 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMbench: A Compositional Benchmark for Vision-and-Language Manipulation
Jun 17, 2022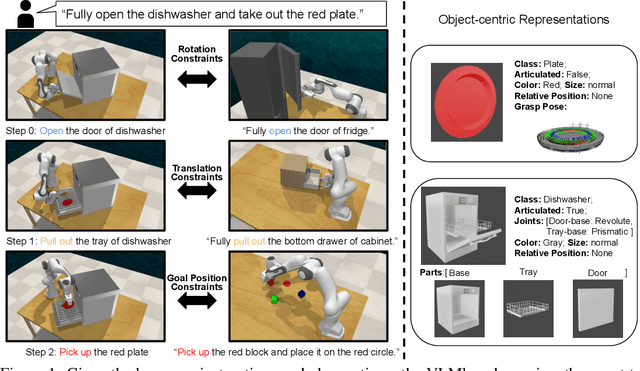

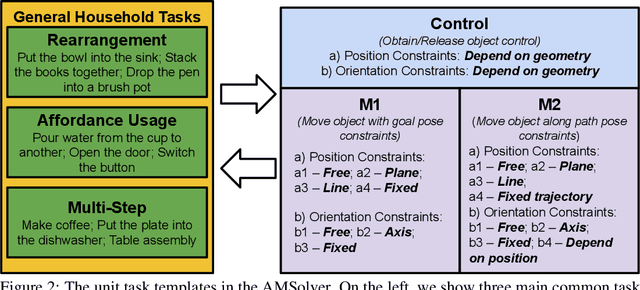
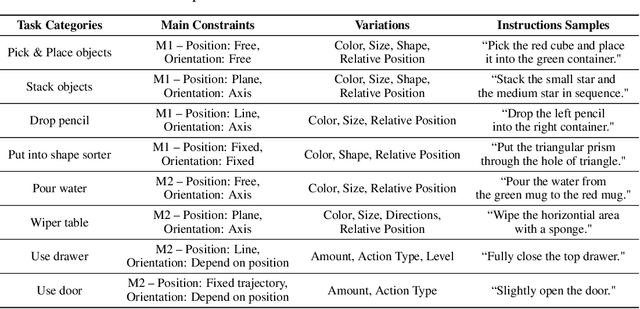
Benefiting from language flexibility and compositionality, humans naturally intend to use language to command an embodied agent for complex tasks such as navigation and object manipulation. In this work, we aim to fill the blank of the last mile of embodied agents -- object manipulation by following human guidance, e.g., "move the red mug next to the box while keeping it upright." To this end, we introduce an Automatic Manipulation Solver (AMSolver) simulator and build a Vision-and-Language Manipulation benchmark (VLMbench) based on it, containing various language instructions on categorized robotic manipulation tasks. Specifically, modular rule-based task templates are created to automatically generate robot demonstrations with language instructions, consisting of diverse object shapes and appearances, action types, and motion constraints. We also develop a keypoint-based model 6D-CLIPort to deal with multi-view observations and language input and output a sequence of 6 degrees of freedom (DoF) actions. We hope the new simulator and benchmark will facilitate future research on language-guided robotic manipulation.
