 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Moving Peaks Benchmark
Jun 11, 2021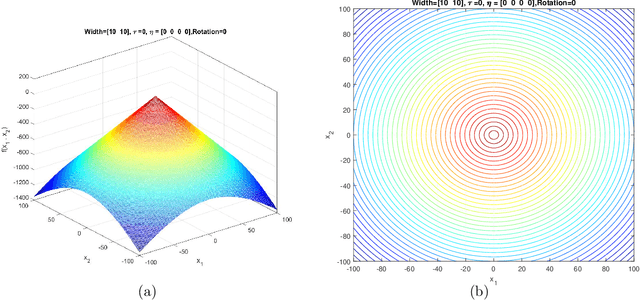
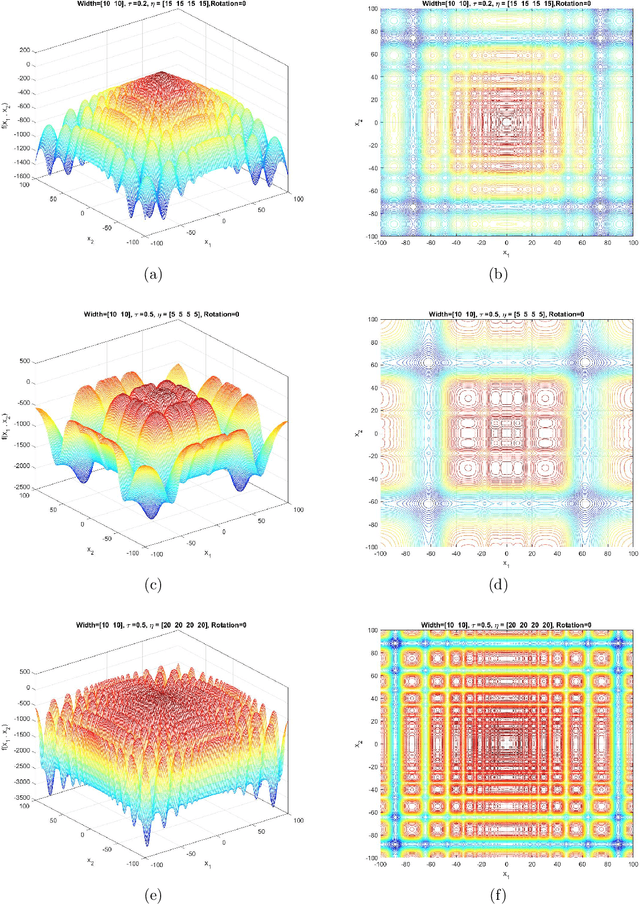
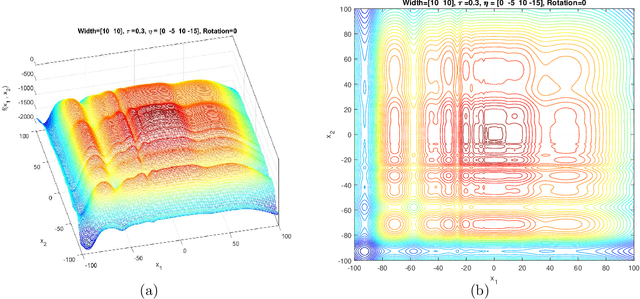
This document describes the Generalized Moving Peaks Benchmark (GMPB) that generates continuous dynamic optimization problem instances. The landscapes generated by GMPB are constructed by assembling several components with a variety of controllable characteristics ranging from unimodal to highly multimodal, symmetric to highly asymmetric, smooth to highly irregular, and various degrees of variable interaction and ill-conditioning. In this document, we explain how these characteristics can be generated by different parameter settings of GMPB. The MATLAB source code of GMPB is also explained. This document forms the basis for a range of competitions on Evolutionary Continuous Dynamic Optimization in the upcoming well-known conferences.
