 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiming is important: Risk-aware Fund Allocation based on Time-Series Forecasting
May 30, 2025Fund allocation has been an increasingly important problem in the financial domain. In reality, we aim to allocate the funds to buy certain assets within a certain future period. Naive solutions such as prediction-only or Predict-then-Optimize approaches suffer from goal mismatch. Additionally, the introduction of the SOTA time series forecasting model inevitably introduces additional uncertainty in the predicted result. To solve both problems mentioned above, we introduce a Risk-aware Time-Series Predict-and-Allocate (RTS-PnO) framework, which holds no prior assumption on the forecasting models. Such a framework contains three features: (i) end-to-end training with objective alignment measurement, (ii) adaptive forecasting uncertainty calibration, and (iii) agnostic towards forecasting models. The evaluation of RTS-PnO is conducted over both online and offline experiments. For offline experiments, eight datasets from three categories of financial applications are used: Currency, Stock, and Cryptos. RTS-PnO consistently outperforms other competitive baselines. The online experiment is conducted on the Cross-Border Payment business at FiT, Tencent, and an 8.4\% decrease in regret is witnessed when compared with the product-line approach. The code for the offline experiment is available at https://github.com/fuyuanlyu/RTS-PnO.
O-PRESS: Boosting OCT axial resolution with Prior guidance, Recurrence, and Equivariant Self-Supervision
Jan 06, 2024



Optical coherence tomography (OCT) is a noninvasive technology that enables real-time imaging of tissue microanatomies. The axial resolution of OCT is intrinsically constrained by the spectral bandwidth of the employed light source while maintaining a fixed center wavelength for a specific application. Physically extending this bandwidth faces strong limitations and requires a substantial cost. We present a novel computational approach, called as O-PRESS, for boosting the axial resolution of OCT with Prior Guidance, a Recurrent mechanism, and Equivariant Self-Supervision. Diverging from conventional superresolution methods that rely on physical models or data-driven techniques, our method seamlessly integrates OCT modeling and deep learning, enabling us to achieve real-time axial-resolution enhancement exclusively from measurements without a need for paired images. Our approach solves two primary tasks of resolution enhancement and noise reduction with one treatment. Both tasks are executed in a self-supervised manner, with equivariance imaging and free space priors guiding their respective processes. Experimental evaluations, encompassing both quantitative metrics and visual assessments, consistently verify the efficacy and superiority of our approach, which exhibits performance on par with fully supervised methods. Importantly, the robustness of our model is affirmed, showcasing its dual capability to enhance axial resolution while concurrently improving the signal-to-noise ratio.
