 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-to-Phy3D: Physically Conform Online 3D Object Generation with LLMs
Jun 11, 2025



The emergence of generative artificial intelligence (GenAI) and large language models (LLMs) has revolutionized the landscape of digital content creation in different modalities. However, its potential use in Physical AI for engineering design, where the production of physically viable artifacts is paramount, remains vastly underexplored. The absence of physical knowledge in existing LLM-to-3D models often results in outputs detached from real-world physical constraints. To address this gap, we introduce LLM-to-Phy3D, a physically conform online 3D object generation that enables existing LLM-to-3D models to produce physically conforming 3D objects on the fly. LLM-to-Phy3D introduces a novel online black-box refinement loop that empowers large language models (LLMs) through synergistic visual and physics-based evaluations. By delivering directional feedback in an iterative refinement process, LLM-to-Phy3D actively drives the discovery of prompts that yield 3D artifacts with enhanced physical performance and greater geometric novelty relative to reference objects, marking a substantial contribution to AI-driven generative design. Systematic evaluations of LLM-to-Phy3D, supported by ablation studies in vehicle design optimization, reveal various LLM improvements gained by 4.5% to 106.7% in producing physically conform target domain 3D designs over conventional LLM-to-3D models. The encouraging results suggest the potential general use of LLM-to-Phy3D in Physical AI for scientific and engineering applications.
Controlled Agentic Planning & Reasoning for Mechanism Synthesis
May 23, 2025This work presents a dual-agent Large Language Model (LLM)-based reasoning method for mechanism synthesis, capable of reasoning at both linguistic and symbolic levels to generate geometrical and dynamic outcomes. The model consists of a composition of well-defined functions that, starting from a natural language specification, references abstract properties through supporting equations, generates and parametrizes simulation code, and elicits feedback anchor points using symbolic regression and distance functions. This process closes an actionable refinement loop at the linguistic and symbolic layers. The approach is shown to be both effective and convergent in the context of planar mechanisms. Additionally, we introduce MSynth, a novel benchmark for planar mechanism synthesis, and perform a comprehensive analysis of the impact of the model components. We further demonstrate that symbolic regression prompts unlock mechanistic insights only when applied to sufficiently large architectures.
From Idea to CAD: A Language Model-Driven Multi-Agent System for Collaborative Design
Mar 06, 2025Creating digital models using Computer Aided Design (CAD) is a process that requires in-depth expertise. In industrial product development, this process typically involves entire teams of engineers, spanning requirements engineering, CAD itself, and quality assurance. We present an approach that mirrors this team structure with a Vision Language Model (VLM)-based Multi Agent System, with access to parametric CAD tooling and tool documentation. Combining agents for requirements engineering, CAD engineering, and vision-based quality assurance, a model is generated automatically from sketches and/ or textual descriptions. The resulting model can be refined collaboratively in an iterative validation loop with the user. Our approach has the potential to increase the effectiveness of design processes, both for industry experts and for hobbyists who create models for 3D printing. We demonstrate the potential of the architecture at the example of various design tasks and provide several ablations that show the benefits of the architecture's individual components.
LLM2FEA: Discover Novel Designs with Generative Evolutionary Multitasking
Jun 21, 2024



The rapid research and development of generative artificial intelligence has enabled the generation of high-quality images, text, and 3D models from text prompts. This advancement impels an inquiry into whether these models can be leveraged to create digital artifacts for both creative and engineering applications. Drawing on innovative designs from other domains may be one answer to this question, much like the historical practice of ``bionics", where humans have sought inspiration from nature's exemplary designs. This raises the intriguing possibility of using generative models to simultaneously tackle design tasks across multiple domains, facilitating cross-domain learning and resulting in a series of innovative design solutions. In this paper, we propose LLM2FEA as the first attempt to discover novel designs in generative models by transferring knowledge across multiple domains. By utilizing a multi-factorial evolutionary algorithm (MFEA) to drive a large language model, LLM2FEA integrates knowledge from various fields to generate prompts that guide the generative model in discovering novel and practical objects. Experimental results in the context of 3D aerodynamic design verify the discovery capabilities of the proposed LLM2FEA. The designs generated by LLM2FEA not only satisfy practicality requirements to a certain degree but also feature novel and aesthetically pleasing shapes, demonstrating the potential applications of LLM2FEA in discovery tasks.
Generative AI-based Prompt Evolution Engineering Design Optimization With Vision-Language Model
Jun 14, 2024