Context-Based Soft Actor Critic for Environments with Non-stationary Dynamics
May 10, 2021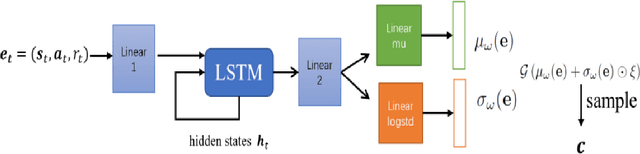
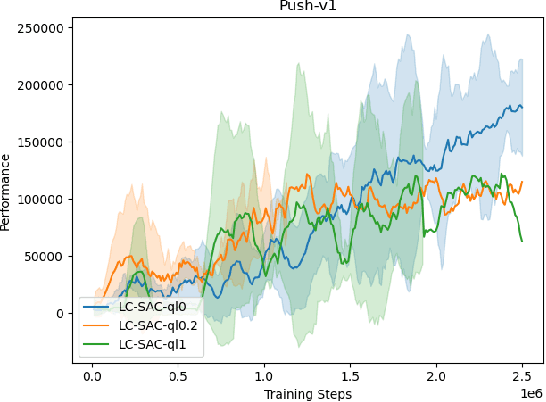
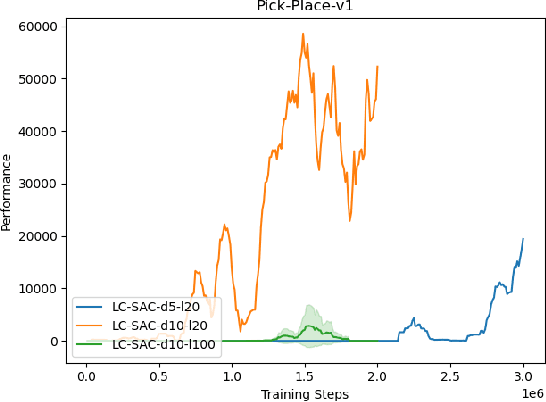
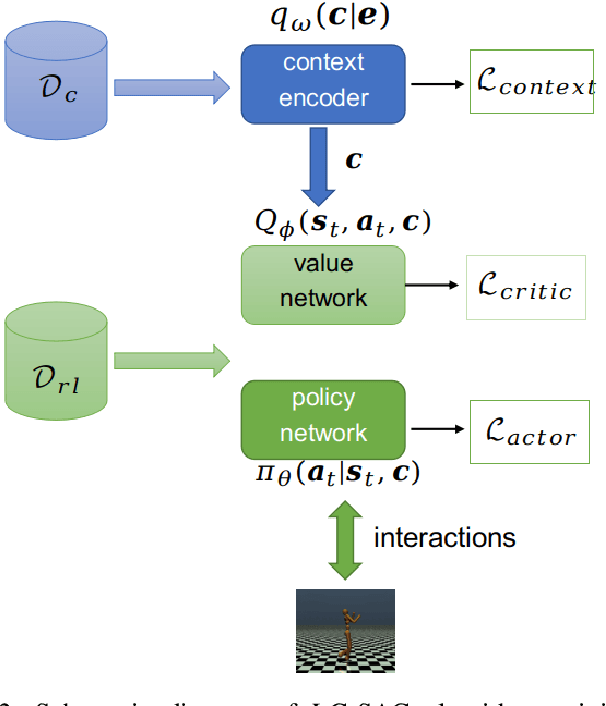
The performance of deep reinforcement learning methods prone to degenerate when applied to environments with non-stationary dynamics. In this paper, we utilize the latent context recurrent encoders motivated by recent Meta-RL materials, and propose the Latent Context-based Soft Actor Critic (LC-SAC) method to address aforementioned issues. By minimizing the contrastive prediction loss function, the learned context variables capture the information of the environment dynamics and the recent behavior of the agent. Then combined with the soft policy iteration paradigm, the LC-SAC method alternates between soft policy evaluation and soft policy improvement until it converges to the optimal policy. Experimental results show that the performance of LC-SAC is significantly better than the SAC algorithm on the MetaWorld ML1 tasks whose dynamics changes drasticly among different episodes, and is comparable to SAC on the continuous control benchmark task MuJoCo whose dynamics changes slowly or doesn't change between different episodes. In addition, we also conduct relevant experiments to determine the impact of different hyperparameter settings on the performance of the LC-SAC algorithm and give the reasonable suggestions of hyperparameter setting.
