 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Conversational Search for Online Shopping with Utterance Transfer
Sep 12, 2021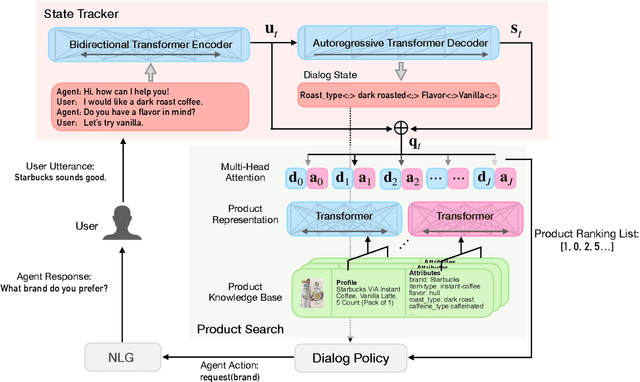
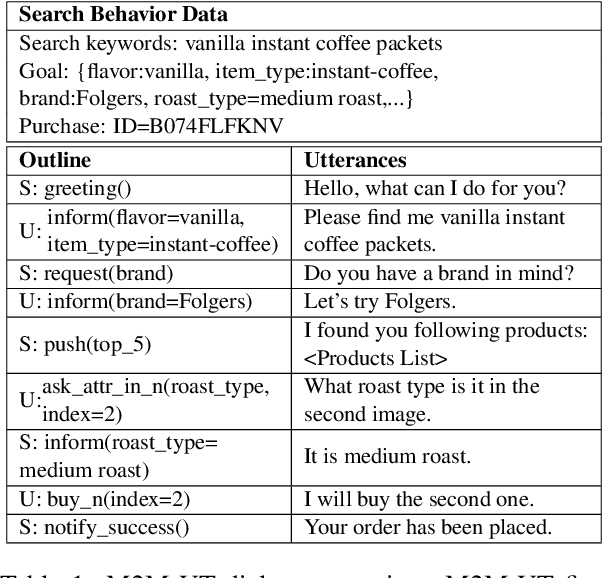
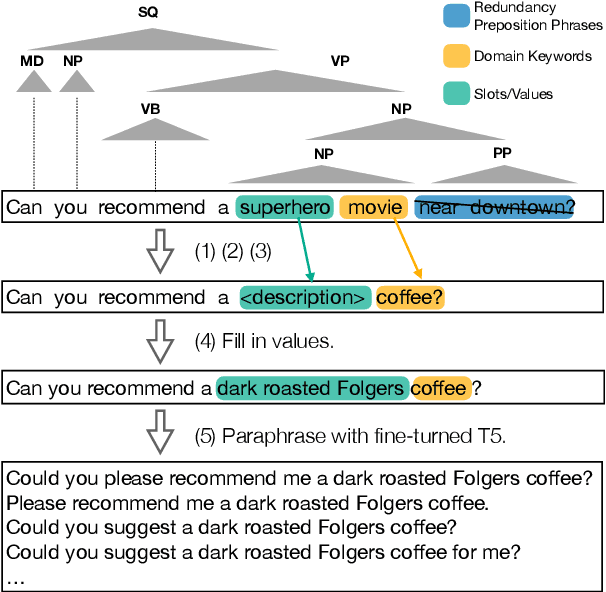

Successful conversational search systems can present natural, adaptive and interactive shopping experience for online shopping customers. However, building such systems from scratch faces real word challenges from both imperfect product schema/knowledge and lack of training dialog data.In this work we first propose ConvSearch, an end-to-end conversational search system that deeply combines the dialog system with search. It leverages the text profile to retrieve products, which is more robust against imperfect product schema/knowledge compared with using product attributes alone. We then address the lack of data challenges by proposing an utterance transfer approach that generates dialogue utterances by using existing dialog from other domains, and leveraging the search behavior data from e-commerce retailer. With utterance transfer, we introduce a new conversational search dataset for online shopping. Experiments show that our utterance transfer method can significantly improve the availability of training dialogue data without crowd-sourcing, and the conversational search system significantly outperformed the best tested baseline.
