 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSelect: Automatic and Dynamic Detection Selection for 3D Multi-Object Tracking
Dec 10, 2020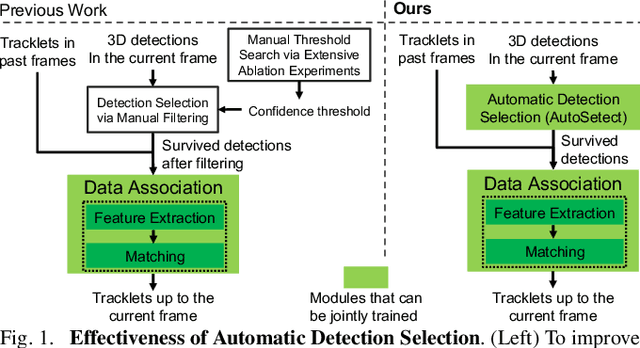
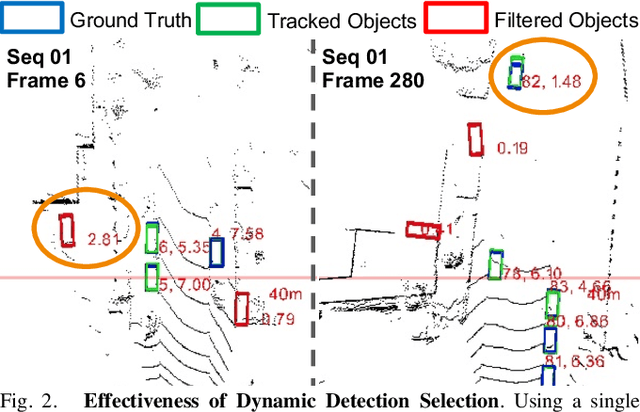
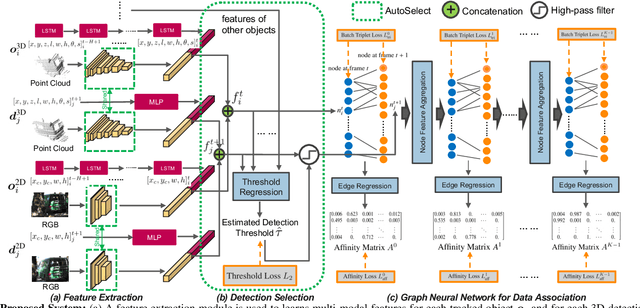
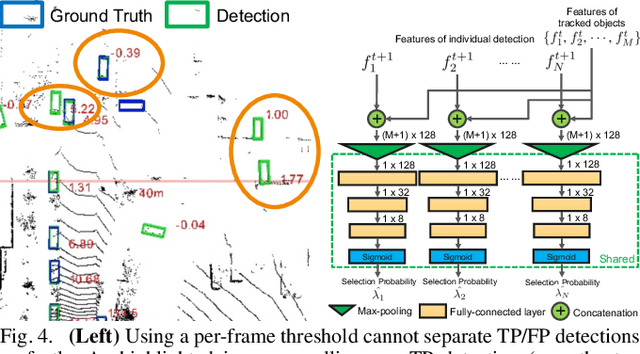
3D multi-object tracking is an important component in robotic perception systems such as self-driving vehicles. Recent work follows a tracking-by-detection pipeline, which aims to match past tracklets with detections in the current frame. To avoid matching with false positive detections, prior work filters out detections with low confidence scores via a threshold. However, finding a proper threshold is non-trivial, which requires extensive manual search via ablation study. Also, this threshold is sensitive to many factors such as target object category so we need to re-search the threshold if these factors change. To ease this process, we propose to automatically select high-quality detections and remove the efforts needed for manual threshold search. Also, prior work often uses a single threshold per data sequence, which is sub-optimal in particular frames or for certain objects. Instead, we dynamically search threshold per frame or per object to further boost performance. Through experiments on KITTI and nuScenes, our method can filter out $45.7\%$ false positives while maintaining the recall, achieving new S.O.T.A. performance and removing the need for manually threshold tuning.
