 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegatively Correlated Search as a Parallel Exploration Search Strategy
Oct 16, 2019
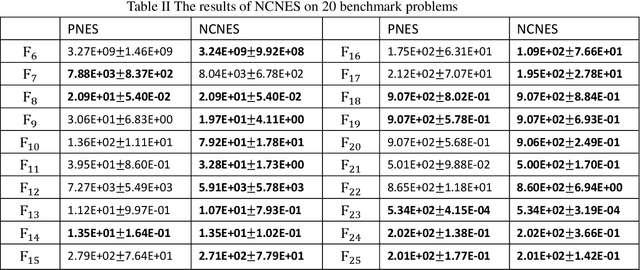
Parallel exploration is a key to a successful search. The recently proposed Negatively Correlated Search (NCS) achieved this ability by constructing a set of negatively correlated search processes and has been applied to many real-world problems. In NCS, the key technique is to explicitly model and maximize the diversity among search processes in parallel. However, the original diversity model was mostly devised by intuition, which introduced several drawbacks to NCS. In this paper, a mathematically principled diversity model is proposed to solve the existing drawbacks of NCS, resulting a new NCS framework. A new instantiation of NCS is also derived and its effectiveness is verified on a set of multi-modal continuous optimization problems.
Does Preference Always Help? A Holistic Study on Preference-Based Evolutionary Multi-Objective Optimisation Using Reference Points
Sep 30, 2019
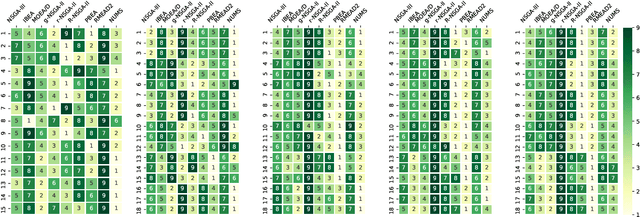
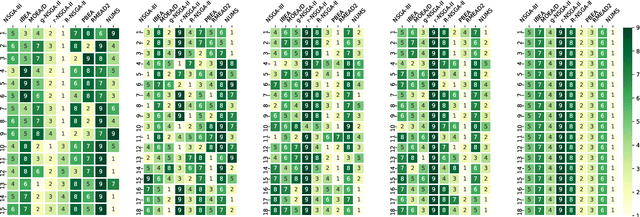
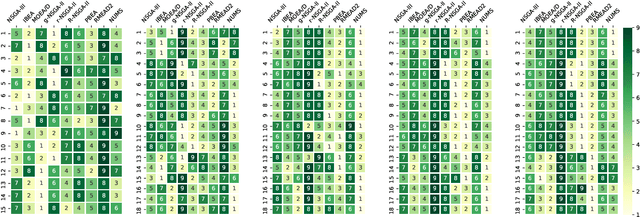
The ultimate goal of multi-objective optimisation is to help a decision maker (DM) identify solution(s) of interest (SOI) achieving satisfactory trade-offs among multiple conflicting criteria. This can be realised by leveraging DM's preference information in evolutionary multi-objective optimisation (EMO). No consensus has been reached on the effectiveness brought by incorporating preference in EMO (either a priori or interactively) versus a posteriori decision making after a complete run of an EMO algorithm. Bearing this consideration in mind, this paper i) provides a pragmatic overview of the existing developments of preference-based EMO; and ii) conducts a series of experiments to investigate the effectiveness brought by preference incorporation in EMO for approximating various SOI. In particular, the DM's preference information is elicited as a reference point, which represents her/his aspirations for different objectives. Experimental results demonstrate that preference incorporation in EMO does not always lead to a desirable approximation of SOI if the DM's preference information is not well utilised, nor does the DM elicit invalid preference information, which is not uncommon when encountering a black-box system. To a certain extent, this issue can be remedied through an interactive preference elicitation. Last but not the least, we find that a preference-based EMO algorithm is able to be generalised to approximate the whole PF given an appropriate setup of preference information.