Decomposed Soft Actor-Critic Method for Cooperative Multi-Agent Reinforcement Learning
May 08, 2021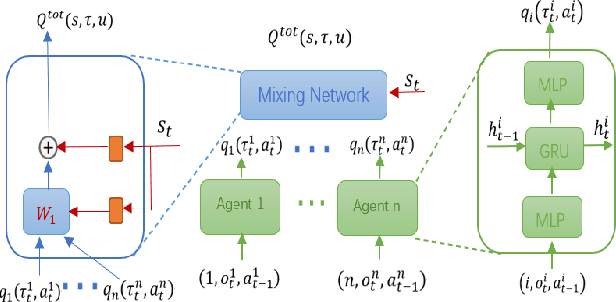
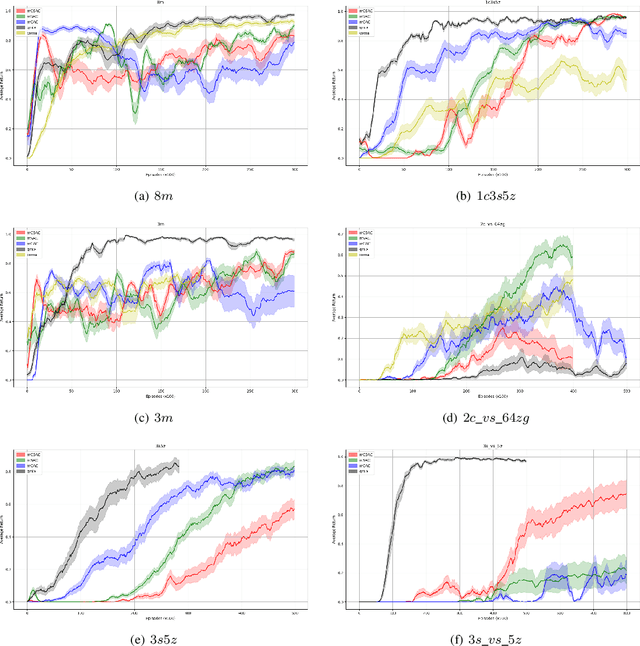
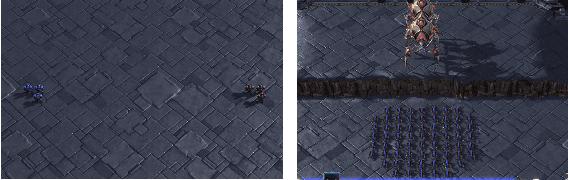
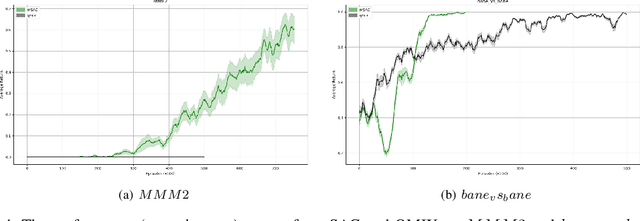
Deep reinforcement learning methods have shown great performance on many challenging cooperative multi-agent tasks. Two main promising research directions are multi-agent value function decomposition and multi-agent policy gradients. In this paper, we propose a new decomposed multi-agent soft actor-critic (mSAC) method, which effectively combines the advantages of the aforementioned two methods. The main modules include decomposed Q network architecture, discrete probabilistic policy and counterfactual advantage function (optinal). Theoretically, mSAC supports efficient off-policy learning and addresses credit assignment problem partially in both discrete and continuous action spaces. Tested on StarCraft II micromanagement cooperative multiagent benchmark, we empirically investigate the performance of mSAC against its variants and analyze the effects of the different components. Experimental results demonstrate that mSAC significantly outperforms policy-based approach COMA, and achieves competitive results with SOTA value-based approach Qmix on most tasks in terms of asymptotic perfomance metric. In addition, mSAC achieves pretty good results on large action space tasks, such as 2c_vs_64zg and MMM2.