ClearPose: Large-scale Transparent Object Dataset and Benchmark
Mar 08, 2022
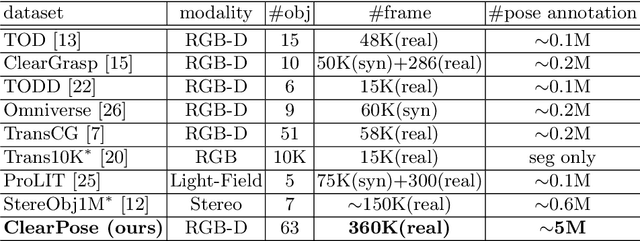

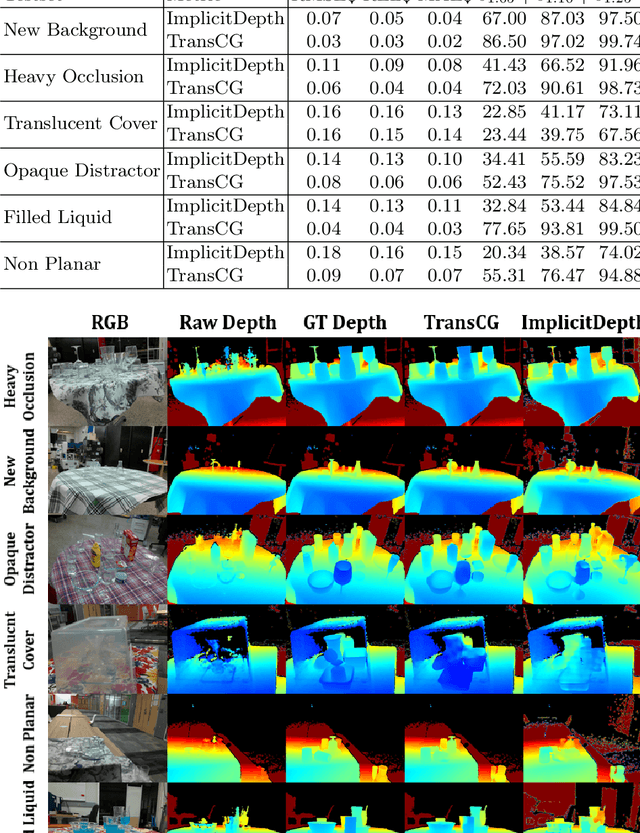
Transparent objects are ubiquitous in household settings and pose distinct challenges for visual sensing and perception systems. The optical properties of transparent objects leave conventional 3D sensors alone unreliable for object depth and pose estimation. These challenges are highlighted by the shortage of large-scale RGB-Depth datasets focusing on transparent objects in real-world settings. In this work, we contribute a large-scale real-world RGB-Depth transparent object dataset named ClearPose to serve as a benchmark dataset for segmentation, scene-level depth completion and object-centric pose estimation tasks. The ClearPose dataset contains over 350K labeled real-world RGB-Depth frames and 4M instance annotations covering 63 household objects. The dataset includes object categories commonly used in daily life under various lighting and occluding conditions as well as challenging test scenarios such as cases of occlusion by opaque or translucent objects, non-planar orientations, presence of liquids, etc. We benchmark several state-of-the-art depth completion and object pose estimation deep neural networks on ClearPose.
ProgressLabeller: Visual Data Stream Annotation for Training Object-Centric 3D Perception
Mar 01, 2022

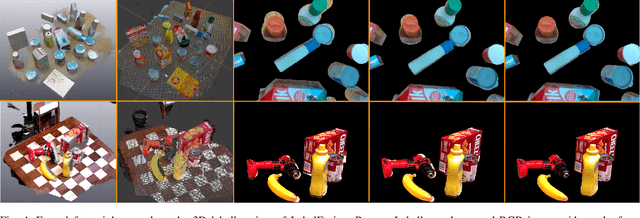
Visual perception tasks often require vast amounts of labelled data, including 3D poses and image space segmentation masks. The process of creating such training data sets can prove difficult or time-intensive to scale up to efficacy for general use. Consider the task of pose estimation for rigid objects. Deep neural network based approaches have shown good performance when trained on large, public datasets. However, adapting these networks for other novel objects, or fine-tuning existing models for different environments, requires significant time investment to generate newly labelled instances. Towards this end, we propose ProgressLabeller as a method for more efficiently generating large amounts of 6D pose training data from color images sequences for custom scenes in a scalable manner. ProgressLabeller is intended to also support transparent or translucent objects, for which the previous methods based on depth dense reconstruction will fail. We demonstrate the effectiveness of ProgressLabeller by rapidly create a dataset of over 1M samples with which we fine-tune a state-of-the-art pose estimation network in order to markedly improve the downstream robotic grasp success rates. ProgressLabeller will be made publicly available soon.