A Simple Yet Effective Approach to Robust Optimization Over Time
Sep 05, 2019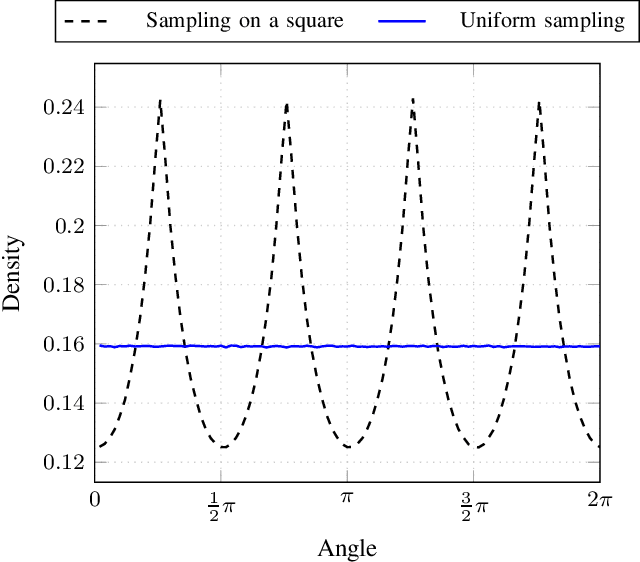
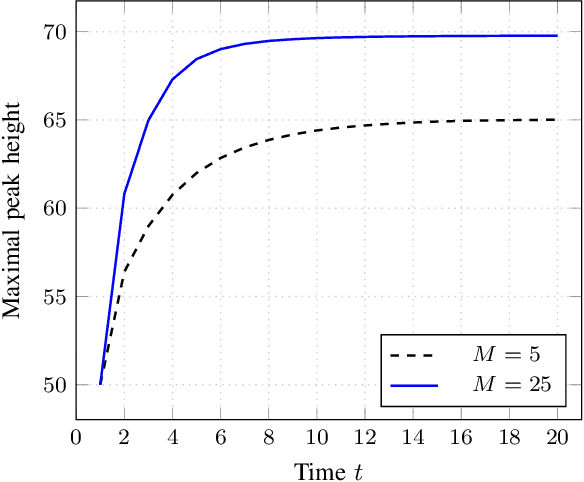
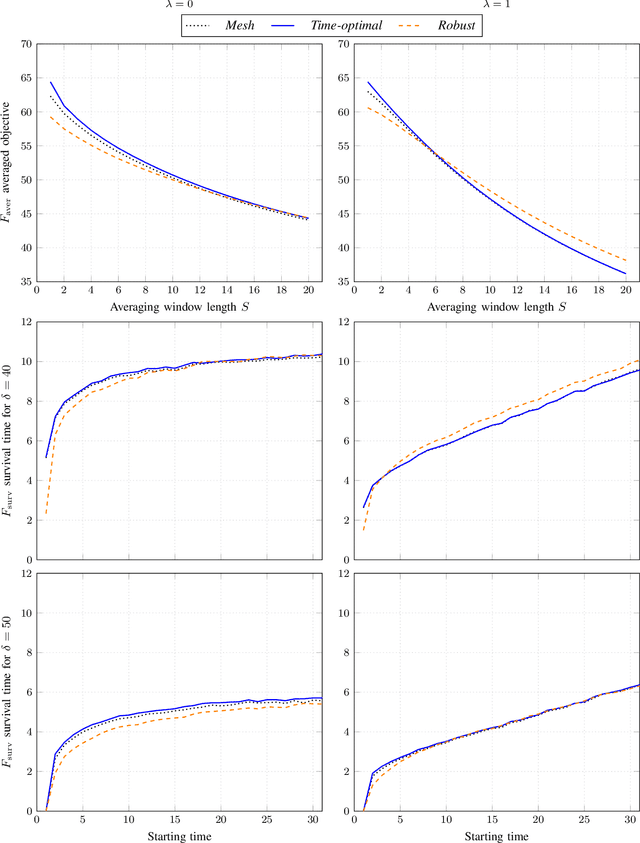
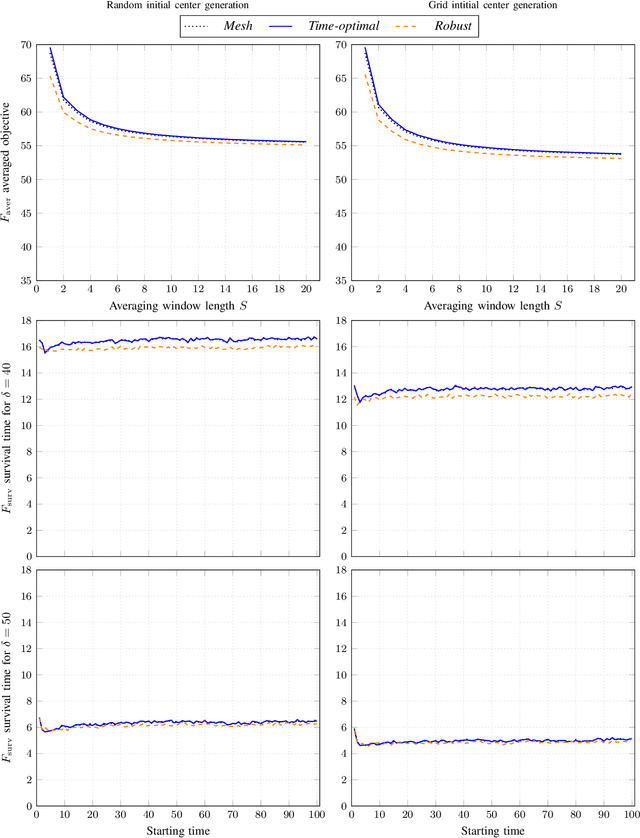
Robust optimization over time (ROOT) refers to an optimization problem where its performance is evaluated over a period of future time. Most of the existing algorithms use particle swarm optimization combined with another method which predicts future solutions to the optimization problem. We argue that this approach may perform subpar and suggest instead a method based on a random sampling of the search space. We prove its theoretical guarantees and show that it significantly outperforms the state-of-the-art methods for ROOT.
Federated Learning with Additional Mechanisms on Clients to Reduce Communication Costs
Sep 01, 2019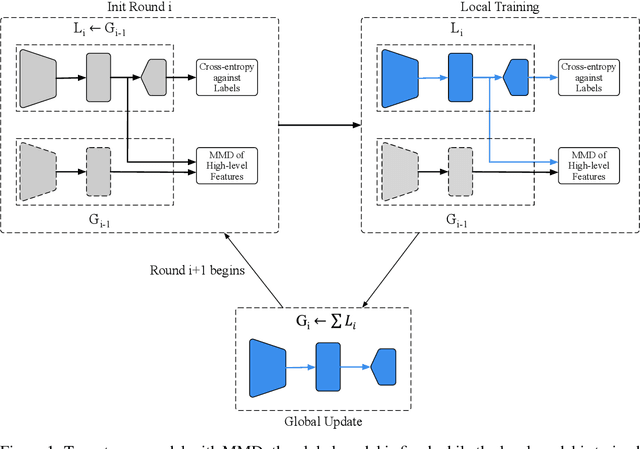
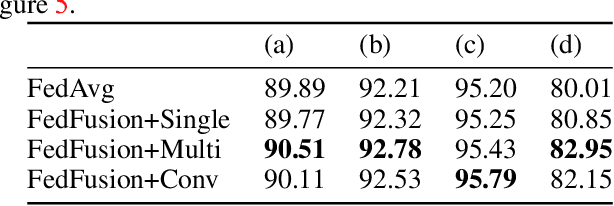
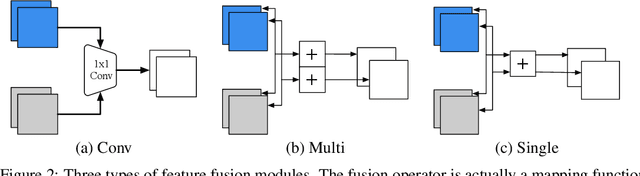
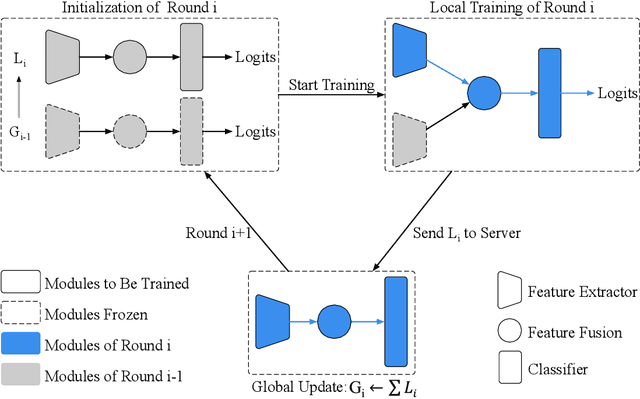
Federated learning (FL) enables on-device training over distributed networks consisting of a massive amount of modern smart devices, such as smartphones and IoT (Internet of Things) devices. However, the leading optimization algorithm in such settings, i.e., federated averaging (FedAvg), suffers from heavy communication costs and the inevitable performance drop, especially when the local data is distributed in a non-IID way. To alleviate this problem, we propose two potential solutions by introducing additional mechanisms to the on-device training. The first (FedMMD) is adopting a two-stream model with the MMD (Maximum Mean Discrepancy) constraint instead of a single model in vanilla FedAvg to be trained on devices. Experiments show that the proposed method outperforms baselines, especially in non-IID FL settings, with a reduction of more than 20% in required communication rounds. The second is FL with feature fusion (FedFusion). By aggregating the features from both the local and global models, we achieve higher accuracy at fewer communication costs. Furthermore, the feature fusion modules offer better initialization for newly incoming clients and thus speed up the process of convergence. Experiments in popular FL scenarios show that our FedFusion outperforms baselines in both accuracy and generalization ability while reducing the number of required communication rounds by more than 60%.