When Non-Elitism Meets Time-Linkage Problems
Apr 14, 2021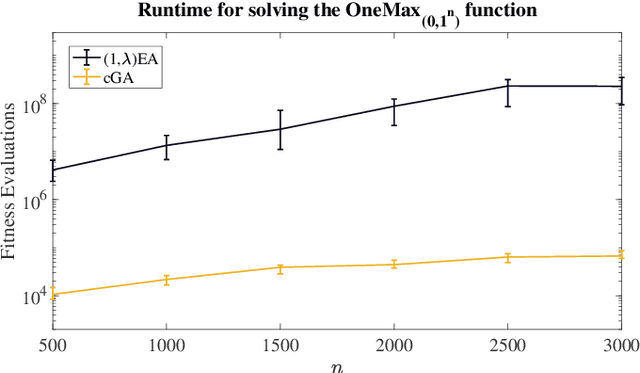
Many real-world applications have the time-linkage property, and the only theoretical analysis is recently given by Zheng, et al. (TEVC 2021) on their proposed time-linkage OneMax problem, OneMax$_{(0,1^n)}$. However, only two elitist algorithms (1+1)EA and ($\mu$+1)EA are analyzed, and it is unknown whether the non-elitism mechanism could help to escape the local optima existed in OneMax$_{(0,1^n)}$. In general, there are few theoretical results on the benefits of the non-elitism in evolutionary algorithms. In this work, we analyze on the influence of the non-elitism via comparing the performance of the elitist (1+$\lambda$)EA and its non-elitist counterpart (1,$\lambda$)EA. We prove that with probability $1-o(1)$ (1+$\lambda$)EA will get stuck in the local optima and cannot find the global optimum, but with probability $1$, (1,$\lambda$)EA can reach the global optimum and its expected runtime is $O(n^{3+c}\log n)$ with $\lambda=c \log_{\frac{e}{e-1}} n$ for the constant $c\ge 1$. Noting that a smaller offspring size is helpful for escaping from the local optima, we further resort to the compact genetic algorithm where only two individuals are sampled to update the probabilistic model, and prove its expected runtime of $O(n^3\log n)$. Our computational experiments also verify the efficiency of the two non-elitist algorithms.
A Novel Generalised Meta-Heuristic Framework for Dynamic Capacitated Arc Routing Problems
Apr 14, 2021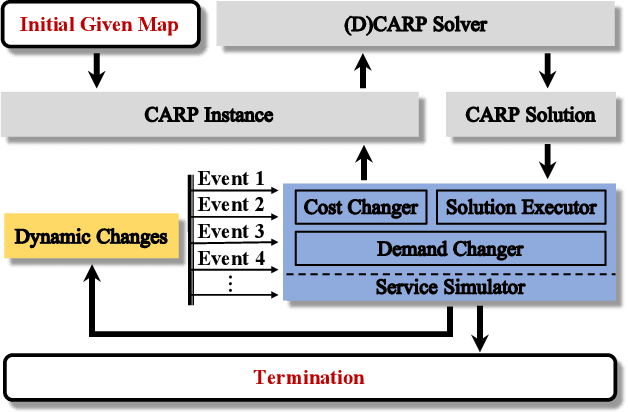
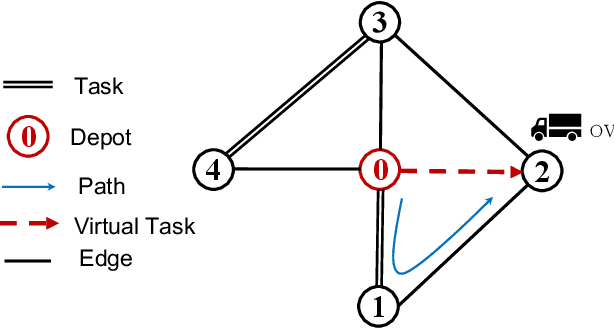
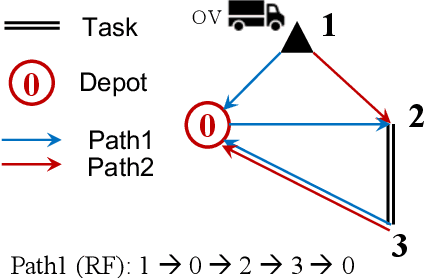
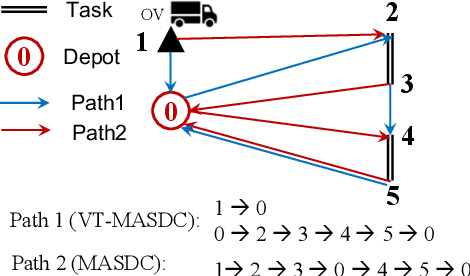
The capacitated arc routing problem (CARP) is a challenging combinatorial optimisation problem abstracted from typical real-world applications, like waste collection and mail delivery. However, few studies considered dynamic changes during the vehicles' service, which can make the original schedule infeasible or obsolete. The few existing studies are limited by dynamic scenarios that can suffer single types of dynamic events, and by algorithms that rely on special operators or representations, being unable to benefit from the wealth of contributions provided by the static CARP literature. Here, we provide the first mathematical formulation for dynamic CARP (DCARP) and design a simulation system to execute the CARP solutions and generate DCARP instances with several common dynamic events. We then propose a novel framework able to generalise all existing static CARP optimisation algorithms so that they can cope with DCARP instances. The framework has the option to enhance optimisation performance for DCARP instances based on a restart strategy that makes no use of past history, and a sequence transfer strategy that benefits from past optimisation experience. Empirical studies are conducted on a wide range of DCARP instances. The results highlight the need for tackling dynamic changes and show that the proposed framework significantly improves over existing algorithms.