End-to-End 3D Multi-Object Tracking and Trajectory Forecasting
Aug 25, 2020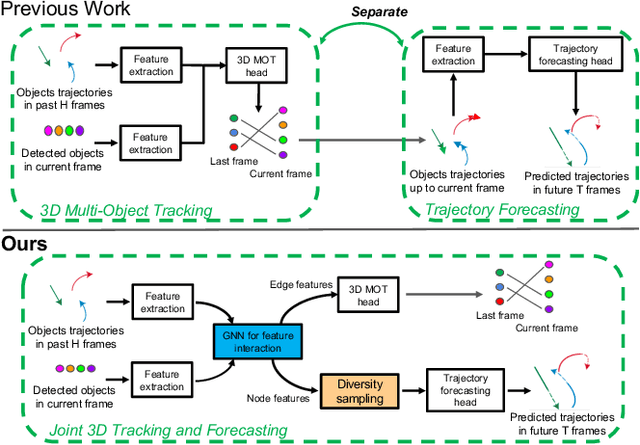

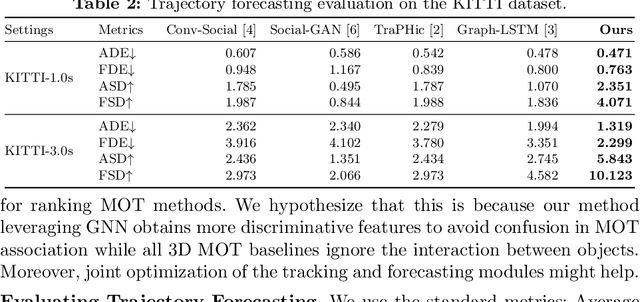
3D multi-object tracking (MOT) and trajectory forecasting are two critical components in modern 3D perception systems. We hypothesize that it is beneficial to unify both tasks under one framework to learn a shared feature representation of agent interaction. To evaluate this hypothesis, we propose a unified solution for 3D MOT and trajectory forecasting which also incorporates two additional novel computational units. First, we employ a feature interaction technique by introducing Graph Neural Networks (GNNs) to capture the way in which multiple agents interact with one another. The GNN is able to model complex hierarchical interactions, improve the discriminative feature learning for MOT association, and provide socially-aware context for trajectory forecasting. Second, we use a diversity sampling function to improve the quality and diversity of our forecasted trajectories. The learned sampling function is trained to efficiently extract a variety of outcomes from a generative trajectory distribution and helps avoid the problem of generating many duplicate trajectory samples. We show that our method achieves state-of-the-art performance on the KITTI dataset. Our project website is at http://www.xinshuoweng.com/projects/GNNTrkForecast.
Graph Neural Networks for 3D Multi-Object Tracking
Aug 20, 2020

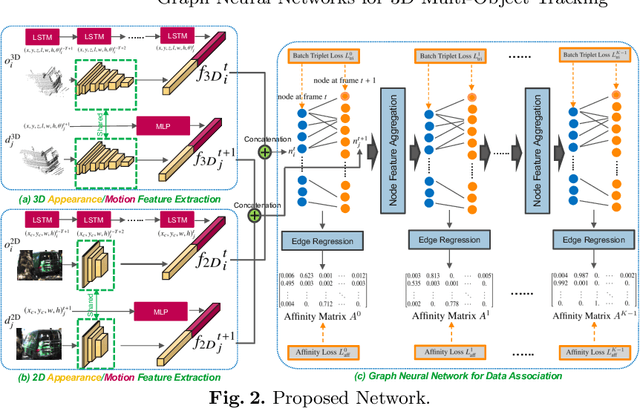
3D Multi-object tracking (MOT) is crucial to autonomous systems. Recent work often uses a tracking-by-detection pipeline, where the feature of each object is extracted independently to compute an affinity matrix. Then, the affinity matrix is passed to the Hungarian algorithm for data association. A key process of this pipeline is to learn discriminative features for different objects in order to reduce confusion during data association. To that end, we propose two innovative techniques: (1) instead of obtaining the features for each object independently, we propose a novel feature interaction mechanism by introducing Graph Neural Networks; (2) instead of obtaining the features from either 2D or 3D space as in prior work, we propose a novel joint feature extractor to learn appearance and motion features from 2D and 3D space. Through experiments on the KITTI dataset, our proposed method achieves state-of-the-art 3D MOT performance. Our project website is at http://www.xinshuoweng.com/projects/GNN3DMOT.