PAM: Understanding Product Images in Cross Product Category Attribute Extraction
Jun 08, 2021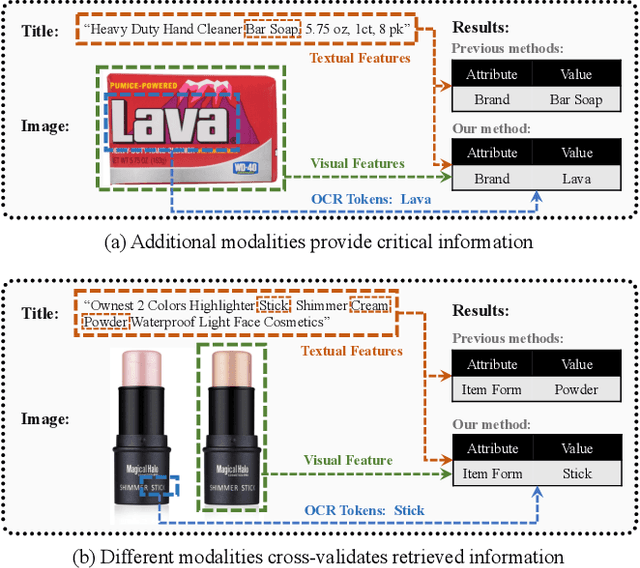
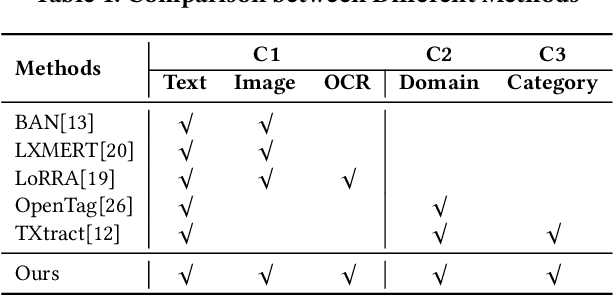

Understanding product attributes plays an important role in improving online shopping experience for customers and serves as an integral part for constructing a product knowledge graph. Most existing methods focus on attribute extraction from text description or utilize visual information from product images such as shape and color. Compared to the inputs considered in prior works, a product image in fact contains more information, represented by a rich mixture of words and visual clues with a layout carefully designed to impress customers. This work proposes a more inclusive framework that fully utilizes these different modalities for attribute extraction. Inspired by recent works in visual question answering, we use a transformer based sequence to sequence model to fuse representations of product text, Optical Character Recognition (OCR) tokens and visual objects detected in the product image. The framework is further extended with the capability to extract attribute value across multiple product categories with a single model, by training the decoder to predict both product category and attribute value and conditioning its output on product category. The model provides a unified attribute extraction solution desirable at an e-commerce platform that offers numerous product categories with a diverse body of product attributes. We evaluated the model on two product attributes, one with many possible values and one with a small set of possible values, over 14 product categories and found the model could achieve 15% gain on the Recall and 10% gain on the F1 score compared to existing methods using text-only features.
