 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent and Context Features for Scene Image Representation
Jun 05, 2020
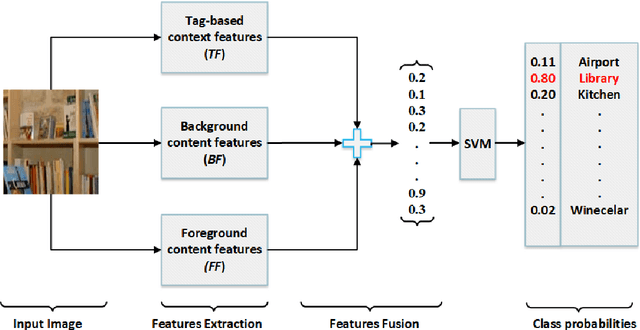
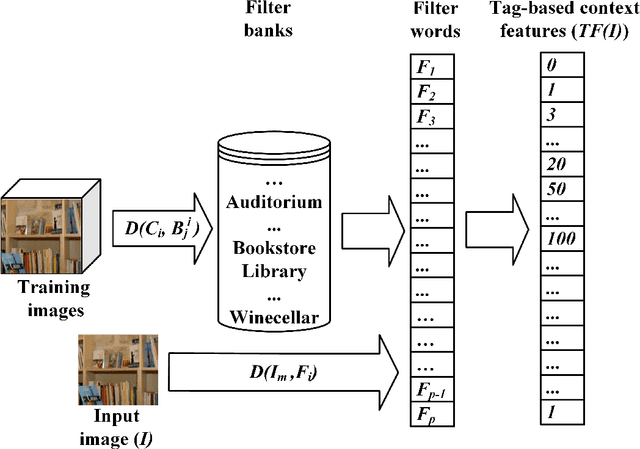
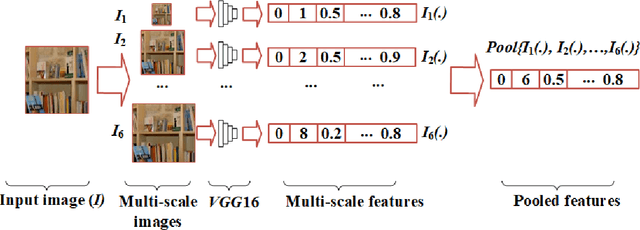
Existing research in scene image classification has focused on either content features (e.g., visual information) or context features (e.g., annotations). As they capture different information about images which can be complementary and useful to discriminate images of different classes, we suppose the fusion of them will improve classification results. In this paper, we propose new techniques to compute content features and context features, and then fuse them together. For content features, we design multi-scale deep features based on background and foreground information in images. For context features, we use annotations of similar images available in the web to design a filter words (codebook). Our experiments in three widely used benchmark scene datasets using support vector machine classifier reveal that our proposed context and content features produce better results than existing context and content features, respectively. The fusion of the proposed two types of features significantly outperform numerous state-of-the-art features.
HDF: Hybrid Deep Features for Scene Image Representation
Mar 22, 2020
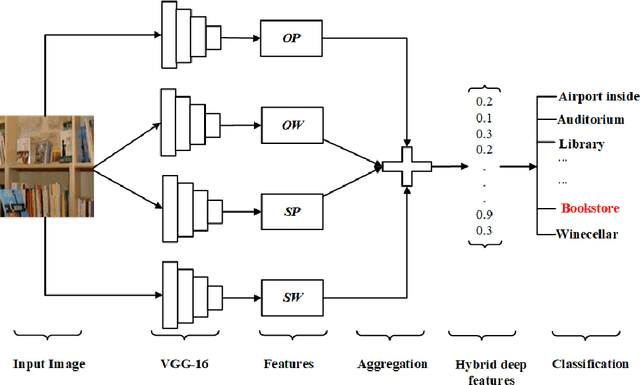


Nowadays it is prevalent to take features extracted from pre-trained deep learning models as image representations which have achieved promising classification performance. Existing methods usually consider either object-based features or scene-based features only. However, both types of features are important for complex images like scene images, as they can complement each other. In this paper, we propose a novel type of features -- hybrid deep features, for scene images. Specifically, we exploit both object-based and scene-based features at two levels: part image level (i.e., parts of an image) and whole image level (i.e., a whole image), which produces a total number of four types of deep features. Regarding the part image level, we also propose two new slicing techniques to extract part based features. Finally, we aggregate these four types of deep features via the concatenation operator. We demonstrate the effectiveness of our hybrid deep features on three commonly used scene datasets (MIT-67, Scene-15, and Event-8), in terms of the scene image classification task. Extensive comparisons show that our introduced features can produce state-of-the-art classification accuracies which are more consistent and stable than the results of existing features across all datasets.