Learning Two-Stream CNN for Multi-Modal Age-related Macular Degeneration Categorization
Dec 03, 2020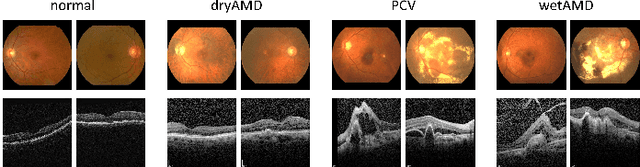
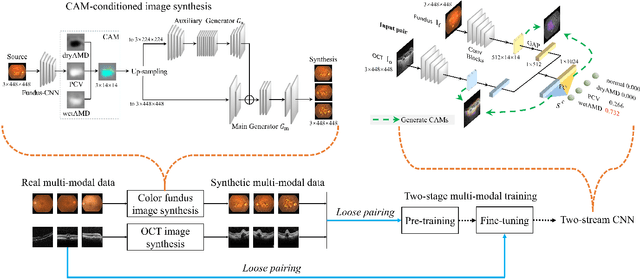
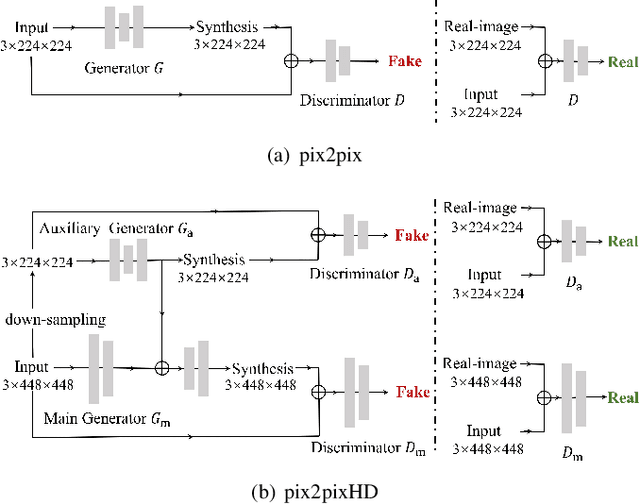
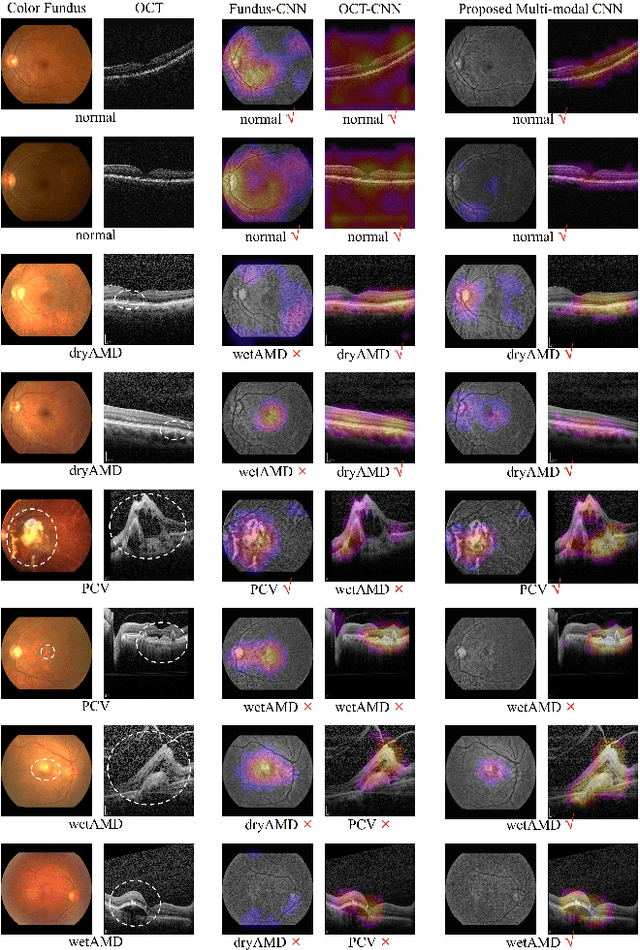
This paper tackles automated categorization of Age-related Macular Degeneration (AMD), a common macular disease among people over 50. Previous research efforts mainly focus on AMD categorization with a single-modal input, let it be a color fundus image or an OCT image. By contrast, we consider AMD categorization given a multi-modal input, a direction that is clinically meaningful yet mostly unexplored. Contrary to the prior art that takes a traditional approach of feature extraction plus classifier training that cannot be jointly optimized, we opt for end-to-end multi-modal Convolutional Neural Networks (MM-CNN). Our MM-CNN is instantiated by a two-stream CNN, with spatially-invariant fusion to combine information from the fundus and OCT streams. In order to visually interpret the contribution of the individual modalities to the final prediction, we extend the class activation mapping (CAM) technique to the multi-modal scenario. For effective training of MM-CNN, we develop two data augmentation methods. One is GAN-based fundus / OCT image synthesis, with our novel use of CAMs as conditional input of a high-resolution image-to-image translation GAN. The other method is Loose Pairing, which pairs a fundus image and an OCT image on the basis of their classes instead of eye identities. Experiments on a clinical dataset consisting of 1,099 color fundus images and 1,290 OCT images acquired from 1,099 distinct eyes verify the effectiveness of the proposed solution for multi-modal AMD categorization.
Two-Stream CNN with Loose Pair Training for Multi-modal AMD Categorization
Jul 28, 2019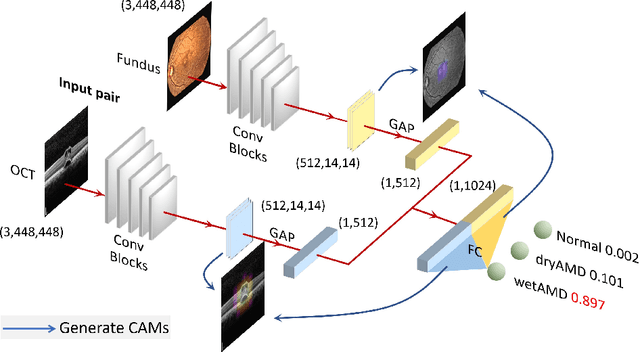

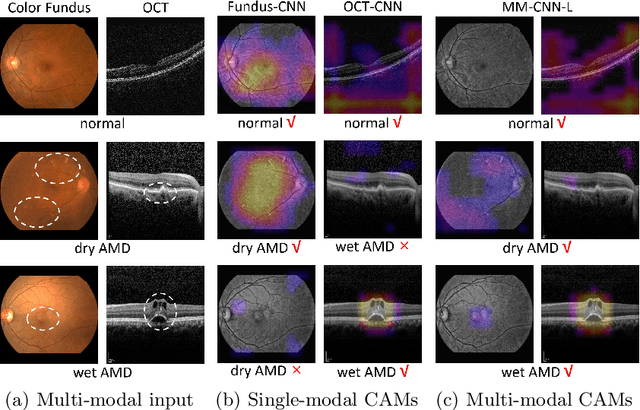
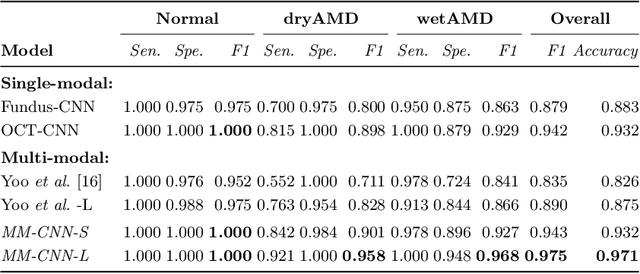
This paper studies automated categorization of age-related macular degeneration (AMD) given a multi-modal input, which consists of a color fundus image and an optical coherence tomography (OCT) image from a specific eye. Previous work uses a traditional method, comprised of feature extraction and classifier training that cannot be optimized jointly. By contrast, we propose a two-stream convolutional neural network (CNN) that is end-to-end. The CNN's fusion layer is tailored to the need of fusing information from the fundus and OCT streams. For generating more multi-modal training instances, we introduce Loose Pair training, where a fundus image and an OCT image are paired based on class labels rather than eyes. Moreover, for a visual interpretation of how the individual modalities make contributions, we extend the class activation mapping technique to the multi-modal scenario. Experiments on a real-world dataset collected from an outpatient clinic justify the viability of our proposal for multi-modal AMD categorization.