AdaTag: Multi-Attribute Value Extraction from Product Profiles with Adaptive Decoding
Jun 04, 2021

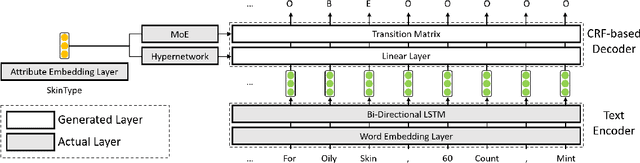
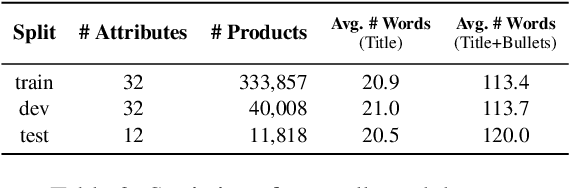
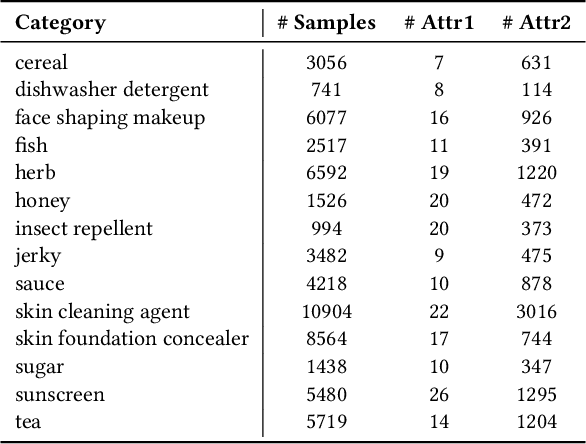
Automatic extraction of product attribute values is an important enabling technology in e-Commerce platforms. This task is usually modeled using sequence labeling architectures, with several extensions to handle multi-attribute extraction. One line of previous work constructs attribute-specific models, through separate decoders or entirely separate models. However, this approach constrains knowledge sharing across different attributes. Other contributions use a single multi-attribute model, with different techniques to embed attribute information. But sharing the entire network parameters across all attributes can limit the model's capacity to capture attribute-specific characteristics. In this paper we present AdaTag, which uses adaptive decoding to handle extraction. We parameterize the decoder with pretrained attribute embeddings, through a hypernetwork and a Mixture-of-Experts (MoE) module. This allows for separate, but semantically correlated, decoders to be generated on the fly for different attributes. This approach facilitates knowledge sharing, while maintaining the specificity of each attribute. Our experiments on a real-world e-Commerce dataset show marked improvements over previous methods.
CoRI: Collective Relation Integration with Data Augmentation for Open Information Extraction
Jun 01, 2021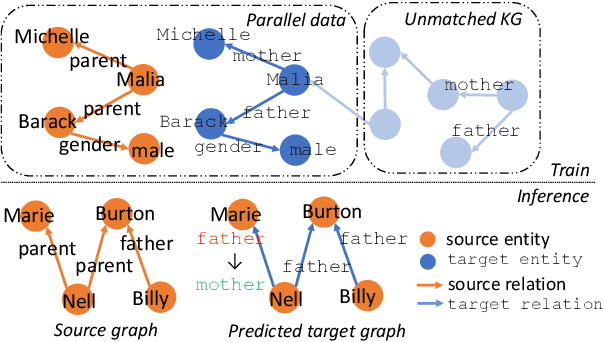
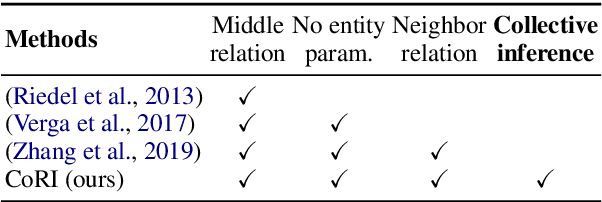
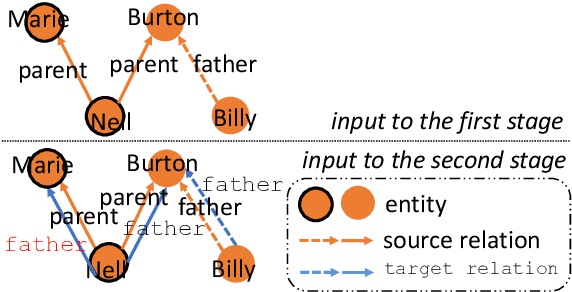
Integrating extracted knowledge from the Web to knowledge graphs (KGs) can facilitate tasks like question answering. We study relation integration that aims to align free-text relations in subject-relation-object extractions to relations in a target KG. To address the challenge that free-text relations are ambiguous, previous methods exploit neighbor entities and relations for additional context. However, the predictions are made independently, which can be mutually inconsistent. We propose a two-stage Collective Relation Integration (CoRI) model, where the first stage independently makes candidate predictions, and the second stage employs a collective model that accesses all candidate predictions to make globally coherent predictions. We further improve the collective model with augmented data from the portion of the target KG that is otherwise unused. Experiment results on two datasets show that CoRI can significantly outperform the baselines, improving AUC from .677 to .748 and from .716 to .780, respectively.