Memetic Search for Vehicle Routing with Simultaneous Pickup-Delivery and Time Windows
Nov 19, 2020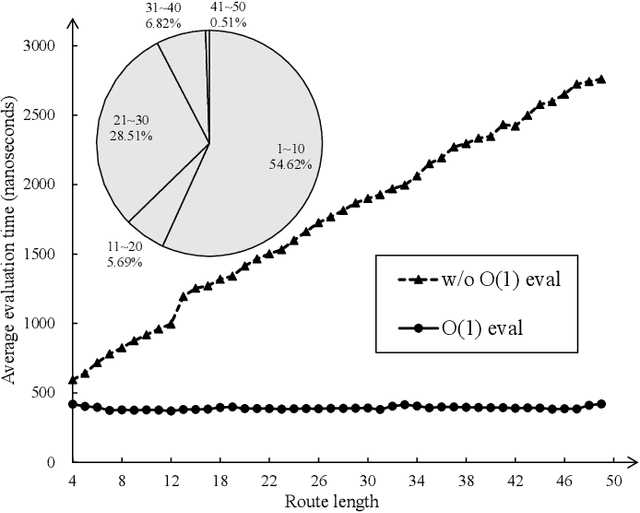
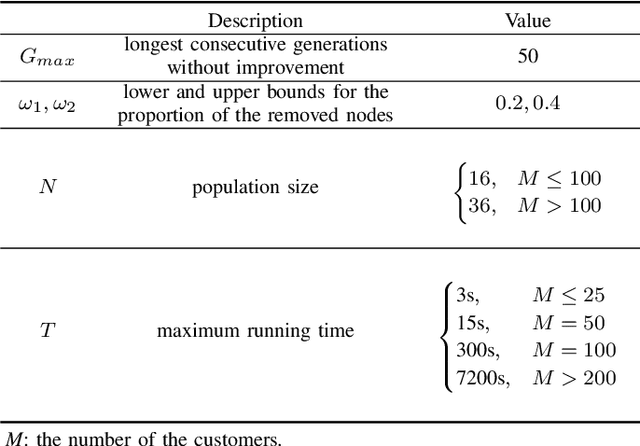
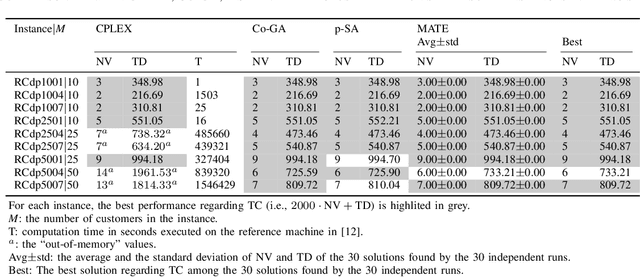
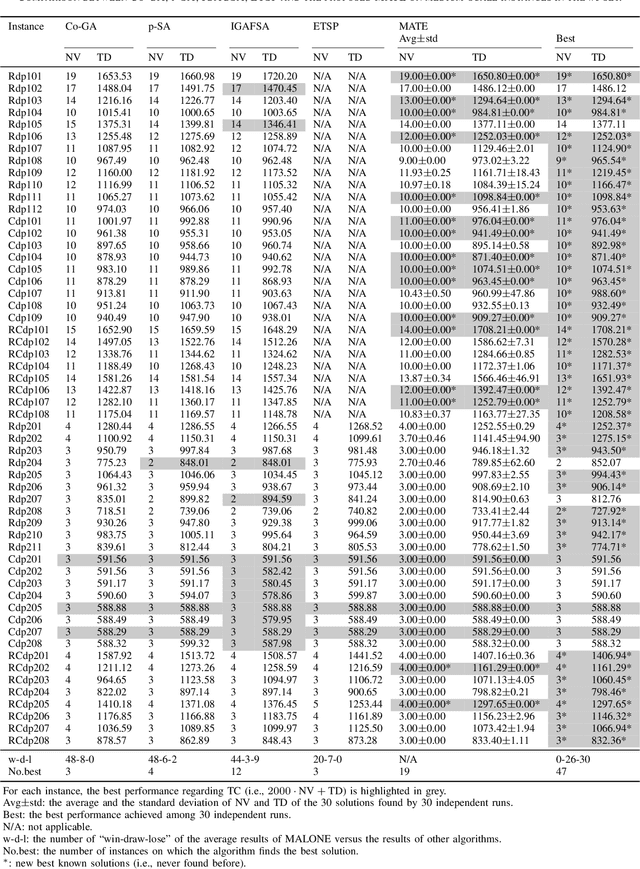
The vehicle routing problem with simultaneous pickup-delivery and time windows (VRPSPDTW) has attracted much attention in the last decade, due to its wide application in modern logistics involving bi-directional flow of goods. In this paper, we propose a memetic algorithm with efficient local search and extended neighborhood, dubbed MATE, for solving this problem. The novelty of MATE lies in three aspects: 1) an initialization procedure which integrates an existing heuristic into the population-based search framework, in an intelligent way; 2) a new crossover involving route inheritance and regret-based node reinsertion; 3) a highly-effective local search procedure which could flexibly search in a large neighborhood by switching between move operators with different step sizes, while keeping low computational complexity. Experimental results on public benchmark show that MATE consistently outperforms all the state-of-the-art algorithms, and notably, finds new best-known solutions on 44 instances (65 instances in total). A new benchmark of large-scale instances, derived from a real-world application of the JD logistics, is also introduced, which could serve as a new and more practical test set for future research.
Robust Reinforcement Learning for General Video Game Playing
Nov 11, 2020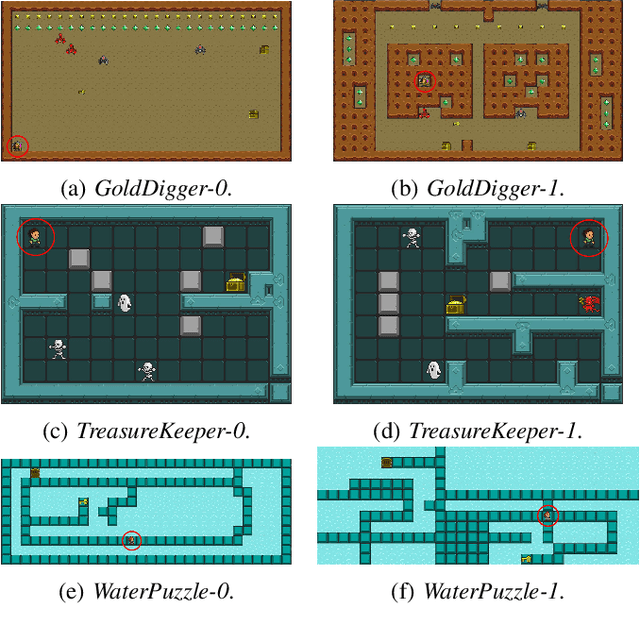