AB3DMOT: A Baseline for 3D Multi-Object Tracking and New Evaluation Metrics
Aug 18, 2020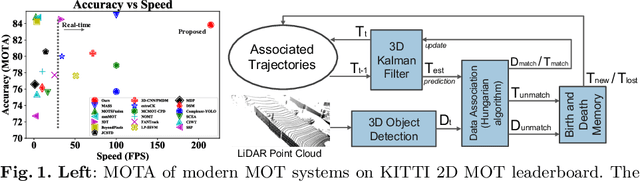
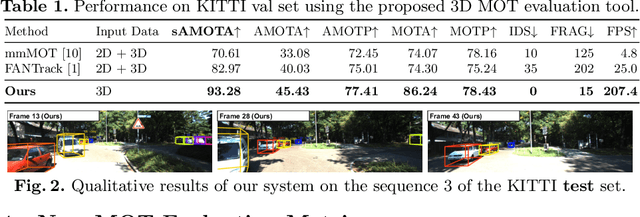
3D multi-object tracking (MOT) is essential to applications such as autonomous driving. Recent work focuses on developing accurate systems giving less attention to computational cost and system complexity. In contrast, this work proposes a simple real-time 3D MOT system with strong performance. Our system first obtains 3D detections from a LiDAR point cloud. Then, a straightforward combination of a 3D Kalman filter and the Hungarian algorithm is used for state estimation and data association. Additionally, 3D MOT datasets such as KITTI evaluate MOT methods in 2D space and standardized 3D MOT evaluation tools are missing for a fair comparison of 3D MOT methods. We propose a new 3D MOT evaluation tool along with three new metrics to comprehensively evaluate 3D MOT methods. We show that, our proposed method achieves strong 3D MOT performance on KITTI and runs at a rate of $207.4$ FPS on the KITTI dataset, achieving the fastest speed among modern 3D MOT systems. Our code is publicly available at http://www.xinshuoweng.com/projects/AB3DMOT.
Joint Detection and Multi-Object Tracking with Graph Neural Networks
Jun 23, 2020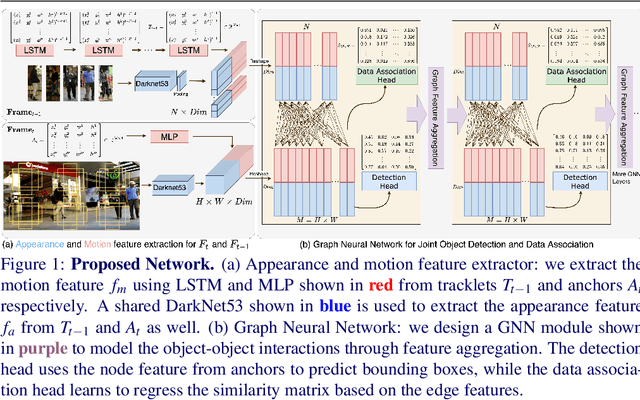
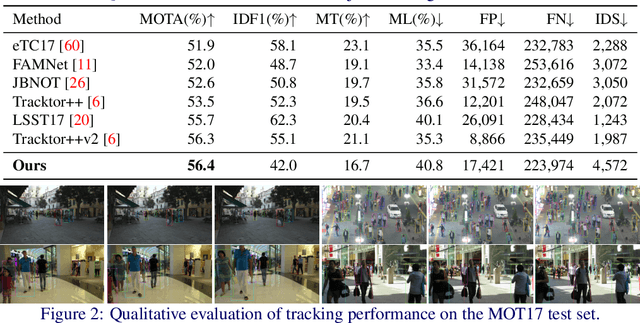
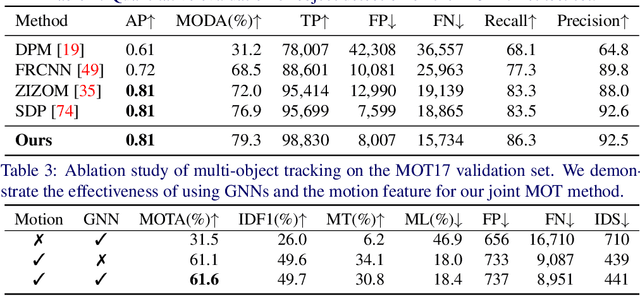
Object detection and data association are critical components in multi-object tracking (MOT) systems. Despite the fact that these two components are highly dependent on each other, one popular trend in MOT is to perform detection and data association as separate modules, processed in a cascaded order. Due to this cascaded process, the resulting MOT system can only perform forward inference and cannot back-propagate error through the entire pipeline and correct them. This leads to sub-optimal performance over the total pipeline. To address this issue, recent work jointly optimizes detection and data association and forms an integrated MOT approach, which has been shown to improve performance in both detection and tracking. In this work, we propose a new approach for joint MOT based on Graph Neural Networks (GNNs). The key idea of our approach is that GNNs can explicitly model complex interactions between multiple objects in both the spatial and temporal domains, which is essential for learning discriminative features for detection and data association. We also leverage the fact that motion features are useful for MOT when used together with appearance features. So our proposed joint MOT approach also incorporates appearance and motion features within our graph-based feature learning framework, leading to better feature learning for MOT. Through extensive experiments on the MOT challenge dataset, we show that our proposed method achieves state-of-the-art performance on both object detection and MOT.