Comyco: Quality-Aware Adaptive Video Streaming via Imitation Learning
Aug 06, 2019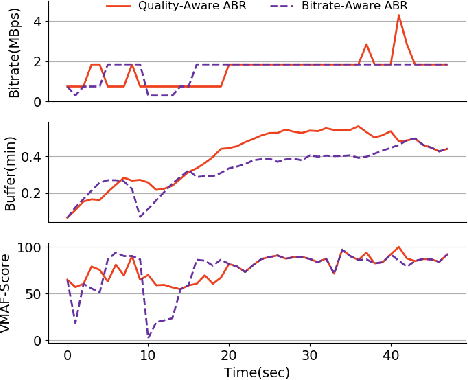


Learning-based Adaptive Bit Rate~(ABR) method, aiming to learn outstanding strategies without any presumptions, has become one of the research hotspots for adaptive streaming. However, it is still suffering from several issues, i.e., low sample efficiency and lack of awareness of the video quality information. In this paper, we propose Comyco, a video quality-aware ABR approach that enormously improves the learning-based methods by tackling the above issues. Comyco trains the policy via imitating expert trajectories given by the instant solver, which can not only avoid redundant exploration but also make better use of the collected samples. Meanwhile, Comyco attempts to pick the chunk with higher perceptual video qualities rather than video bitrates. To achieve this, we construct Comyco's neural network architecture, video datasets and QoE metrics with video quality features. Using trace-driven and real-world experiments, we demonstrate significant improvements of Comyco's sample efficiency in comparison to prior work, with 1700x improvements in terms of the number of samples required and 16x improvements on training time required. Moreover, results illustrate that Comyco outperforms previously proposed methods, with the improvements on average QoE of 7.5% - 16.79%. Especially, Comyco also surpasses state-of-the-art approach Pensieve by 7.37% on average video quality under the same rebuffering time.
Competitive Co-evolution for Dynamic Constrained Optimisation
Jul 31, 2019
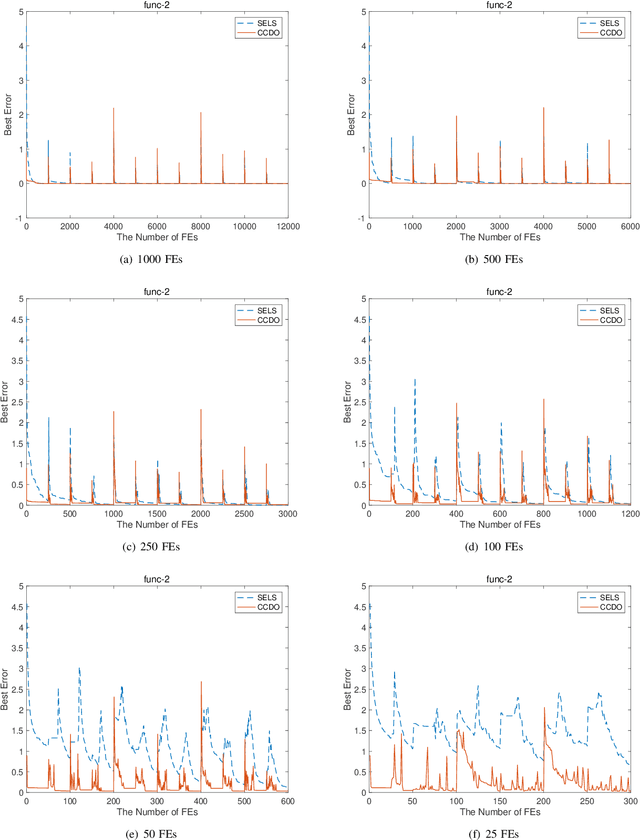
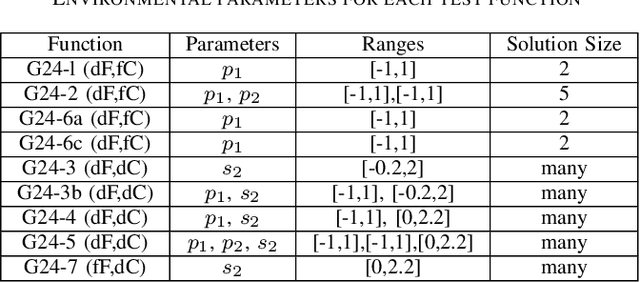

Dynamic constrained optimisation problems (DCOPs) widely exist in the real world due to frequently changing factors influencing the environment. Many dynamic optimisation methods such as diversity-driven methods, memory and prediction methods offer different strategies to deal with environmental changes. However, when DCOPs change very fast or have very limited time for the algorithm to react, the potential of these methods is limited due to time shortage for re-optimisation and adaptation. This is especially true for population-based dynamic optimisation methods, which normally need quite a few fitness evaluations to find a near-optimum solution. To