TCN: Table Convolutional Network for Web Table Interpretation
Feb 17, 2021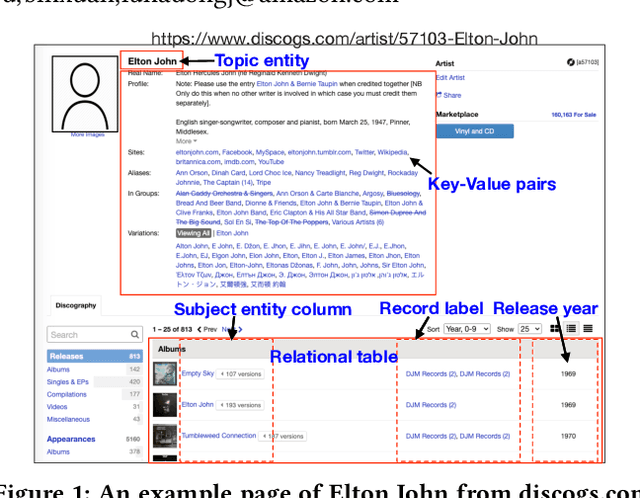
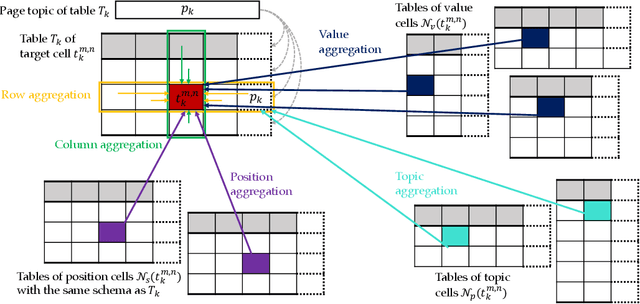
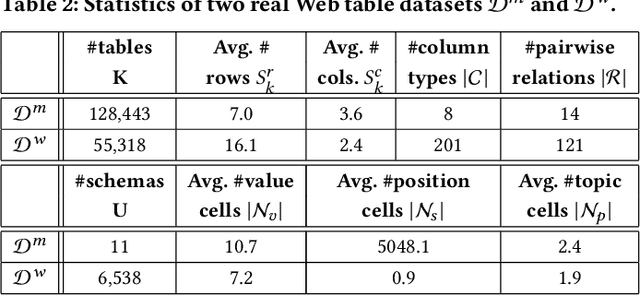
Information extraction from semi-structured webpages provides valuable long-tailed facts for augmenting knowledge graph. Relational Web tables are a critical component containing additional entities and attributes of rich and diverse knowledge. However, extracting knowledge from relational tables is challenging because of sparse contextual information. Existing work linearize table cells and heavily rely on modifying deep language models such as BERT which only captures related cells information in the same table. In this work, we propose a novel relational table representation learning approach considering both the intra- and inter-table contextual information. On one hand, the proposed Table Convolutional Network model employs the attention mechanism to adaptively focus on the most informative intra-table cells of the same row or column; and, on the other hand, it aggregates inter-table contextual information from various types of implicit connections between cells across different tables. Specifically, we propose three novel aggregation modules for (i) cells of the same value, (ii) cells of the same schema position, and (iii) cells linked to the same page topic. We further devise a supervised multi-task training objective for jointly predicting column type and pairwise column relation, as well as a table cell recovery objective for pre-training. Experiments on real Web table datasets demonstrate our method can outperform competitive baselines by +4.8% of F1 for column type prediction and by +4.1% of F1 for pairwise column relation prediction.
