 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Video MLLMs with Attribute-Structured and Quality-Verified Instructions
Feb 13, 2026Universal video understanding requires modeling fine-grained visual and audio information over time in diverse real-world scenarios. However, the performance of existing models is primarily constrained by video-instruction data that represents complex audiovisual content as single, incomplete descriptions, lacking fine-grained organization and reliable annotation. To address this, we introduce: (i) ASID-1M, an open-source collection of one million structured, fine-grained audiovisual instruction annotations with single- and multi-attribute supervision; (ii) ASID-Verify, a scalable data curation pipeline for annotation, with automatic verification and refinement that enforces semantic and temporal consistency between descriptions and the corresponding audiovisual content; and (iii) ASID-Captioner, a video understanding model trained via Supervised Fine-Tuning (SFT) on the ASID-1M. Experiments across seven benchmarks covering audiovisual captioning, attribute-wise captioning, caption-based QA, and caption-based temporal grounding show that ASID-Captioner improves fine-grained caption quality while reducing hallucinations and improving instruction following. It achieves state-of-the-art performance among open-source models and is competitive with Gemini-3-Pro.
Cross-modal supervised learning for better acoustic representations
Jan 01, 2020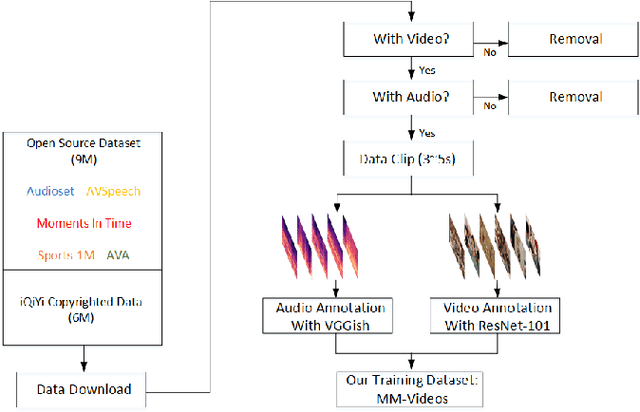
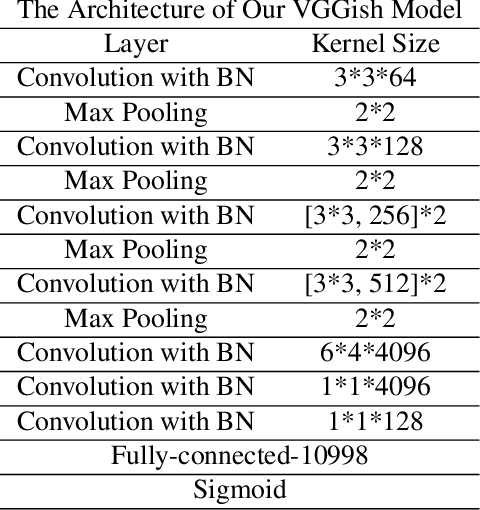
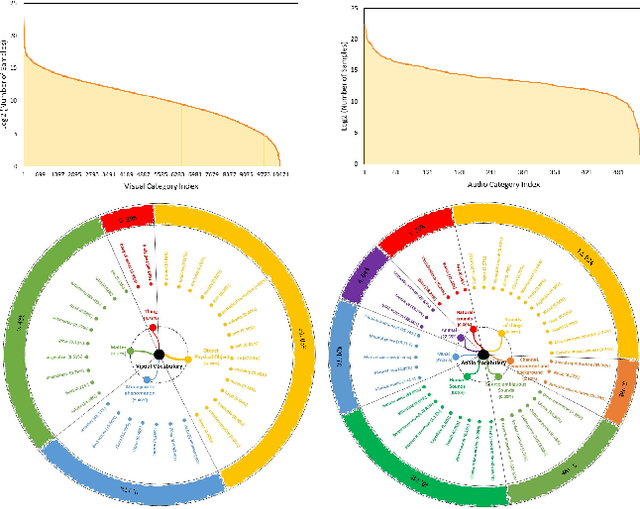
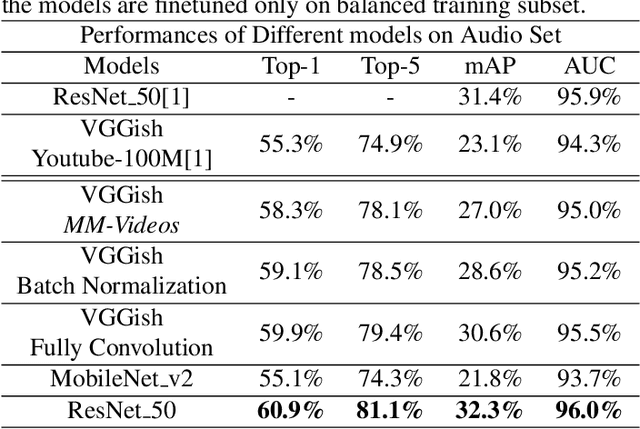
Obtaining large-scale human-labeled datasets to train acoustic representation models is a very challenging task. On the contrary, we can easily collect data with machine-generated labels. In this work, we propose to exploit machine-generated labels to learn better acoustic representations, based on the synchronization between vision and audio. Firstly, we collect a large-scale video dataset with 15 million samples, which totally last 16,320 hours. Each video is 3 to 5 seconds in length and annotated automatically by publicly available visual and audio classification models. Secondly, we train various classical convolutional neural networks (CNNs) including VGGish, ResNet 50 and Mobilenet v2. We also make several improvements to VGGish and achieve better results. Finally, we transfer our models on three external standard benchmarks for audio classification task, and achieve significant performance boost over the state-of-the-art results. Models and codes are available at: https://github.com/Deeperjia/vgg-like-audio-models.