address this issue, this paper proposes to tackle fast-changing DCOPs through a smart combination of offline and online optimisation. The offline optimisation aims to prepare a set of good solutions for all possible environmental changes beforehand. With this solution set, the online optimisation aims to react quickly to each truly happening environmental change by doing optimisation on the set. To find this solution set, this paper further proposes to use competitive co-evolution for offline optimisation by co-evolving candidate solutions and environmental parameters. The experimental studies on a well-known benchmark test set of DCOPs show that the proposed method outperforms existing methods significantly especially when the environment changes very fast
Algorithm Portfolio for Individual-based Surrogate-Assisted Evolutionary Algorithms
Apr 22, 2019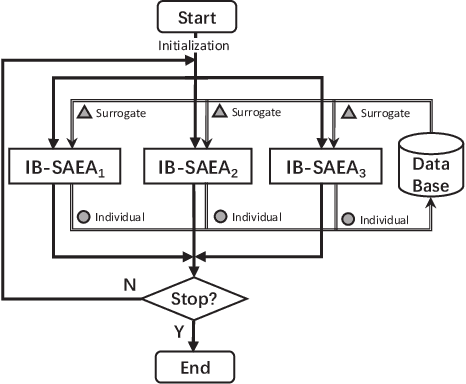
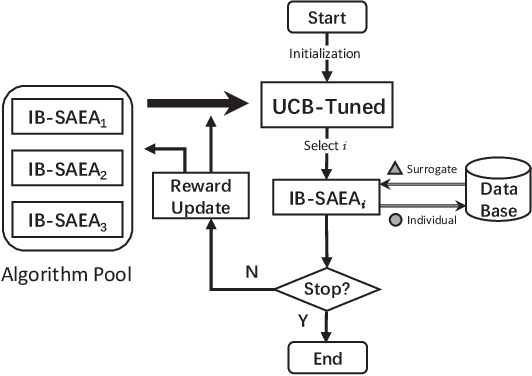
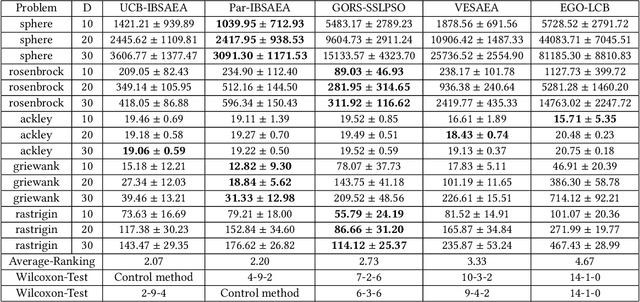
Surrogate-assisted evolutionary algorithms (SAEAs) are powerful optimisation tools for computationally expensive problems (CEPs). However, a randomly selected algorithm may fail in solving unknown problems due to no free lunch theorems, and it will cause more computational resource if we re-run the algorithm or try other algorithms to get a much solution, which is more serious in CEPs. In this paper, we consider an algorithm portfolio for SAEAs to reduce the risk of choosing an inappropriate algorithm for CEPs. We propose two portfolio frameworks for very expensive problems in which the maximal number of fitness evaluations is only 5 times of the problem's dimension. One framework named Par-IBSAEA runs all algorithm candidates in parallel and a more sophisticated framework named UCB-IBSAEA employs the Upper Confidence Bound (UCB) policy from reinforcement learning to help select the most appropriate algorithm at each iteration. An effective reward definition is proposed for the UCB policy. We consider three state-of-the-art individual-based SAEAs on different problems and compare them to the portfolios built from their instances on several benchmark problems given limited computation budgets. Our experimental studies demonstrate that our proposed portfolio frameworks significantly outperform any single algorithm on the set of benchmark problems.