J-Recs: Principled and Scalable Recommendation Justification
Nov 11, 2020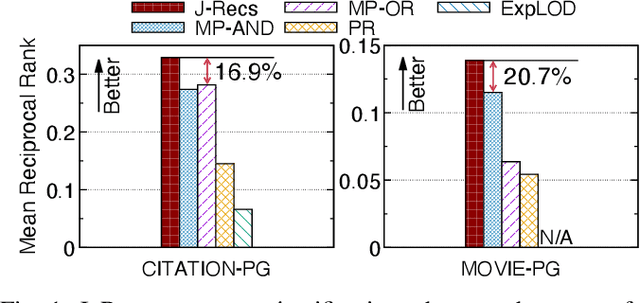
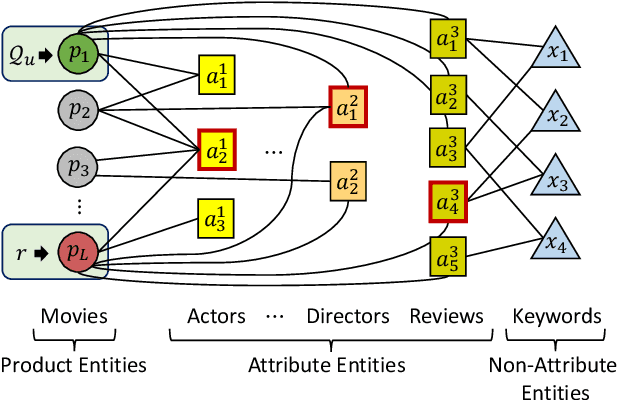

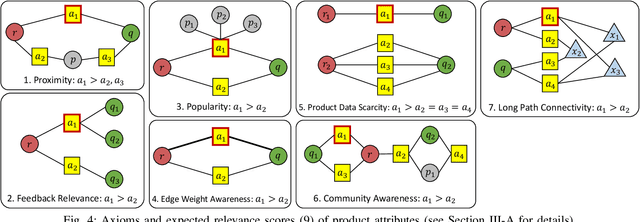
Online recommendation is an essential functionality across a variety of services, including e-commerce and video streaming, where items to buy, watch, or read are suggested to users. Justifying recommendations, i.e., explaining why a user might like the recommended item, has been shown to improve user satisfaction and persuasiveness of the recommendation. In this paper, we develop a method for generating post-hoc justifications that can be applied to the output of any recommendation algorithm. Existing post-hoc methods are often limited in providing diverse justifications, as they either use only one of many available types of input data, or rely on the predefined templates. We address these limitations of earlier approaches by developing J-Recs, a method for producing concise and diverse justifications. J-Recs is a recommendation model-agnostic method that generates diverse justifications based on various types of product and user data (e.g., purchase history and product attributes). The challenge of jointly processing multiple types of data is addressed by designing a principled graph-based approach for justification generation. In addition to theoretical analysis, we present an extensive evaluation on synthetic and real-world data. Our results show that J-Recs satisfies desirable properties of justifications, and efficiently produces effective justifications, matching user preferences up to 20% more accurately than baselines.