When We First Met: Visual-Inertial Person Localization for Co-Robot Rendezvous
Jun 17, 2020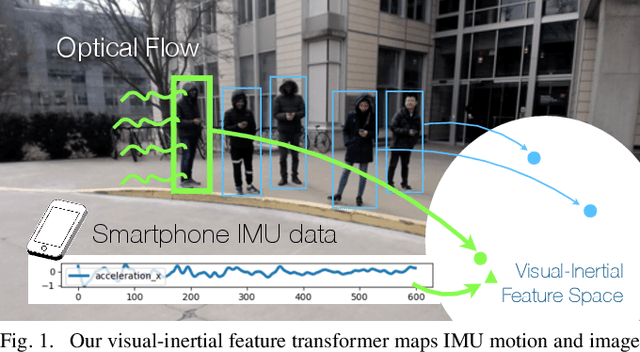

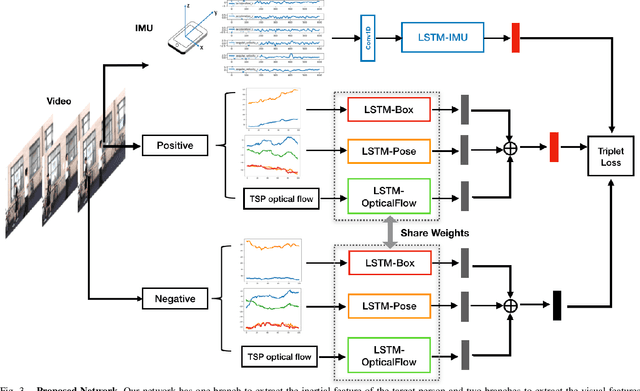
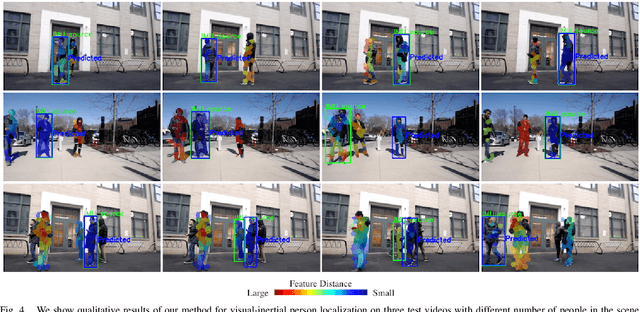
We aim to enable robots to visually localize a target person through the aid of an additional sensing modality -- the target person's 3D inertial measurements. The need for such technology may arise when a robot is to meet person in a crowd for the first time or when an autonomous vehicle must rendezvous with a rider amongst a crowd without knowing the appearance of the person in advance. A person's inertial information can be measured with a wearable device such as a smart-phone and can be shared selectively with an autonomous system during the rendezvous. We propose a method to learn a visual-inertial feature space in which the motion of a person in video can be easily matched to the motion measured by a wearable inertial measurement unit (IMU). The transformation of the two modalities into the joint feature space is learned through the use of a contrastive loss which forces inertial motion features and video motion features generated by the same person to lie close in the joint feature space. To validate our approach, we compose a dataset of over 60,000 video segments of moving people along with wearable IMU data. Our experiments show that our proposed method is able to accurately localize a target person with 80.7% accuracy using only 5 seconds of IMU data and video.