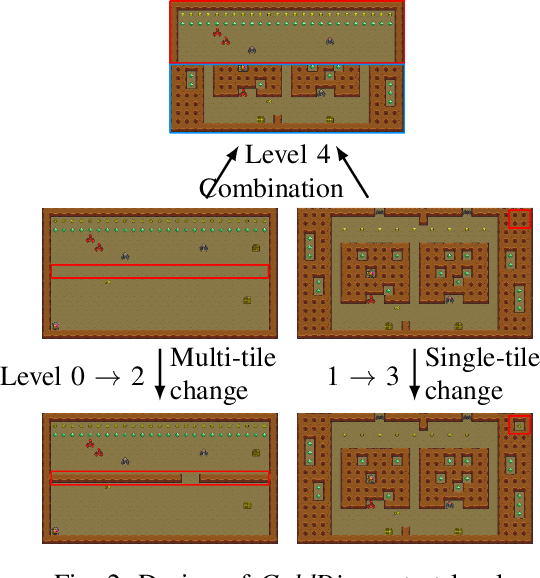
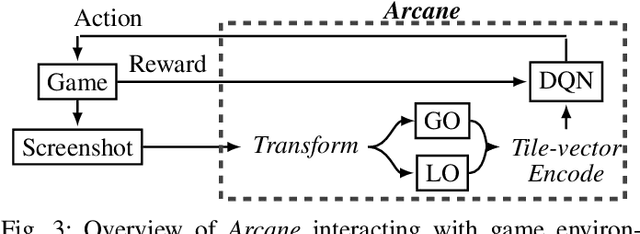
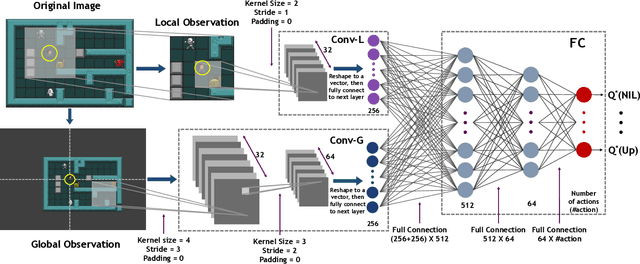
Reinforcement learning has successfully learned to play challenging board and video games. However, its generalization ability remains under-explored. The General Video Game AI Learning Competition aims at designing agents that are capable of learning to play different games levels that were unseen during training. This paper presents the games, entries and results of the 2020 General Video Game AI Learning Competition, held at the Sixteenth International Conference on Parallel Problem Solving from Nature and the 2020 IEEE Conference on Games. Three new games with sparse, periodic and dense rewards, respectively, were designed for this competition and the test levels were generated by adding minor perturbations to training levels or combining training levels. In this paper, we also design a reinforcement learning agent, called Arcane, for general video game playing. We assume that it is more likely to observe similar local information in different levels rather than global information. Therefore, instead of directly inputting a single, raw pixel-based screenshot of current game screen, Arcane takes the encoded, transformed global and local observations of the game screen as two simultaneous inputs, aiming at learning local information for playing new levels. Two versions of Arcane, using a stochastic or deterministic policy for decision-making during test, both show robust performance on the game set of the 2020 General Video Game AI Learning Competition.