Engineering design optimization requires an efficient combination of a 3D shape representation, an optimization algorithm, and a design performance evaluation method, which is often computationally expensive. We present a prompt evolution design optimization (PEDO) framework contextualized in a vehicle design scenario that leverages a vision-language model for penalizing impractical car designs synthesized by a generative model. The backbone of our framework is an evolutionary strategy coupled with an optimization objective function that comprises a physics-based solver and a vision-language model for practical or functional guidance in the generated car designs. In the prompt evolutionary search, the optimizer iteratively generates a population of text prompts, which embed user specifications on the aerodynamic performance and visual preferences of the 3D car designs. Then, in addition to the computational fluid dynamics simulations, the pre-trained vision-language model is used to penalize impractical designs and, thus, foster the evolutionary algorithm to seek more viable designs. Our investigations on a car design optimization problem show a wide spread of potential car designs generated at the early phase of the search, which indicates a good diversity of designs in the initial populations, and an increase of over 20\% in the probability of generating practical designs compared to a baseline framework without using a vision-language model. Visual inspection of the designs against the performance results demonstrates prompt evolution as a very promising paradigm for finding novel designs with good optimization performance while providing ease of use in specifying design specifications and preferences via a natural language interface.
Large Language and Text-to-3D Models for Engineering Design Optimization
Jul 03, 2023



The current advances in generative AI for learning large neural network models with the capability to produce essays, images, music and even 3D assets from text prompts create opportunities for a manifold of disciplines. In the present paper, we study the potential of deep text-to-3D models in the engineering domain, with focus on the chances and challenges when integrating and interacting with 3D assets in computational simulation-based design optimization. In contrast to traditional design optimization of 3D geometries that often searches for the optimum designs using numerical representations, such as B-Spline surface or deformation parameters in vehicle aerodynamic optimization, natural language challenges the optimization framework by requiring a different interpretation of variation operators while at the same time may ease and motivate the human user interaction. Here, we propose and realize a fully automated evolutionary design optimization framework using Shap-E, a recently published text-to-3D asset network by OpenAI, in the context of aerodynamic vehicle optimization. For representing text prompts in the evolutionary optimization, we evaluate (a) a bag-of-words approach based on prompt templates and Wordnet samples, and (b) a tokenisation approach based on prompt templates and the byte pair encoding method from GPT4. Our main findings from the optimizations indicate that, first, it is important to ensure that the designs generated from prompts are within the object class of application, i.e. diverse and novel designs need to be realistic, and, second, that more research is required to develop methods where the strength of text prompt variations and the resulting variations of the 3D designs share causal relations to some degree to improve the optimization.
Knowledge Transfer for Dynamic Multi-objective Optimization with a Changing Number of Objectives
Jun 19, 2023