GNN3DMOT: Graph Neural Network for 3D Multi-Object Tracking with Multi-Feature Learning
Jun 12, 2020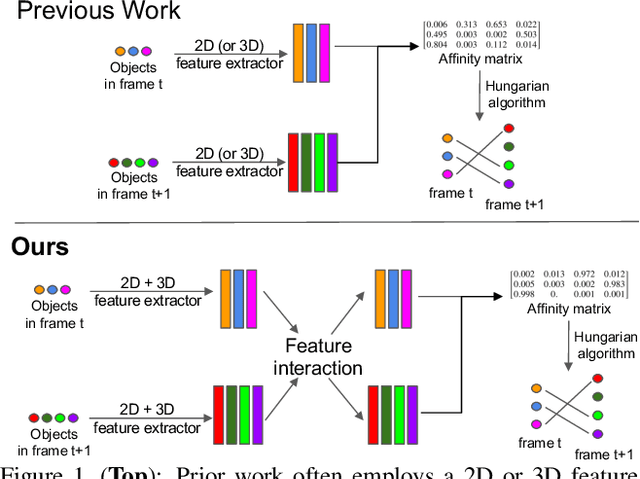
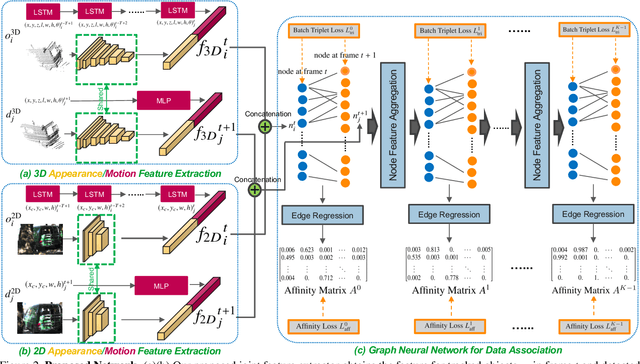
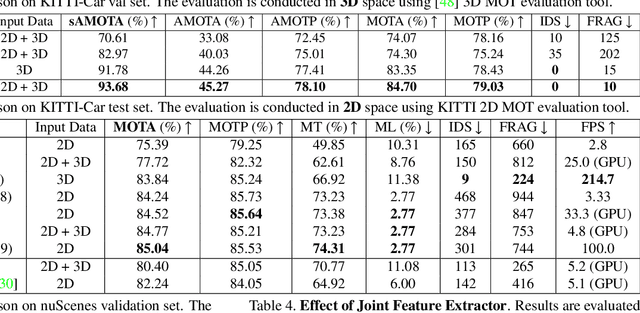
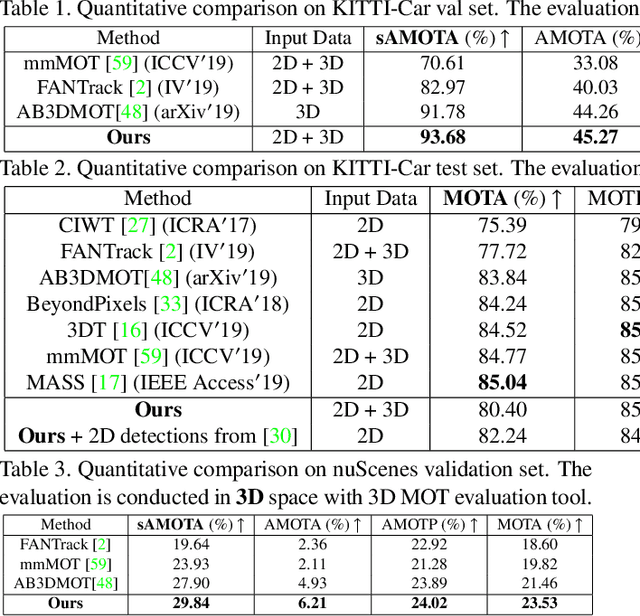
3D Multi-object tracking (MOT) is crucial to autonomous systems. Recent work uses a standard tracking-by-detection pipeline, where feature extraction is first performed independently for each object in order to compute an affinity matrix. Then the affinity matrix is passed to the Hungarian algorithm for data association. A key process of this standard pipeline is to learn discriminative features for different objects in order to reduce confusion during data association. In this work, we propose two techniques to improve the discriminative feature learning for MOT: (1) instead of obtaining features for each object independently, we propose a novel feature interaction mechanism by introducing the Graph Neural Network. As a result, the feature of one object is informed of the features of other objects so that the object feature can lean towards the object with similar feature (i.e., object probably with a same ID) and deviate from objects with dissimilar features (i.e., object probably with different IDs), leading to a more discriminative feature for each object; (2) instead of obtaining the feature from either 2D or 3D space in prior work, we propose a novel joint feature extractor to learn appearance and motion features from 2D and 3D space simultaneously. As features from different modalities often have complementary information, the joint feature can be more discriminate than feature from each individual modality. To ensure that the joint feature extractor does not heavily rely on one modality, we also propose an ensemble training paradigm. Through extensive evaluation, our proposed method achieves state-of-the-art performance on KITTI and nuScenes 3D MOT benchmarks. Our code will be made available at https://github.com/xinshuoweng/GNN3DMOT