Learning Topological Representation for Networks via Hierarchical Sampling
Feb 15, 2019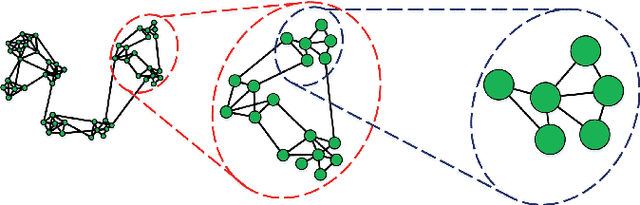
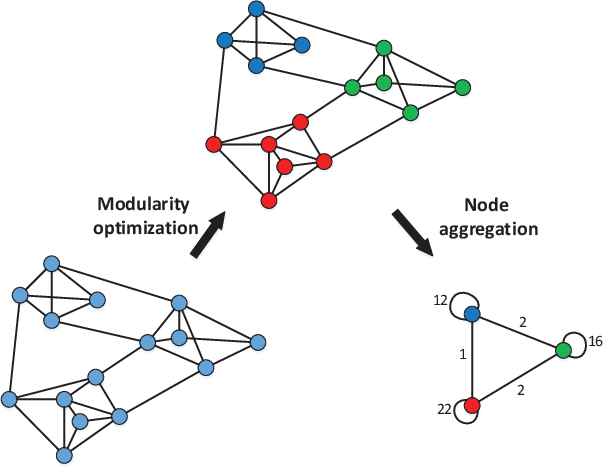
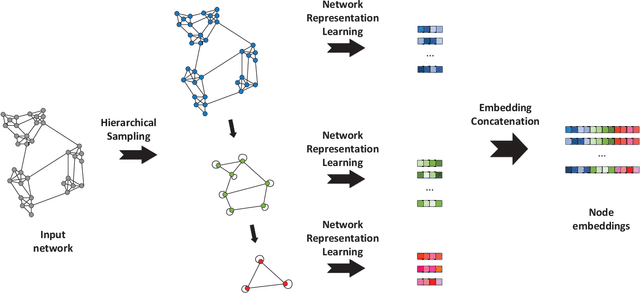
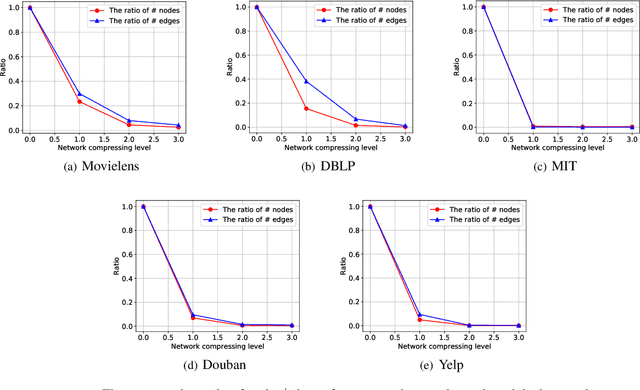
The topological information is essential for studying the relationship between nodes in a network. Recently, Network Representation Learning (NRL), which projects a network into a low-dimensional vector space, has been shown their advantages in analyzing large-scale networks. However, most existing NRL methods are designed to preserve the local topology of a network, they fail to capture the global topology. To tackle this issue, we propose a new NRL framework, named HSRL, to help existing NRL methods capture both the local and global topological information of a network. Specifically, HSRL recursively compresses an input network into a series of smaller networks using a community-awareness compressing strategy. Then, an existing NRL method is used to learn node embeddings for each compressed network. Finally, the node embeddings of the input network are obtained by concatenating the node embeddings from all compressed networks. Empirical studies for link prediction on five real-world datasets demonstrate the advantages of HSRL over state-of-the-art methods.
