 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning for Multi-Center Sepsis Early Prediction with Privacy-Preserving
Jun 03, 2026Privacy-sensitive and distributed characteristics of multi-center medical data bring severe obstacles to centralized modeling for accurate early prediction of sepsis. Federated learning (FL) has attracted growing attention as a promising framework for collaborative model development, as it allows multiple institutions to jointly train predictive models without directly sharing or centralizing raw data. Nevertheless, its practical performance, robustness, and privacy-preserving benefits remain insufficiently evaluated using real-world clinical datasets. To bridge this gap, this study systematically examines the application of federated learning to multi-center sepsis prediction. The experimental dataset consists of 648 clinically screened samples collected from three tertiary hospitals in China, with rigorous inclusion and exclusion criteria. We establish a centralized training paradigm as the performance baseline, and then implement a horizontal federated learning framework for distributed collaborative modeling. Extensive experimental results demonstrate that the federated learning-based model achieves highly comparable prediction accuracy to the centralized counterpart, while fundamentally avoiding privacy leakage. Further privacy security analysis verifies that malicious attackers cannot reconstruct the original patient data from the transmitted model parameters, indicating strong resistance against data reconstruction attacks. This work not only validates the practicality and security of federated learning in clinical sepsis prediction, but also provides a reliable and feasible solution for privacy-preserving multi-center medical collaboration.
Explainable Interictal Epileptiform Discharge Detection Method Based on Scalp EEG and Retrieval-Augmented Generation
Feb 15, 2026The detection of interictal epileptiform discharge (IED) is crucial for the diagnosis of epilepsy, but automated methods often lack interpretability. This study proposes IED-RAG, an explainable multimodal framework for joint IED detection and report generation. Our approach employs a dual-encoder to extract electrophysiological and semantic features, aligned via contrastive learning in a shared EEG-text embedding space. During inference, clinically relevant EEG-text pairs are retrieved from a vector database as explicit evidence to condition a large language model (LLM) for the generation of evidence-based reports. Evaluated on a private dataset from Wuhan Children's Hospital and the public TUH EEG Events Corpus (TUEV), the framework achieved balanced accuracies of 89.17\% and 71.38\%, with BLEU scores of 89.61\% and 64.14\%, respectively. The results demonstrate that retrieval of explicit evidence enhances both diagnostic performance and clinical interpretability compared to standard black-box methods.
A2RAG: Adaptive Agentic Graph Retrieval for Cost-Aware and Reliable Reasoning
Jan 29, 2026Graph Retrieval-Augmented Generation (Graph-RAG) enhances multihop question answering by organizing corpora into knowledge graphs and routing evidence through relational structure. However, practical deployments face two persistent bottlenecks: (i) mixed-difficulty workloads where one-size-fits-all retrieval either wastes cost on easy queries or fails on hard multihop cases, and (ii) extraction loss, where graph abstraction omits fine-grained qualifiers that remain only in source text. We present A2RAG, an adaptive-and-agentic GraphRAG framework for cost-aware and reliable reasoning. A2RAG couples an adaptive controller that verifies evidence sufficiency and triggers targeted refinement only when necessary, with an agentic retriever that progressively escalates retrieval effort and maps graph signals back to provenance text to remain robust under extraction loss and incomplete graphs. Experiments on HotpotQA and 2WikiMultiHopQA demonstrate that A2RAG achieves +9.9/+11.8 absolute gains in Recall@2, while cutting token consumption and end-to-end latency by about 50% relative to iterative multihop baselines.