Unsupervised Sequence Forecasting of 100,000 Points for Unsupervised Trajectory Forecasting
Mar 29, 2020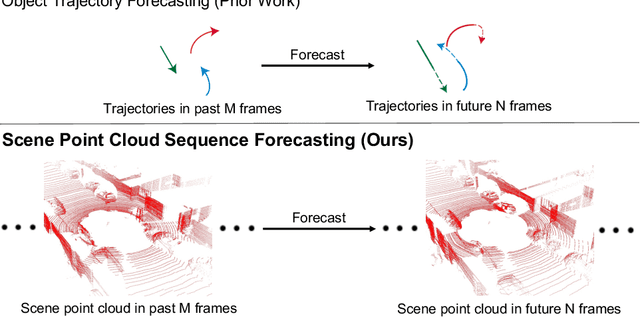
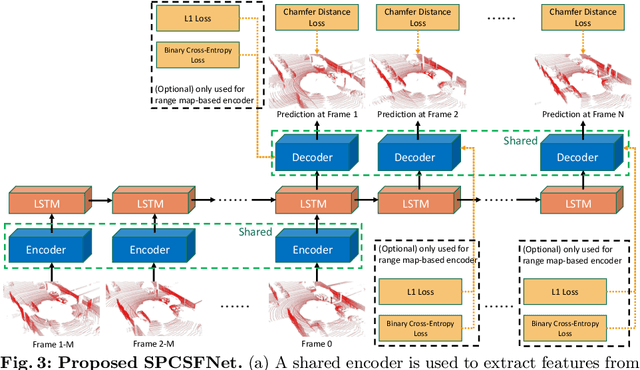
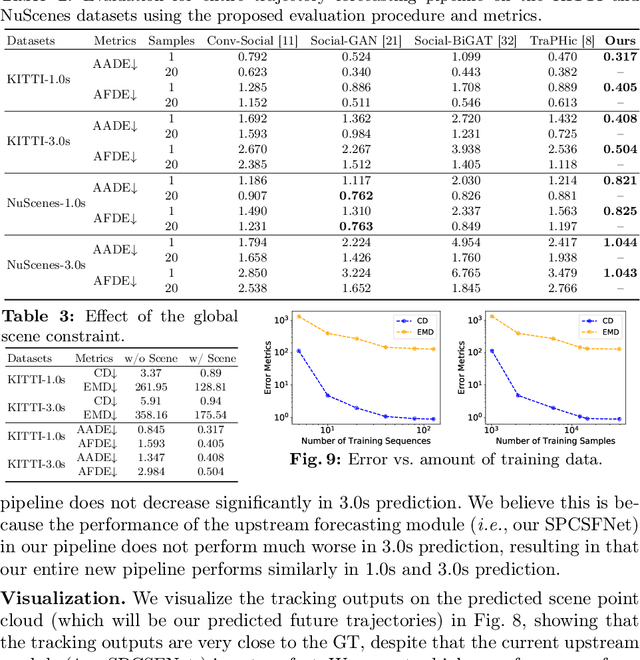
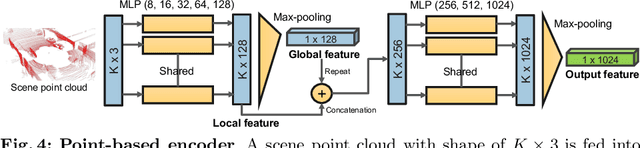
Predicting the future is a crucial first step to effective control, since systems that can predict the future can select plans that lead to desired outcomes. In this work, we study the problem of future prediction at the level of 3D scenes, represented by point clouds captured by a LiDAR sensor, i.e., directly learning to forecast the evolution of >100,000 points that comprise a complete scene. We term this Scene Point Cloud Sequence Forecasting (SPCSF). By directly predicting the densest-possible 3D representation of the future, the output contains richer information than other representations such as future object trajectories. We design a method, SPCSFNet, evaluate it on the KITTI and nuScenes datasets, and find that it demonstrates excellent performance on the SPCSF task. To show that SPCSF can benefit downstream tasks such as object trajectory forecasting, we present a new object trajectory forecasting pipeline leveraging SPCSFNet. Specifically, instead of forecasting at the object level as in conventional trajectory forecasting, we propose to forecast at the sensor level and then apply detection and tracking on the predicted sensor data. As a result, our new pipeline can remove the need of object trajectory labels and enable large-scale training with unlabeled sensor data. Surprisingly, we found our new pipeline based on SPCSFNet was able to