 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKD-CVG: A Knowledge-Driven Approach for Creative Video Generation
Apr 23, 2026Creative Generation (CG) leverages generative models to automatically produce advertising content that highlights product features, and it has been a significant focus of recent research. However, while CG has advanced considerably, most efforts have concentrated on generating advertising text and images, leaving Creative Video Generation (CVG) relatively underexplored. This gap is largely due to two major challenges faced by Text-to-Video (T2V) models: (a) \textbf{ambiguous semantic alignment}, where models struggle to accurately correlate product selling points with creative video content, and (b) \textbf{inadequate motion adaptability}, resulting in unrealistic movements and distortions. To address these challenges, we develop a comprehensive Advertising Creative Knowledge Base (ACKB) as a foundational resource and propose a knowledge-driven approach (KD-CVG) to overcome the knowledge limitations of existing models. KD-CVG consists of two primary modules: Semantic-Aware Retrieval (SAR) and Multimodal Knowledge Reference (MKR). SAR utilizes the semantic awareness of graph attention networks and reinforcement learning feedback to enhance the model's comprehension of the connections between selling points and creative videos. Building on this, MKR incorporates semantic and motion priors into the T2V model to address existing knowledge gaps. Extensive experiments have demonstrated KD-CVG's superior performance in achieving semantic alignment and motion adaptability, validating its effectiveness over other state-of-the-art methods. The code and dataset will be open source at https://kdcvg.github.io/KDCVG/.
PointSCNet: Point Cloud Structure and Correlation Learning Based on Space Filling Curve-Guided Sampling
Feb 21, 2022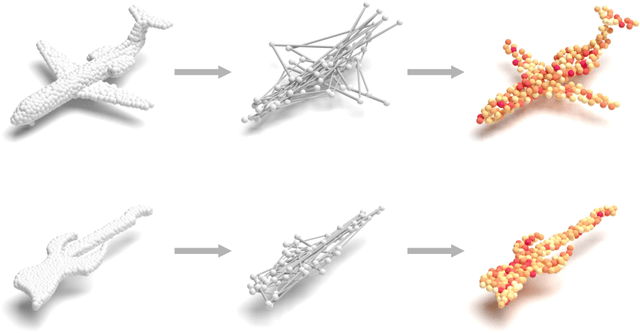
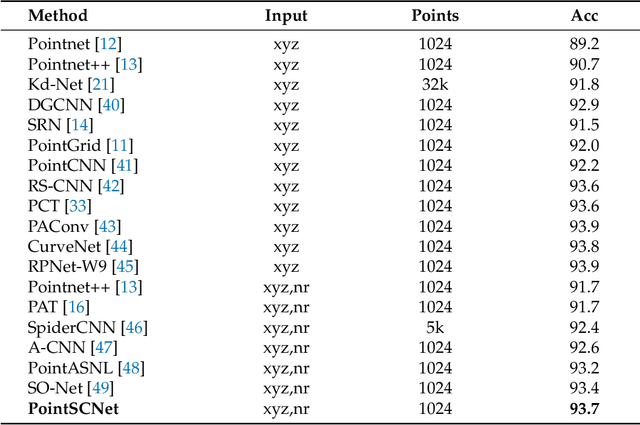
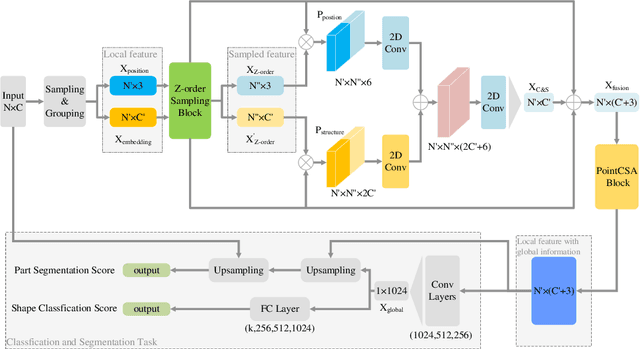
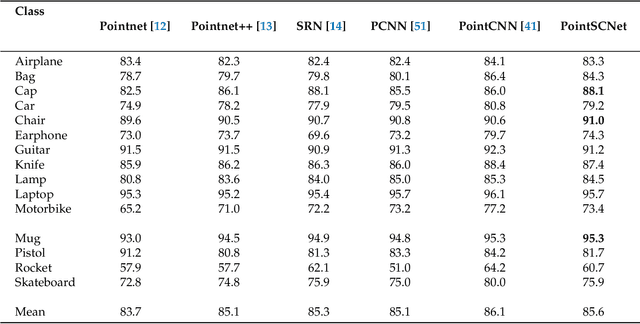
Geometrical structures and the internal local region relationship, such as symmetry, regular array, junction, etc., are essential for understanding a 3D shape. This paper proposes a point cloud feature extraction network named PointSCNet, to capture the geometrical structure information and local region correlation information of a point cloud. The PointSCNet consists of three main modules: the space-filling curve-guided sampling module, the information fusion module, and the channel-spatial attention module. The space-filling curve-guided sampling module uses Z-order curve coding to sample points that contain geometrical correlation. The information fusion module uses a correlation tensor and a set of skip connections to fuse the structure and correlation information. The channel-spatial attention module enhances the representation of key points and crucial feature channels to refine the network. The proposed PointSCNet is evaluated on shape classification and part segmentation tasks. The experimental results demonstrate that the PointSCNet outperforms or is on par with state-of-the-art methods by learning the structure and correlation of point clouds effectively.