End to End Autoencoder MLP Framework for Sepsis Prediction
Aug 26, 2025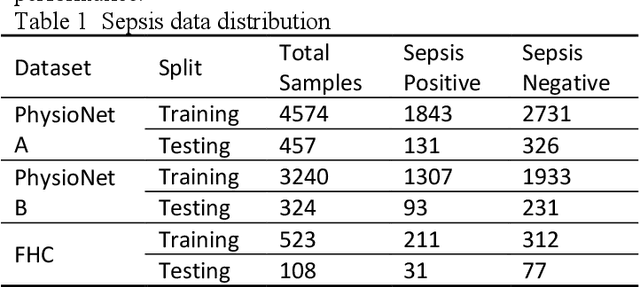
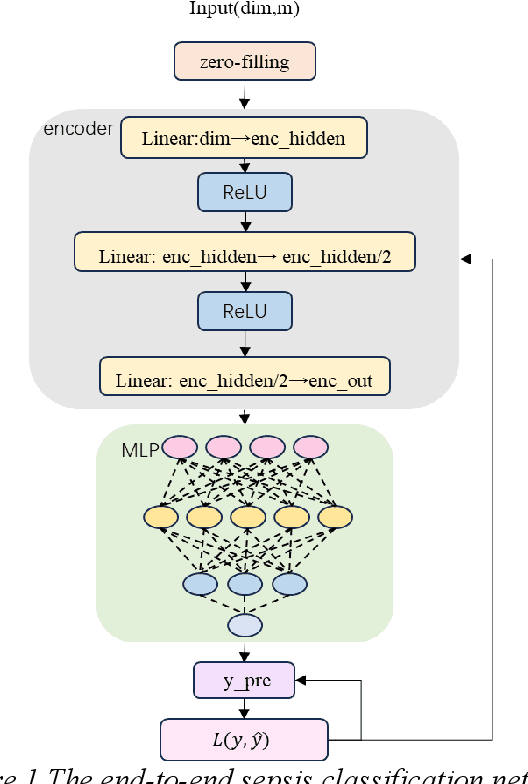
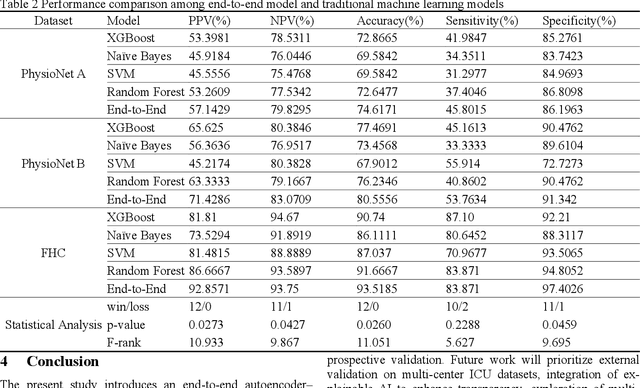
Sepsis is a life threatening condition that requires timely detection in intensive care settings. Traditional machine learning approaches, including Naive Bayes, Support Vector Machine (SVM), Random Forest, and XGBoost, often rely on manual feature engineering and struggle with irregular, incomplete time-series data commonly present in electronic health records. We introduce an end-to-end deep learning framework integrating an unsupervised autoencoder for automatic feature extraction with a multilayer perceptron classifier for binary sepsis risk prediction. To enhance clinical applicability, we implement a customized down sampling strategy that extracts high information density segments during training and a non-overlapping dynamic sliding window mechanism for real-time inference. Preprocessed time series data are represented as fixed dimension vectors with explicit missingness indicators, mitigating bias and noise. We validate our approach on three ICU cohorts. Our end-to-end model achieves accuracies of 74.6 percent, 80.6 percent, and 93.5 percent, respectively, consistently outperforming traditional machine learning baselines. These results demonstrate the framework's superior robustness, generalizability, and clinical utility for early sepsis detection across heterogeneous ICU environments.
Identification of Probabilities of Causation: A Complete Characterization
May 21, 2025Probabilities of causation are fundamental to modern decision-making. Pearl first introduced three binary probabilities of causation, and Tian and Pearl later derived tight bounds for them using Balke's linear programming. The theoretical characterization of probabilities of causation with multi-valued treatments and outcomes has remained unresolved for decades, limiting the scope of causality-based decision-making. In this paper, we resolve this foundational gap by proposing a complete set of representative probabilities of causation and proving that they are sufficient to characterize all possible probabilities of causation within the framework of Structural Causal Models (SCMs). We then formally derive tight bounds for these representative quantities using formal mathematical proofs. Finally, we demonstrate the practical relevance of our results through illustrative toy examples.
Enhancing Graph Neural Networks in Large-scale Traffic Incident Analysis with Concurrency Hypothesis
Nov 04, 2024Despite recent progress in reducing road fatalities, the persistently high rate of traffic-related deaths highlights the necessity for improved safety interventions. Leveraging large-scale graph-based nationwide road network data across 49 states in the USA, our study first posits the Concurrency Hypothesis from intuitive observations, suggesting a significant likelihood of incidents occurring at neighboring nodes within the road network. To quantify this phenomenon, we introduce two novel metrics, Average Neighbor Crash Density (ANCD) and Average Neighbor Crash Continuity (ANCC), and subsequently employ them in statistical tests to validate the hypothesis rigorously. Building upon this foundation, we propose the Concurrency Prior (CP) method, a powerful approach designed to enhance the predictive capabilities of general Graph Neural Network (GNN) models in semi-supervised traffic incident prediction tasks. Our method allows GNNs to incorporate concurrent incident information, as mentioned in the hypothesis, via tokenization with negligible extra parameters. The extensive experiments, utilizing real-world data across states and cities in the USA, demonstrate that integrating CP into 12 state-of-the-art GNN architectures leads to significant improvements, with gains ranging from 3% to 13% in F1 score and 1.3% to 9% in AUC metrics. The code is publicly available at https://github.com/xiwenc1/Incident-GNN-CP.