Few-shots Parameter Tuning via Co-evolution
Jul 01, 2020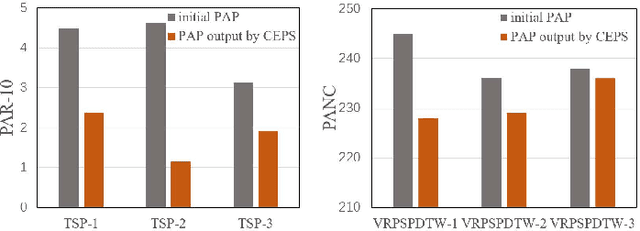


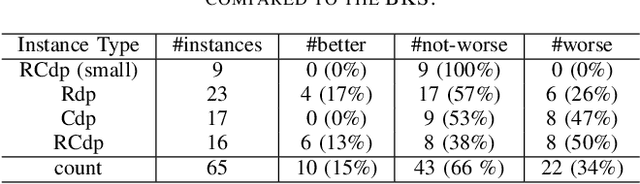
Generalization, i.e., the ability of addressing problem instances that are not available during the system design and development phase, is a critical goal for intelligent systems. A typical way to achieve good generalization is to exploit vast data to train a model. In the context of heuristic search, such a paradigm is termed parameter tuning or algorithm configuration, i.e., configuring the parameters of a search method based on a set of "training" problem instances. However, compared to its counterpart in machine learning, parameter tuning could more often suffer from the lack of training instances, and the obtained configuration may fail to generalize. This paper suggests competitive co-evolution as a remedy to this challenge and proposes a framework named Co-Evolution of Parameterized Search (CEPS). By alternately evolving a configuration population and an instance population, CEPS is capable of obtaining generalizable configurations with few training instances. The advantage of CEPS in improving generalization is analytically shown. Two concrete instantiations, namely CEPS-TSP and CEPS-VRPSPDTW, are also presented for the Traveling Salesman Problem (TSP) and the Vehicle Routing Problem with Simultaneous Pickup-Delivery and Time Windows (VRPSPDTW), respectively. Computational results on the two problems confirm the advantages of CEPS over state-of-the-art parameter tuning methods.