Representation Learning for Heterogeneous Information Networks via Embedding Events
Jan 29, 2019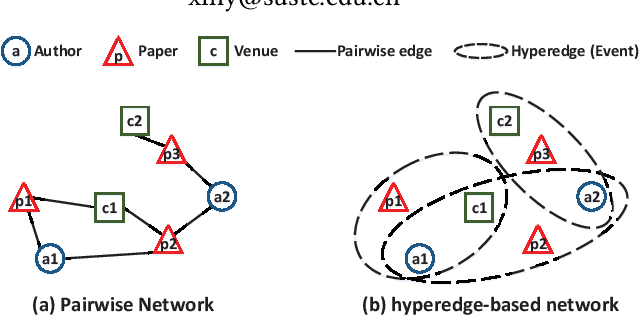

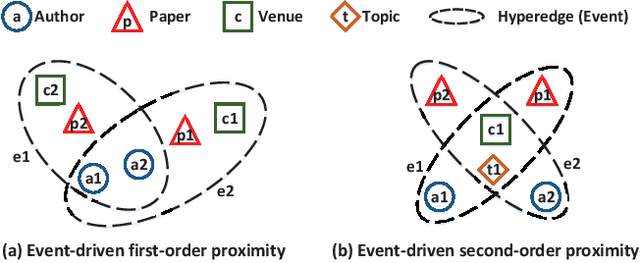
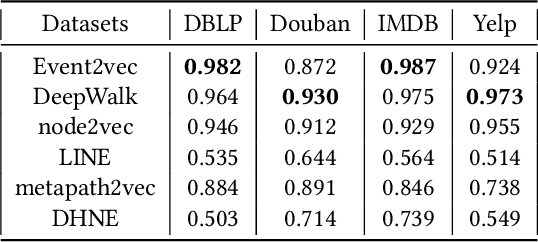
Network representation learning (NRL) has been widely used to help analyze large-scale networks through mapping original networks into a low-dimensional vector space. However, existing NRL methods ignore the impact of properties of relations on the object relevance in heterogeneous information networks (HINs). To tackle this issue, this paper proposes a new NRL framework, called Event2vec, for HINs to consider both quantities and properties of relations during the representation learning process. Specifically, an event (i.e., a complete semantic unit) is used to represent the relation among multiple objects, and both event-driven first-order and second-order proximities are defined to measure the object relevance according to the quantities and properties of relations. We theoretically prove how event-driven proximities can be preserved in the embedding space by Event2vec, which utilizes event embeddings to facilitate learning the object embeddings. Experimental studies demonstrate the advantages of Event2vec over state-of-the-art algorithms on four real-world datasets and three network analysis tasks (including network reconstruction, link prediction, and node classification).
Voronoi-based Efficient Surrogate-assisted Evolutionary Algorithm for Very Expensive Problems
Jan 17, 2019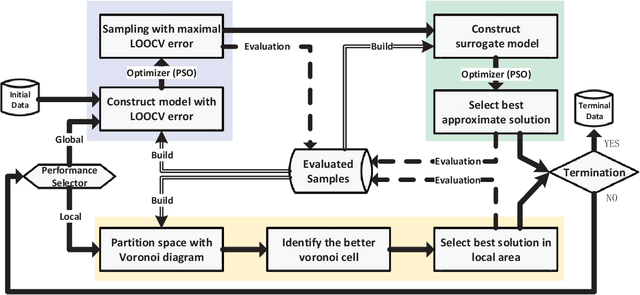
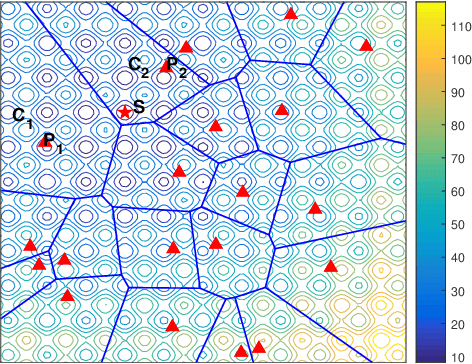
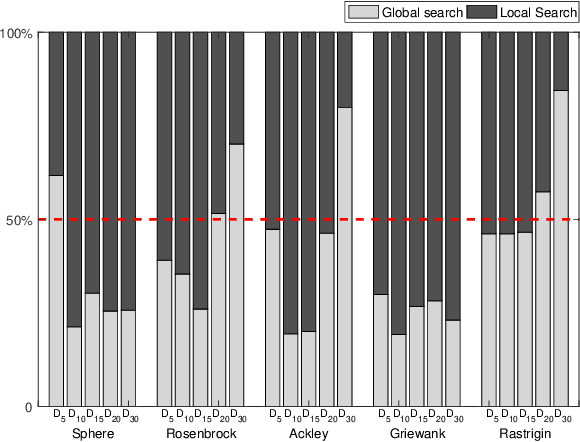