CorDEL: A Contrastive Deep Learning Approach for Entity Linkage
Sep 15, 2020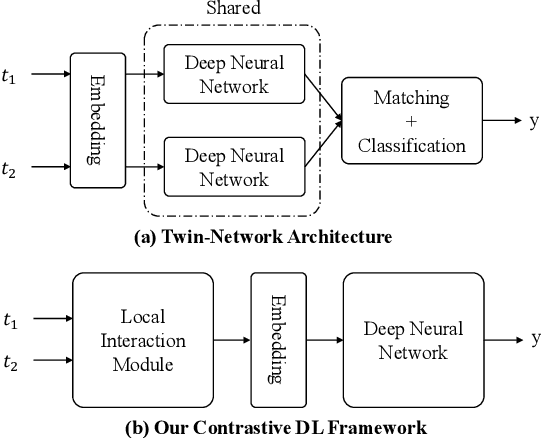
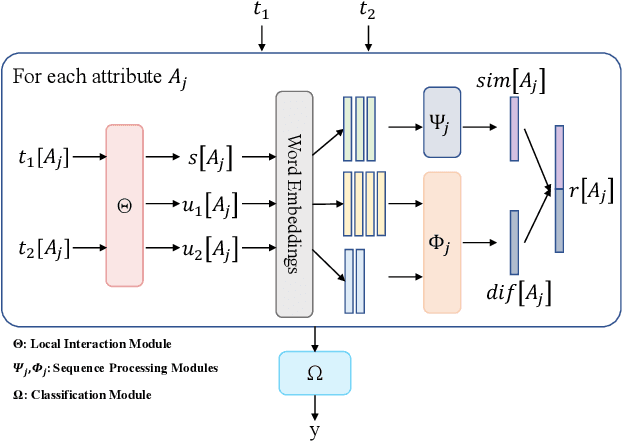
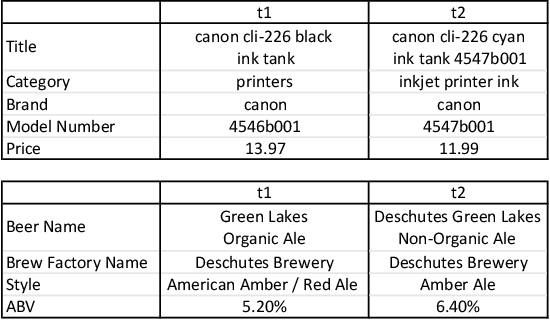
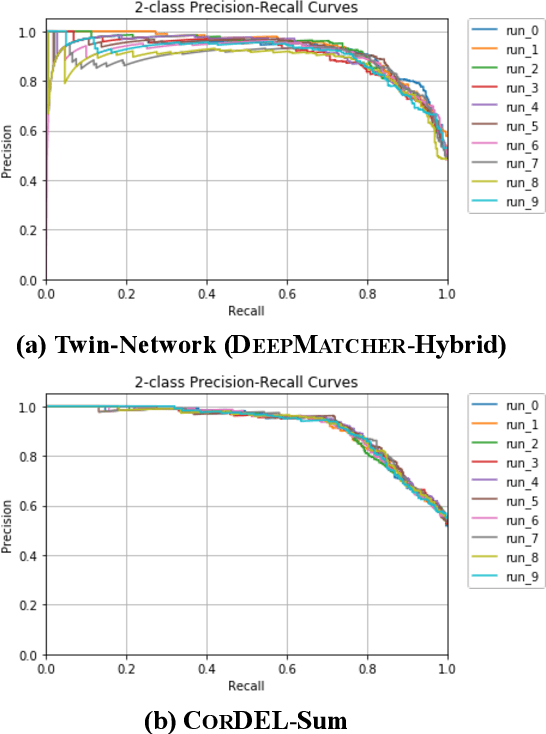
Entity linkage (EL) is a critical problem in data cleaning and integration. In the past several decades, EL has typically been done by rule-based systems or traditional machine learning models with hand-curated features, both of which heavily depend on manual human inputs. With the ever-increasing growth of new data, deep learning (DL) based approaches have been proposed to alleviate the high cost of EL associated with the traditional models. Existing exploration of DL models for EL strictly follows the well-known twin-network architecture. However, we argue that the twin-network architecture is sub-optimal to EL, leading to inherent drawbacks of existing models. In order to address the drawbacks, we propose a novel and generic contrastive DL framework for EL. The proposed framework is able to capture both syntactic and semantic matching signals and pays attention to subtle but critical differences. Based on the framework, we develop a contrastive DL approach for EL, called CorDEL, with three powerful variants. We evaluate CorDEL with extensive experiments conducted on both public benchmark datasets and a real-world dataset. CorDEL outperforms previous state-of-the-art models by 5.2% on public benchmark datasets. Moreover, CorDEL yields a 2.4% improvement over the current best DL model on the real-world dataset, while reducing the number of training parameters by 97.6%.