Tag-based Semantic Features for Scene Image Classification
Sep 22, 2019

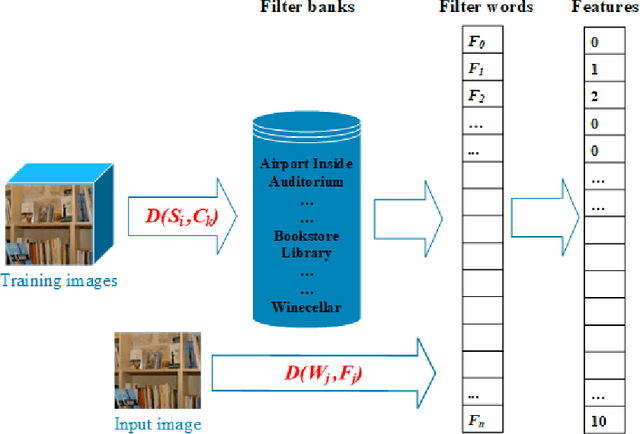
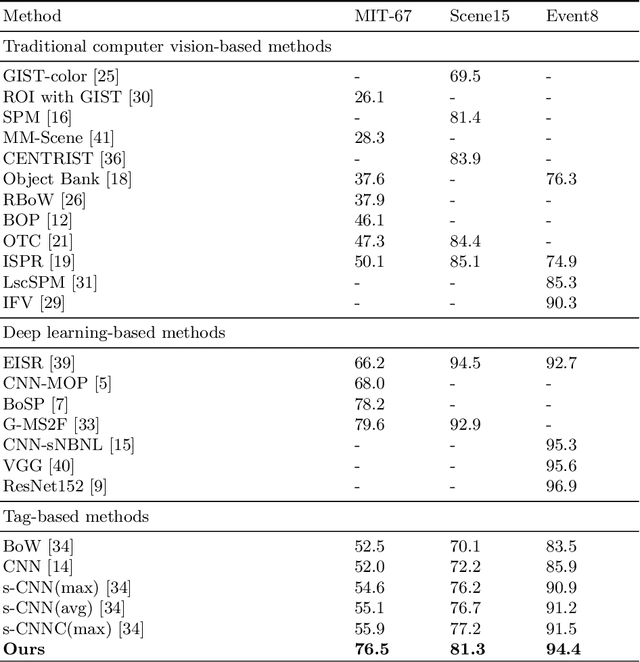
The existing image feature extraction methods are primarily based on the content and structure information of images, and rarely consider the contextual semantic information. Regarding some types of images such as scenes and objects, the annotations and descriptions of them available on the web may provide reliable contextual semantic information for feature extraction. In this paper, we introduce novel semantic features of an image based on the annotations and descriptions of its similar images available on the web. Specifically, we propose a new method which consists of two consecutive steps to extract our semantic features. For each image in the training set, we initially search the top $k$ most similar images from the internet and extract their annotations/descriptions (e.g., tags or keywords). The annotation information is employed to design a filter bank for each image category and generate filter words (codebook). Finally, each image is represented by the histogram of the occurrences of filter words in all categories. We evaluate the performance of the proposed features in scene image classification on three commonly-used scene image datasets (i.e., MIT-67, Scene15 and Event8). Our method typically produces a lower feature dimension than existing feature extraction methods. Experimental results show that the proposed features generate better classification accuracies than vision based and tag based features, and comparable results to deep learning based features.