Predicting total time to compress a video corpus using online inference systems
Oct 23, 2024Predicting the computational cost of compressing/transcoding clips in a video corpus is important for resource management of cloud services and VOD (Video On Demand) providers. Currently, customers of cloud video services are unaware of the cost of transcoding their files until the task is completed. Previous work concentrated on predicting perclip compression time, and thus estimating the cost of video compression. In this work, we propose new Machine Learning (ML) systems which predict cost for the entire corpus instead. This is a more appropriate goal since users are not interested in per-clip cost but instead the cost for the whole corpus. In this work, we evaluate our systems with respect to two video codecs (x264, x265) and a novel high-quality video corpus. We find that the accuracy of aggregate time prediction for a video corpus more than two times better than using per-clip predictions. Furthermore, we present an online inference framework in which we update the ML models as files are processed. A consideration of video compute overhead and appropriate choice of ML predictor for each fraction of corpus completed yields a prediction error of less than 5%. This is approximately two times better than previous work which proposed generalised predictors.
Occlusion-Aware Detection and Re-ID Calibrated Network for Multi-Object Tracking
Aug 30, 2023Multi-Object Tracking (MOT) is a crucial computer vision task that aims to predict the bounding boxes and identities of objects simultaneously. While state-of-the-art methods have made remarkable progress by jointly optimizing the multi-task problems of detection and Re-ID feature learning, yet, few approaches explore to tackle the occlusion issue, which is a long-standing challenge in the MOT field. Generally, occluded objects may hinder the detector from estimating the bounding boxes, resulting in fragmented trajectories. And the learned occluded Re-ID embeddings are less distinct since they contain interferer. To this end, we propose an occlusion-aware detection and Re-ID calibrated network for multi-object tracking, termed as ORCTrack. Specifically, we propose an Occlusion-Aware Attention (OAA) module in the detector that highlights the object features while suppressing the occluded background regions. OAA can serve as a modulator that enhances the detector for some potentially occluded objects. Furthermore, we design a Re-ID embedding matching block based on the optimal transport problem, which focuses on enhancing and calibrating the Re-ID representations through different adjacent frames complementarily. To validate the effectiveness of the proposed method, extensive experiments are conducted on two challenging VisDrone2021-MOT and KITTI benchmarks. Experimental evaluations demonstrate the superiority of our approach, which can achieve new state-of-the-art performance and enjoy high run-time efficiency.
High-performance real-world optical computing trained by in situ model-free optimization
Jul 22, 2023



Optical computing systems can provide high-speed and low-energy data processing but face deficiencies in computationally demanding training and simulation-to-reality gap. We propose a model-free solution for lightweight in situ optimization of optical computing systems based on the score gradient estimation algorithm. This approach treats the system as a black box and back-propagates loss directly to the optical weights' probabilistic distributions, hence circumventing the need for computation-heavy and biased system simulation. We demonstrate a superior classification accuracy on the MNIST and FMNIST datasets through experiments on a single-layer diffractive optical computing system. Furthermore, we show its potential for image-free and high-speed cell analysis. The inherent simplicity of our proposed method, combined with its low demand for computational resources, expedites the transition of optical computing from laboratory demonstrations to real-world applications.
Filling the gaps in video transcoder deployment in the cloud
Apr 17, 2023



Cloud-based deployment of content production and broadcast workflows has continued to disrupt the industry after the pandemic. The key tools required for unlocking cloud workflows, e.g., transcoding, metadata parsing, and streaming playback, are increasingly commoditized. However, as video traffic continues to increase there is a need to consider tools which offer opportunities for further bitrate/quality gains as well as those which facilitate cloud deployment. In this paper we consider preprocessing, rate/distortion optimisation and cloud cost prediction tools which are only just emerging from the research community. These tools are posed as part of the per-clip optimisation approach to transcoding which has been adopted by large streaming media processing entities but has yet to be made more widely available for the industry.