A Hybrid Evolutionary Algorithm for Reliable Facility Location Problem
Jun 27, 2020



The reliable facility location problem (RFLP) is an important research topic of operational research and plays a vital role in the decision-making and management of modern supply chain and logistics. Through solving RFLP, the decision-maker can obtain reliable location decisions under the risk of facilities' disruptions or failures. In this paper, we propose a novel model for the RFLP. Instead of assuming allocating a fixed number of facilities to each customer as in the existing works, we set the number of allocated facilities as an independent variable in our proposed model, which makes our model closer to the scenarios in real life but more difficult to be solved by traditional methods. To handle it, we propose EAMLS, a hybrid evolutionary algorithm, which combines a memorable local search (MLS) method and an evolutionary algorithm (EA). Additionally, a novel metric called l3-value is proposed to assist the analysis of the algorithm's convergence speed and exam the process of evolution. The experimental results show the effectiveness and superior performance of our EAMLS, compared to a CPLEX solver and a Genetic Algorithm (GA), on large-scale problems.
Continual Local Training for Better Initialization of Federated Models
May 26, 2020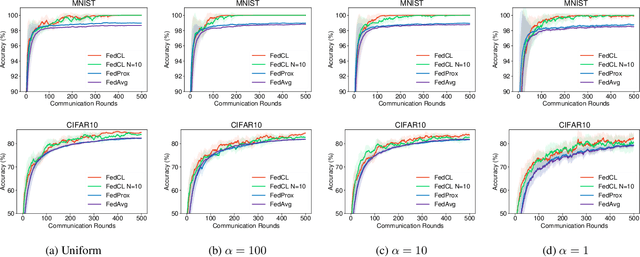
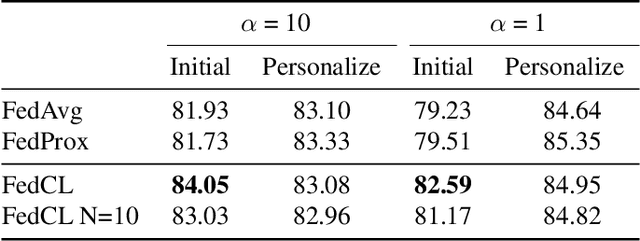
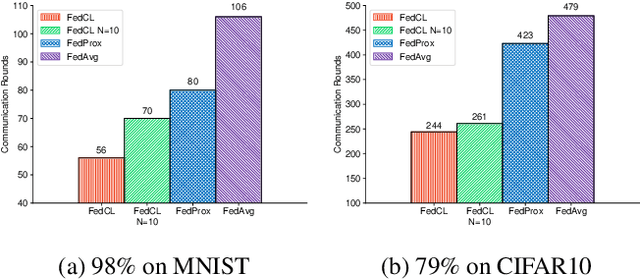
Federated learning (FL) refers to the learning paradigm that trains machine learning models directly in the decentralized systems consisting of smart edge devices without transmitting the raw data, which avoids the heavy communication costs and privacy concerns. Given the typical heterogeneous data distributions in such situations, the popular FL algorithm \emph{Federated Averaging} (FedAvg) suffers from weight divergence and thus cannot achieve a competitive performance for the global model (denoted as the \emph{initial performance} in FL) compared to centralized methods. In this paper, we propose the local continual training strategy to address this problem. Importance weights are evaluated on a small proxy dataset on the central server and then used to constrain the local training. With this additional term, we alleviate the weight divergence and continually integrate the knowledge on different local clients into the global model, which ensures a better generalization ability. Experiments on various FL settings demonstrate that our method significantly improves the initial performance of federated models with few extra communication costs.