PatchTrack: Multiple Object Tracking Using Frame Patches
Jan 01, 2022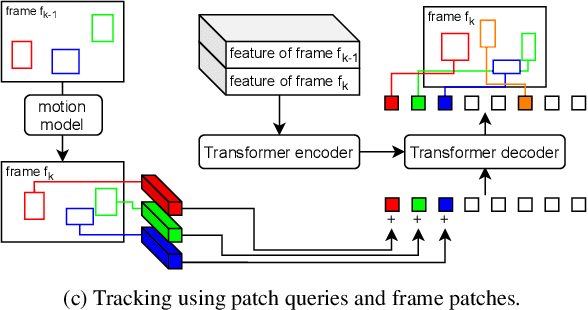
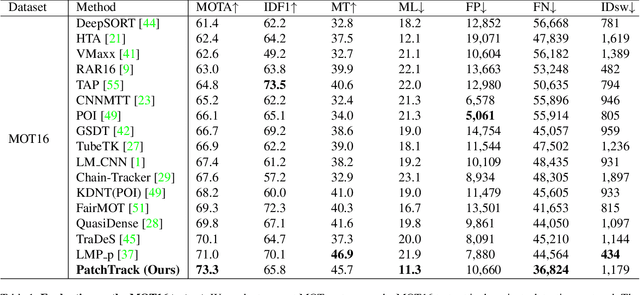
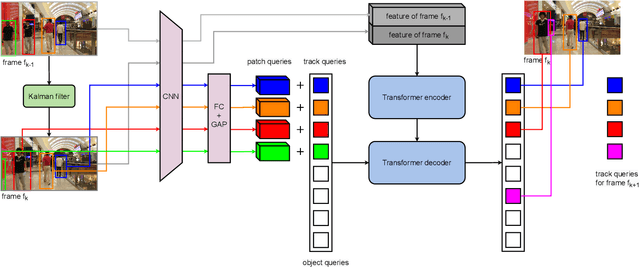
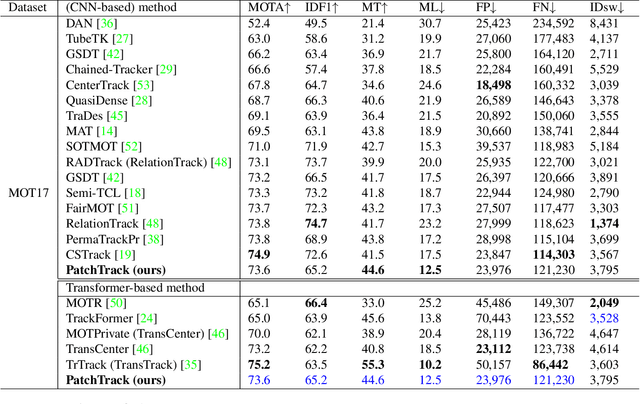
Object motion and object appearance are commonly used information in multiple object tracking (MOT) applications, either for associating detections across frames in tracking-by-detection methods or direct track predictions for joint-detection-and-tracking methods. However, not only are these two types of information often considered separately, but also they do not help optimize the usage of visual information from the current frame of interest directly. In this paper, we present PatchTrack, a Transformer-based joint-detection-and-tracking system that predicts tracks using patches of the current frame of interest. We use the Kalman filter to predict the locations of existing tracks in the current frame from the previous frame. Patches cropped from the predicted bounding boxes are sent to the Transformer decoder to infer new tracks. By utilizing both object motion and object appearance information encoded in patches, the proposed method pays more attention to where new tracks are more likely to occur. We show the effectiveness of PatchTrack on recent MOT benchmarks, including MOT16 (MOTA 73.71%, IDF1 65.77%) and MOT17 (MOTA 73.59%, IDF1 65.23%). The results are published on https://motchallenge.net/method/MOT=4725&chl=10.