AutoKnow: Self-Driving Knowledge Collection for Products of Thousands of Types
Jun 24, 2020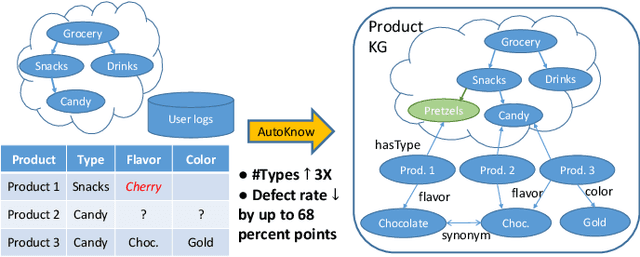

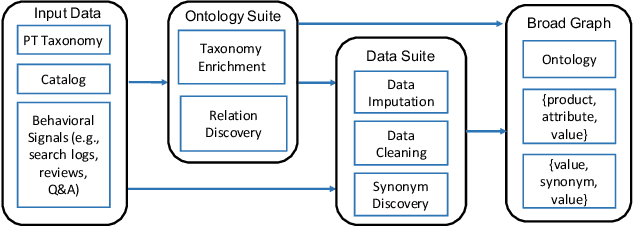
Can one build a knowledge graph (KG) for all products in the world? Knowledge graphs have firmly established themselves as valuable sources of information for search and question answering, and it is natural to wonder if a KG can contain information about products offered at online retail sites. There have been several successful examples of generic KGs, but organizing information about products poses many additional challenges, including sparsity and noise of structured data for products, complexity of the domain with millions of product types and thousands of attributes, heterogeneity across large number of categories, as well as large and constantly growing number of products. We describe AutoKnow, our automatic (self-driving) system that addresses these challenges. The system includes a suite of novel techniques for taxonomy construction, product property identification, knowledge extraction, anomaly detection, and synonym discovery. AutoKnow is (a) automatic, requiring little human intervention, (b) multi-scalable, scalable in multiple dimensions (many domains, many products, and many attributes), and (c) integrative, exploiting rich customer behavior logs. AutoKnow has been operational in collecting product knowledge for over 11K product types.
Automatic Validation of Textual Attribute Values in E-commerce Catalog by Learning with Limited Labeled Data
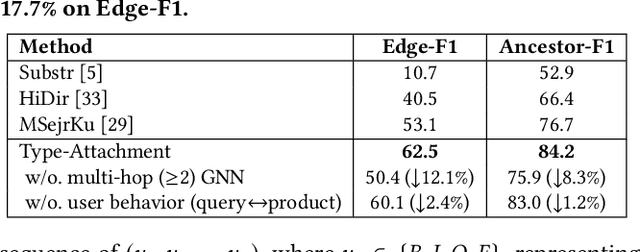
Jun 23, 2020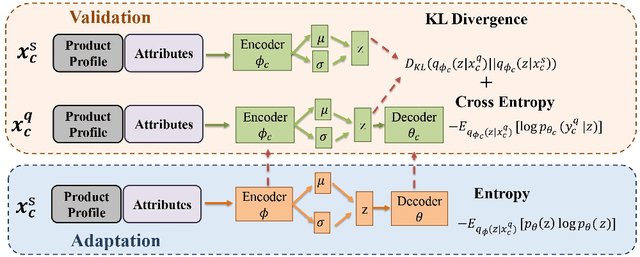

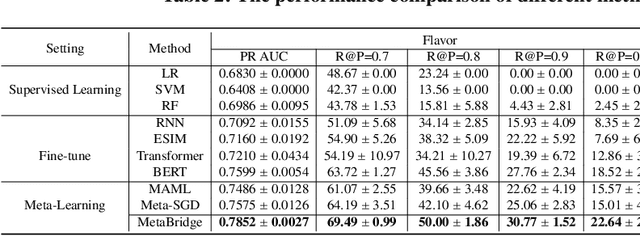
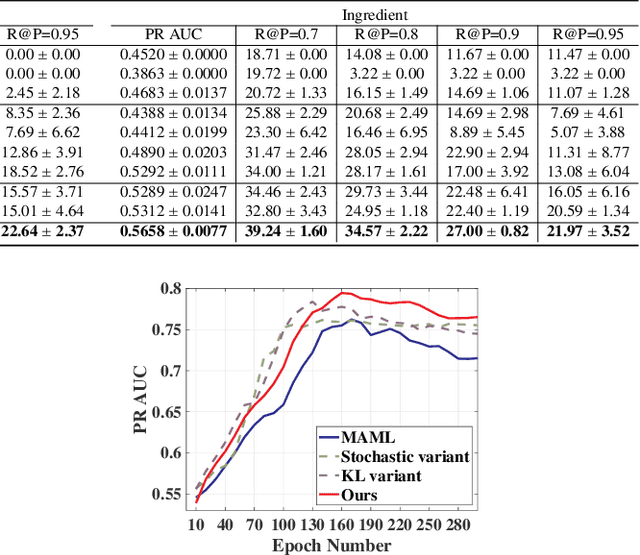
Product catalogs are valuable resources for eCommerce website. In the catalog, a product is associated with multiple attributes whose values are short texts, such as product name, brand, functionality and flavor. Usually individual retailers self-report these key values, and thus the catalog information unavoidably contains noisy facts. Although existing deep neural network models have shown success in conducting cross-checking between two pieces of texts, their success has to be dependent upon a large set of quality labeled data, which are hard to obtain in this validation task: products span a variety of categories. To address the aforementioned challenges, we propose a novel meta-learning latent variable approach, called MetaBridge, which can learn transferable knowledge from a subset of categories with limited labeled data and capture the uncertainty of never-seen categories