 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Improvement using Language Feedback Models
Feb 25, 2024



We introduce Language Feedback Models (LFMs) that identify desirable behaviour - actions that help achieve tasks specified in the instruction - for imitation learning in instruction following. To train LFMs, we obtain feedback from Large Language Models (LLMs) on visual trajectories verbalized to language descriptions. First, by using LFMs to identify desirable behaviour to imitate, we improve in task-completion rate over strong behavioural cloning baselines on three distinct language grounding environments (Touchdown, ScienceWorld, and ALFWorld). Second, LFMs outperform using LLMs as experts to directly predict actions, when controlling for the number of LLM output tokens. Third, LFMs generalize to unseen environments, improving task-completion rate by 3.5-12.0% through one round of adaptation. Finally, LFM can be modified to provide human-interpretable feedback without performance loss, allowing human verification of desirable behaviour for imitation learning.
V-STaR: Training Verifiers for Self-Taught Reasoners
Feb 09, 2024



Common self-improvement approaches for large language models (LLMs), such as STaR (Zelikman et al., 2022), iteratively fine-tune LLMs on self-generated solutions to improve their problem-solving ability. However, these approaches discard the large amounts of incorrect solutions generated during this process, potentially neglecting valuable information in such solutions. To address this shortcoming, we propose V-STaR that utilizes both the correct and incorrect solutions generated during the self-improvement process to train a verifier using DPO that judges correctness of model-generated solutions. This verifier is used at inference time to select one solution among many candidate solutions. Running V-STaR for multiple iterations results in progressively better reasoners and verifiers, delivering a 4% to 17% test accuracy improvement over existing self-improvement and verification approaches on common code generation and math reasoning benchmarks with LLaMA2 models.
Guiding Language Model Reasoning with Planning Tokens
Oct 09, 2023



Large language models (LLMs) have recently attracted considerable interest for their ability to perform complex reasoning tasks, such as chain-of-thought reasoning. However, most of the existing approaches to enhance this ability rely heavily on data-driven methods, while neglecting the structural aspects of the model's reasoning capacity. We find that while LLMs can manage individual reasoning steps well, they struggle with maintaining consistency across an entire reasoning chain. To solve this, we introduce 'planning tokens' at the start of each reasoning step, serving as a guide for the model. These token embeddings are then fine-tuned along with the rest of the model parameters. Our approach requires a negligible increase in trainable parameters (just 0.001%) and can be applied through either full fine-tuning or a more parameter-efficient scheme. We demonstrate our method's effectiveness by applying it to three different LLMs, showing notable accuracy improvements across three math word problem datasets w.r.t. plain chain-of-thought fine-tuning baselines.
Deep Language Networks: Joint Prompt Training of Stacked LLMs using Variational Inference
Jun 21, 2023



We view large language models (LLMs) as stochastic \emph{language layers} in a network, where the learnable parameters are the natural language \emph{prompts} at each layer. We stack two such layers, feeding the output of one layer to the next. We call the stacked architecture a \emph{Deep Language Network} (DLN). We first show how to effectively perform prompt optimization for a 1-Layer language network (DLN-1). We then show how to train 2-layer DLNs (DLN-2), where two prompts must be learnt. We consider the output of the first layer as a latent variable to marginalize, and devise a variational inference algorithm for joint prompt training. A DLN-2 reaches higher performance than a single layer, sometimes comparable to few-shot GPT-4 even when each LLM in the network is smaller and less powerful. The DLN code is open source: https://github.com/microsoft/deep-language-networks .
Augmenting Autotelic Agents with Large Language Models
May 21, 2023Humans learn to master open-ended repertoires of skills by imagining and practicing their own goals. This autotelic learning process, literally the pursuit of self-generated (auto) goals (telos), becomes more and more open-ended as the goals become more diverse, abstract and creative. The resulting exploration of the space of possible skills is supported by an inter-individual exploration: goal representations are culturally evolved and transmitted across individuals, in particular using language. Current artificial agents mostly rely on predefined goal representations corresponding to goal spaces that are either bounded (e.g. list of instructions), or unbounded (e.g. the space of possible visual inputs) but are rarely endowed with the ability to reshape their goal representations, to form new abstractions or to imagine creative goals. In this paper, we introduce a language model augmented autotelic agent (LMA3) that leverages a pretrained language model (LM) to support the representation, generation and learning of diverse, abstract, human-relevant goals. The LM is used as an imperfect model of human cultural transmission; an attempt to capture aspects of humans' common-sense, intuitive physics and overall interests. Specifically, it supports three key components of the autotelic architecture: 1)~a relabeler that describes the goals achieved in the agent's trajectories, 2)~a goal generator that suggests new high-level goals along with their decomposition into subgoals the agent already masters, and 3)~reward functions for each of these goals. Without relying on any hand-coded goal representations, reward functions or curriculum, we show that LMA3 agents learn to master a large diversity of skills in a task-agnostic text-based environment.
It Takes Two to Tango: Navigating Conceptualizations of NLP Tasks and Measurements of Performance
May 15, 2023