outperform the conventional pipeline using state-of-the-art trajectory forecasting methods, all of which require future object trajectory labels. Finally, we propose a new evaluation procedure and two new metrics to measure the end-to-end performance of the trajectory forecasting pipeline. Our code will be made publicly available at https://github.com/xinshuoweng/SPCSF
Joint 3D Tracking and Forecasting with Graph Neural Network and Diversity Sampling
Mar 17, 2020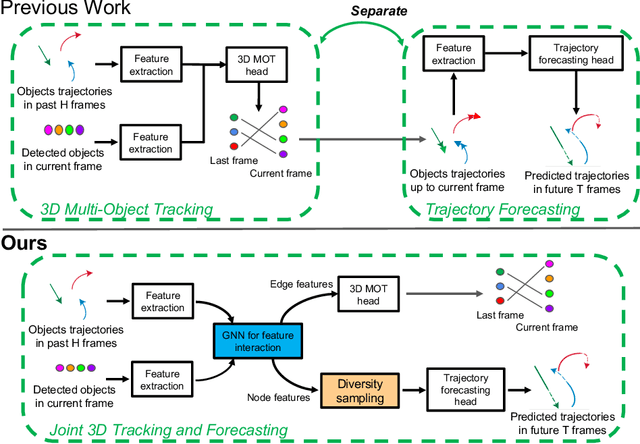
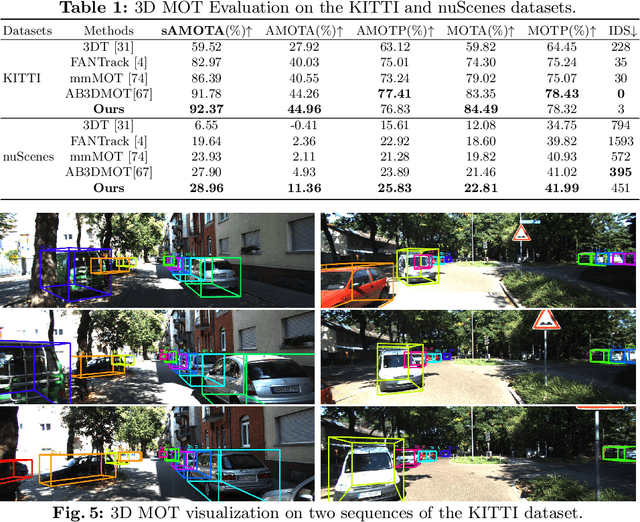
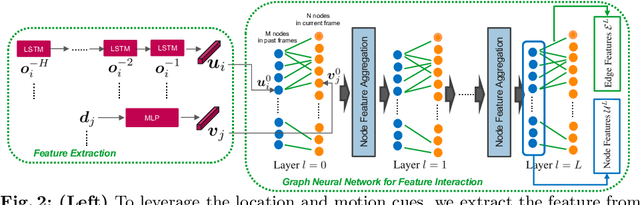
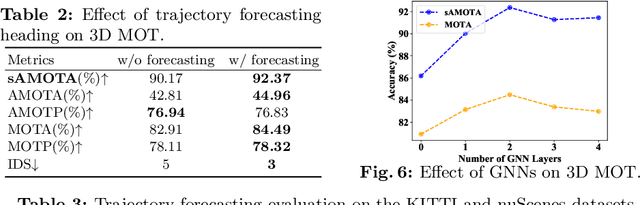
3D multi-object tracking (MOT) and trajectory forecasting are two critical components in modern 3D perception systems that require accurate modeling of multi-agent interaction. We hypothesize that it is beneficial to unify both tasks under one framework in order to learn a shared feature representation of agent interaction. To evaluate this hypothesis, we propose a unified solution for 3D MOT and trajectory forecasting which also incorporates two additional novel computational units. First, we propose a feature interaction technique by introducing Graph Neural Networks (GNNs) to capture the way in which multiple agents interact with one another. The GNN is able to model complex hierarchical interactions, improve the discriminative feature learning for MOT association, and provide socially-aware context for trajectory forecasting. Second, we use a diversity sampling function to improve the quality and diversity of our forecasted trajectories. The learned sampling function is trained to efficiently extract a variety of outcomes from a generative trajectory distribution and helps avoid the problem of generating many duplicate trajectory samples. We evaluate on the KITTI and nuScenes datasets, showing that our unified method with feature interaction and diversity sampling achieves new state-of-the-art performance on both 3D MOT and trajectory forecasting. Our code will be made available at https://github.com/xinshuoweng/GNNTrkForecast.