Different from most other dynamic multi-objective optimization problems (DMOPs), DMOPs with a changing number of objectives usually result in expansion or contraction of the Pareto front or Pareto set manifold. Knowledge transfer has been used for solving DMOPs, since it can transfer useful information from solving one problem instance to solve another related problem instance. However, we show that the state-of-the-art transfer algorithm for DMOPs with a changing number of objectives lacks sufficient diversity when the fitness landscape and Pareto front shape present nonseparability, deceptiveness or other challenging features. Therefore, we propose a knowledge transfer dynamic multi-objective evolutionary algorithm (KTDMOEA) to enhance population diversity after changes by expanding/contracting the Pareto set in response to an increase/decrease in the number of objectives. This enables a solution set with good convergence and diversity to be obtained after optimization. Comprehensive studies using 13 DMOP benchmarks with a changing number of objectives demonstrate that our proposed KTDMOEA is successful in enhancing population diversity compared to state-of-the-art algorithms, improving optimization especially in fast changing environments.
A Novel Generalised Meta-Heuristic Framework for Dynamic Capacitated Arc Routing Problems
Apr 14, 2021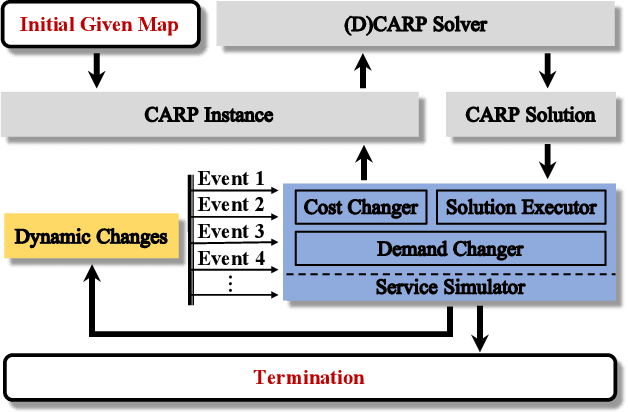
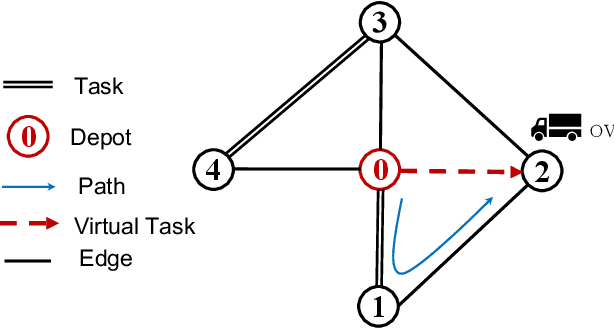
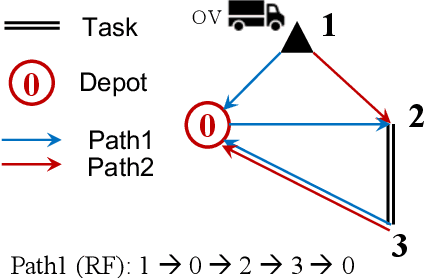
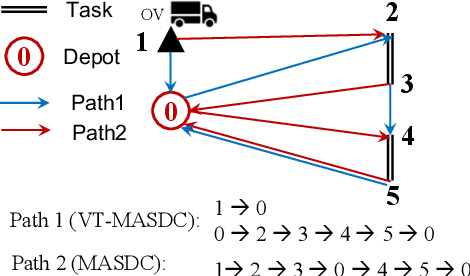
The capacitated arc routing problem (CARP) is a challenging combinatorial optimisation problem abstracted from typical real-world applications, like waste collection and mail delivery. However, few studies considered dynamic changes during the vehicles' service, which can make the original schedule infeasible or obsolete. The few existing studies are limited by dynamic scenarios that can suffer single types of dynamic events, and by algorithms that rely on special operators or representations, being unable to benefit from the wealth of contributions provided by the static CARP literature. Here, we provide the first mathematical formulation for dynamic CARP (DCARP) and design a simulation system to execute the CARP solutions and generate DCARP instances with several common dynamic events. We then propose a novel framework able to generalise all existing static CARP optimisation algorithms so that they can cope with DCARP instances. The framework has the option to enhance optimisation performance for DCARP instances based on a restart strategy that makes no use of past history, and a sequence transfer strategy that benefits from past optimisation experience. Empirical studies are conducted on a wide range of DCARP instances. The results highlight the need for tackling dynamic changes and show that the proposed framework significantly improves over existing algorithms.
Generating and Adapting to Diverse Ad-Hoc Cooperation Agents in Hanabi
Apr 30, 2020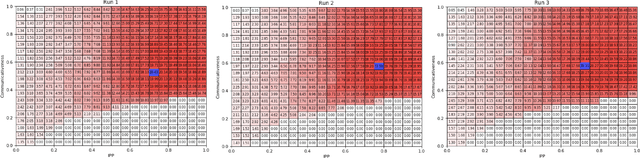
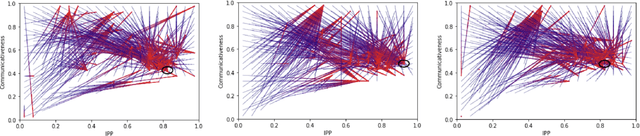
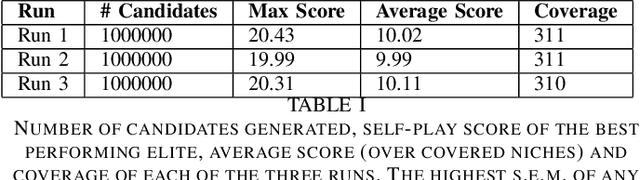