Progress in NLP is increasingly measured through benchmarks; hence, contextualizing progress requires understanding when and why practitioners may disagree about the validity of benchmarks. We develop a taxonomy of disagreement, drawing on tools from measurement modeling, and distinguish between two types of disagreement: 1) how tasks are conceptualized and 2) how measurements of model performance are operationalized. To provide evidence for our taxonomy, we conduct a meta-analysis of relevant literature to understand how NLP tasks are conceptualized, as well as a survey of practitioners about their impressions of different factors that affect benchmark validity. Our meta-analysis and survey across eight tasks, ranging from coreference resolution to question answering, uncover that tasks are generally not clearly and consistently conceptualized and benchmarks suffer from operationalization disagreements. These findings support our proposed taxonomy of disagreement. Finally, based on our taxonomy, we present a framework for constructing benchmarks and documenting their limitations.
Supporting Qualitative Analysis with Large Language Models: Combining Codebook with GPT-3 for Deductive Coding
Apr 17, 2023Qualitative analysis of textual contents unpacks rich and valuable information by assigning labels to the data. However, this process is often labor-intensive, particularly when working with large datasets. While recent AI-based tools demonstrate utility, researchers may not have readily available AI resources and expertise, let alone be challenged by the limited generalizability of those task-specific models. In this study, we explored the use of large language models (LLMs) in supporting deductive coding, a major category of qualitative analysis where researchers use pre-determined codebooks to label the data into a fixed set of codes. Instead of training task-specific models, a pre-trained LLM could be used directly for various tasks without fine-tuning through prompt learning. Using a curiosity-driven questions coding task as a case study, we found, by combining GPT-3 with expert-drafted codebooks, our proposed approach achieved fair to substantial agreements with expert-coded results. We lay out challenges and opportunities in using LLMs to support qualitative coding and beyond.
A Song of Ice and Fire: Analyzing Textual Autotelic Agents in ScienceWorld
Feb 24, 2023