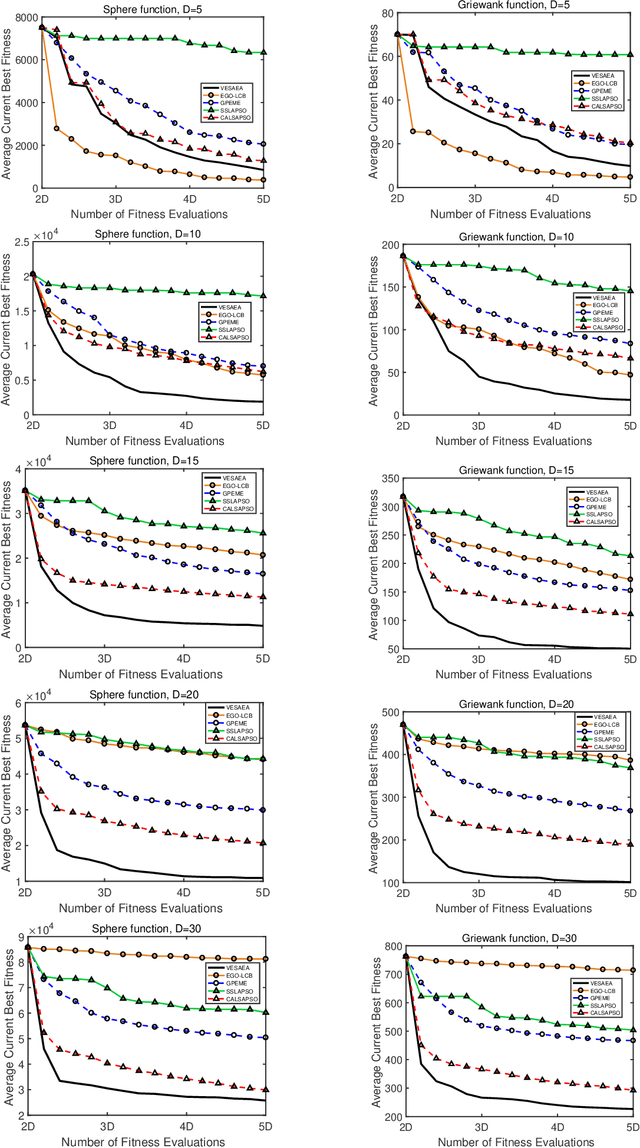
Very expensive problems are very common in practical system that one fitness evaluation costs several hours or even days. Surrogate assisted evolutionary algorithms (SAEAs) have been widely used to solve this crucial problem in the past decades. However, most studied SAEAs focus on solving problems with a budget of at least ten times of the dimension of problems which is unacceptable in many very expensive real-world problems. In this paper, we employ Voronoi diagram to boost the performance of SAEAs and propose a novel framework named Voronoi-based efficient surrogate assisted evolutionary algorithm (VESAEA) for very expensive problems, in which the optimization budget, in terms of fitness evaluations, is only 5 times of the problem's dimension. In the proposed framework, the Voronoi diagram divides the whole search space into several subspace and then the local search is operated in some potentially better subspace. Additionally, in order to trade off the exploration and exploitation, the framework involves a global search stage developed by combining leave-one-out cross-validation and radial basis function surrogate model. A performance selector is designed to switch the search dynamically and automatically between the global and local search stages. The empirical results on a variety of benchmark problems demonstrate that the proposed framework significantly outperforms several state-of-art algorithms with extremely limited fitness evaluations. Besides, the efficacy of Voronoi-diagram is furtherly analyzed, and the results show its potential to optimize very expensive problems.