the 2D grids which are further fed into the powerful 2D Convolu-tional Neural Network for regressing corresponding semantic labels (e.g.,head, torso). Experiments demonstrate that our method is effective inhuman segmentation, and achieves state-of-the-art accuracy.