Building open-ended agents that can autonomously discover a diversity of behaviours is one of the long-standing goals of artificial intelligence. This challenge can be studied in the framework of autotelic RL agents, i.e. agents that learn by selecting and pursuing their own goals, self-organizing a learning curriculum. Recent work identified language as a key dimension of autotelic learning, in particular because it enables abstract goal sampling and guidance from social peers for hindsight relabelling. Within this perspective, we study the following open scientific questions: What is the impact of hindsight feedback from a social peer (e.g. selective vs. exhaustive)? How can the agent learn from very rare language goal examples in its experience replay? How can multiple forms of exploration be combined, and take advantage of easier goals as stepping stones to reach harder ones? To address these questions, we use ScienceWorld, a textual environment with rich abstract and combinatorial physics. We show the importance of selectivity from the social peer's feedback; that experience replay needs to over-sample examples of rare goals; and that following self-generated goal sequences where the agent's competence is intermediate leads to significant improvements in final performance.
GPT-3-driven pedagogical agents for training children's curious question-asking skills
Dec 08, 2022Students' ability to ask curious questions is a crucial skill that improves their learning processes. To train this skill, previous research has used a conversational agent that propose specific cues to prompt children's curiosity during learning. Despite showing pedagogical efficiency, this method is still limited since it relies on generating the said prompts by hand for each educational resource, which can be a very long and costly process. In this context, we leverage the advances in the natural language processing field and explore using a large language model (GPT-3) to automate the generation of this agent's curiosity-prompting cues to help children ask more and deeper questions. We then used this study to investigate a different curiosity-prompting behavior for the agent. The study was conducted with 75 students aged between 9 and 10. They either interacted with a hand-crafted conversational agent that proposes "closed" manually-extracted cues leading to predefined questions, a GPT-3-driven one that proposes the same type of cues, or a GPT-3-driven one that proposes "open" cues that can lead to several possible questions. Results showed a similar question-asking performance between children who had the two "closed" agents, but a significantly better one for participants with the "open" agent. Our first results suggest the validity of using GPT-3 to facilitate the implementation of curiosity-stimulating learning technologies. In a second step, we also show that GPT-3 can be efficient in proposing the relevant open cues that leave children with more autonomy to express their curiosity.
Selecting Better Samples from Pre-trained LLMs: A Case Study on Question Generation
Sep 22, 2022
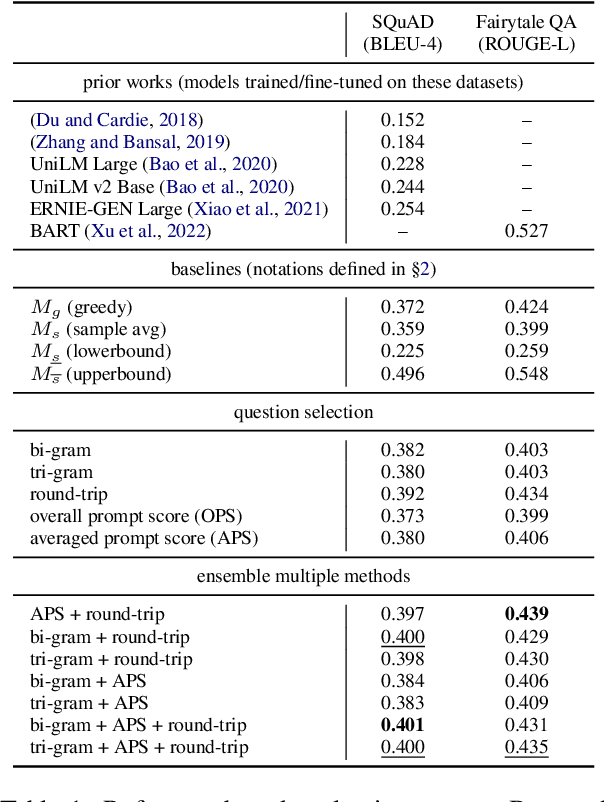
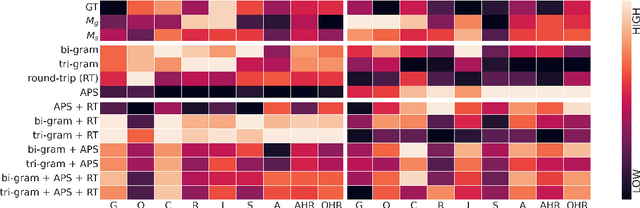
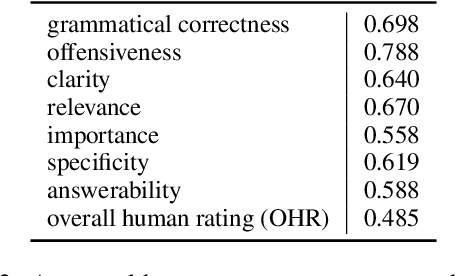
Large Language Models (LLMs) have in recent years demonstrated impressive prowess in natural language generation. A common practice to improve generation diversity is to sample multiple outputs from the model. However, there lacks a simple and robust way of selecting the best output from these stochastic samples. As a case study framed in the context of question generation, we propose two prompt-based approaches to selecting high-quality questions from a set of LLM-generated candidates. Our method works under the constraints of 1) a black-box (non-modifiable) question generation model and 2) lack of access to human-annotated references -- both of which are realistic limitations for real-world deployment of LLMs. With automatic as well as human evaluations, we empirically demonstrate that our approach can effectively select questions of higher qualities than greedy generation.