with unlabeled data. More specifically, we make the following contributions. (1) We formalize the problem of validating the textual attribute values of products from a variety of categories as a natural language inference task in the few-shot learning setting, and propose a meta-learning latent variable model to jointly process the signals obtained from product profiles and textual attribute values. (2) We propose to integrate meta learning and latent variable in a unified model to effectively capture the uncertainty of various categories. (3) We propose a novel objective function based on latent variable model in the few-shot learning setting, which ensures distribution consistency between unlabeled and labeled data and prevents overfitting by sampling from the learned distribution. Extensive experiments on real eCommerce datasets from hundreds of categories demonstrate the effectiveness of MetaBridge on textual attribute validation and its outstanding performance compared with state-of-the-art approaches.
MultiImport: Inferring Node Importance in a Knowledge Graph from Multiple Input Signals
Jun 22, 2020



Given multiple input signals, how can we infer node importance in a knowledge graph (KG)? Node importance estimation is a crucial and challenging task that can benefit a lot of applications including recommendation, search, and query disambiguation. A key challenge towards this goal is how to effectively use input from different sources. On the one hand, a KG is a rich source of information, with multiple types of nodes and edges. On the other hand, there are external input signals, such as the number of votes or pageviews, which can directly tell us about the importance of entities in a KG. While several methods have been developed to tackle this problem, their use of these external signals has been limited as they are not designed to consider multiple signals simultaneously. In this paper, we develop an end-to-end model MultiImport, which infers latent node importance from multiple, potentially overlapping, input signals. MultiImport is a latent variable model that captures the relation between node importance and input signals, and effectively learns from multiple signals with potential conflicts. Also, MultiImport provides an effective estimator based on attentive graph neural networks. We ran experiments on real-world KGs to show that MultiImport handles several challenges involved with inferring node importance from multiple input signals, and consistently outperforms existing methods, achieving up to 23.7% higher NDCG@100 than the state-of-the-art method.