Hanabi is a cooperative game that brings the problem of modeling other players to the forefront. In this game, coordinated groups of players can leverage pre-established conventions to great effect, but playing in an ad-hoc setting requires agents to adapt to its partner's strategies with no previous coordination. Evaluating an agent in this setting requires a diverse population of potential partners, but so far, the behavioral diversity of agents has not been considered in a systematic way. This paper proposes Quality Diversity algorithms as a promising class of algorithms to generate diverse populations for this purpose, and generates a population of diverse Hanabi agents using MAP-Elites. We also postulate that agents can benefit from a diverse population during training and implement a simple "meta-strategy" for adapting to an agent's perceived behavioral niche. We show this meta-strategy can work better than generalist strategies even outside the population it was trained with if its partner's behavioral niche can be correctly inferred, but in practice a partner's behavior depends and interferes with the meta-agent's own behavior, suggesting an avenue for future research in characterizing another agent's behavior during gameplay.
Evaluating the Rainbow DQN Agent in Hanabi with Unseen Partners
Apr 28, 2020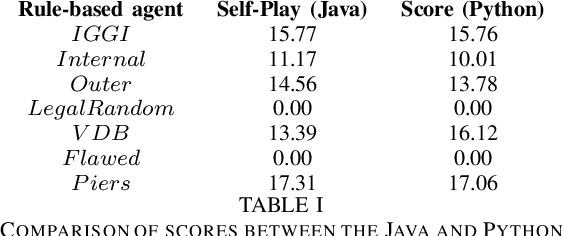
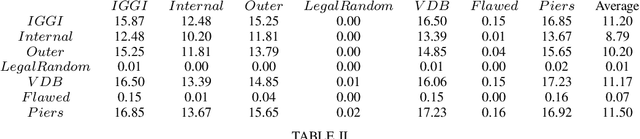

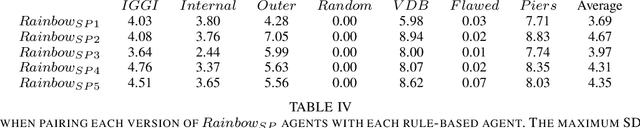
Hanabi is a cooperative game that challenges exist-ing AI techniques due to its focus on modeling the mental states ofother players to interpret and predict their behavior. While thereare agents that can achieve near-perfect scores in the game byagreeing on some shared strategy, comparatively little progresshas been made in ad-hoc cooperation settings, where partnersand strategies are not known in advance. In this paper, we showthat agents trained through self-play using the popular RainbowDQN architecture fail to cooperate well with simple rule-basedagents that were not seen during training and, conversely, whenthese agents are trained to play with any individual rule-basedagent, or even a mix of these agents, they fail to achieve goodself-play scores.