 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoBlock: A Hands-off Blocking Framework for Entity Matching
Paper and Code

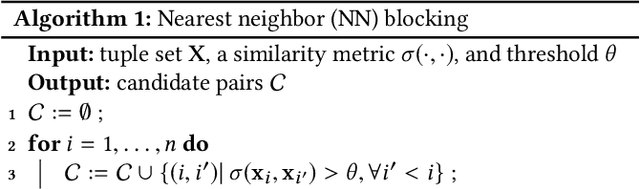
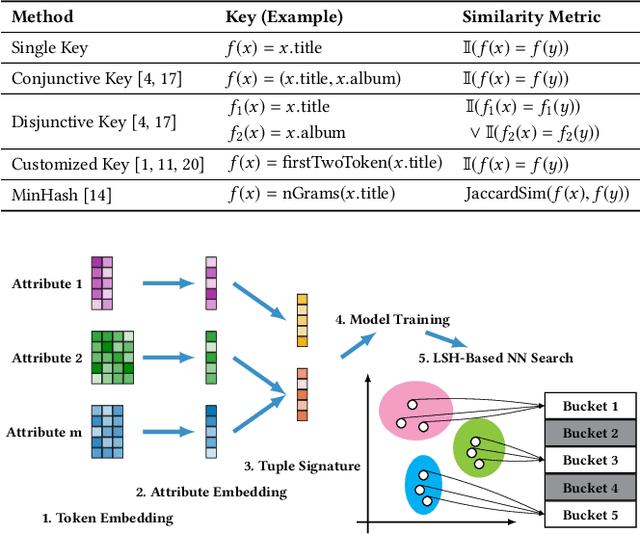

Entity matching seeks to identify data records over one or multiple data sources that refer to the same real-world entity. Virtually every entity matching task on large datasets requires blocking, a step that reduces the number of record pairs to be matched. However, most of the traditional blocking methods are learning-free and key-based, and their successes are largely built on laborious human effort in cleaning data and designing blocking keys. In this paper, we propose AutoBlock, a novel hands-off blocking framework for entity matching, based on similarity-preserving representation learning and nearest neighbor search. Our contributions include: (a) Automation: AutoBlock frees users from laborious data cleaning and blocking key tuning. (b) Scalability: AutoBlock has a sub-quadratic total time complexity and can be easily deployed for millions of records. (c) Effectiveness: AutoBlock outperforms a wide range of competitive baselines on multiple large-scale, real-world datasets, especially when datasets are dirty and/or unstructured.