Learning Shape Representations for Clothing Variations in Person Re-Identification
Mar 16, 2020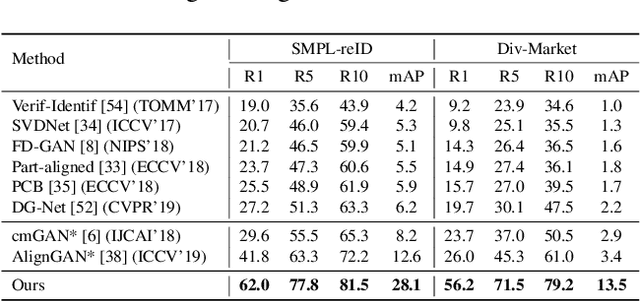

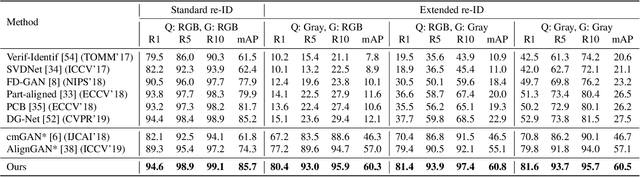

Person re-identification (re-ID) aims to recognize instances of the same person contained in multiple images taken across different cameras. Existing methods for re-ID tend to rely heavily on the assumption that both query and gallery images of the same person have the same clothing. Unfortunately, this assumption may not hold for datasets captured over long periods of time (e.g., weeks, months or years). To tackle the re-ID problem in the context of clothing changes, we propose a novel representation learning model which is able to generate a body shape feature representation without being affected by clothing color or patterns. We call our model the Color Agnostic Shape Extraction Network (CASE-Net). CASE-Net learns a representation of identity that depends only on body shape via adversarial learning and feature disentanglement. Due to the lack of large-scale re-ID datasets which contain clothing changes for the same person, we propose two synthetic datasets for evaluation. We create a rendered dataset SMPL-reID with different clothes patterns and a synthesized dataset Div-Market with different clothing color to simulate two types of clothing changes. The quantitative and qualitative results across 5 datasets (SMPL-reID, Div-Market, two benchmark re-ID datasets, a cross-modality re-ID dataset) confirm the robustness and superiority of our approach against several state-of-the-art approaches