Manipulation-Oriented Object Perception in Clutter through Affordance Coordinate Frames
Oct 16, 2020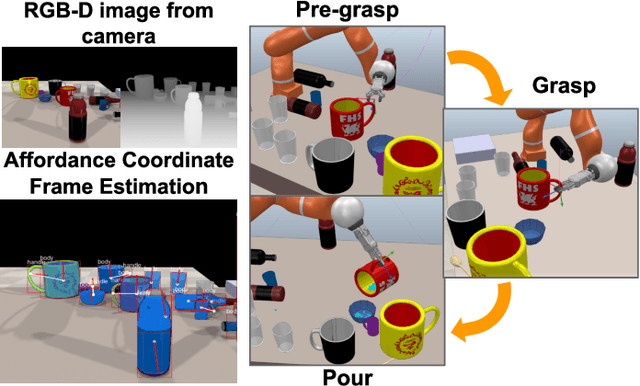
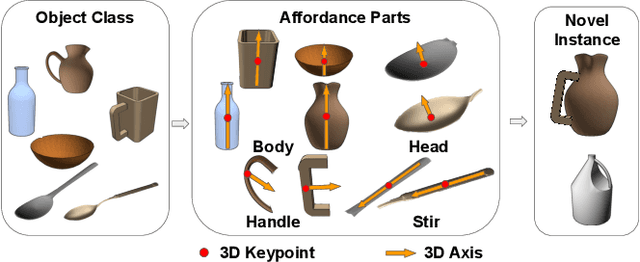
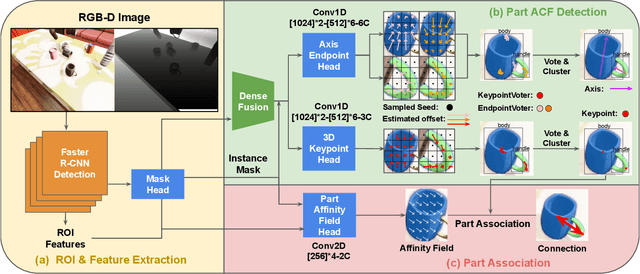
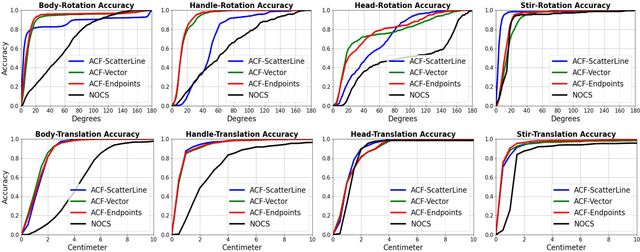
In order to enable robust operation in unstructured environments, robots should be able to generalize manipulation actions to novel object instances. For example, to pour and serve a drink, a robot should be able to recognize novel containers which afford the task. Most importantly, robots should be able to manipulate these novel containers to fulfill the task. To achieve this, we aim to provide robust and generalized perception of object affordances and their associated manipulation poses for reliable manipulation. In this work, we combine the notions of affordance and category-level pose, and introduce the Affordance Coordinate Frame (ACF). With ACF, we represent each object class in terms of individual affordance parts and the compatibility between them, where each part is associated with a part category-level pose for robot manipulation. In our experiments, we demonstrate that ACF outperforms state-of-the-art methods for object detection, as well as category-level pose estimation for object parts. We further demonstrate the applicability of ACF to robot manipulation tasks through experiments in a simulated environment.
Design, Control, and Applications of a Soft Robotic Arm
Jul 08, 2020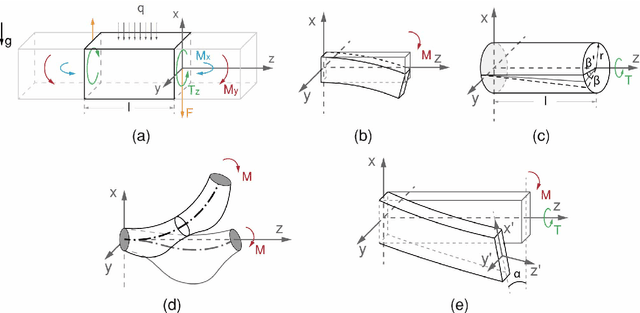
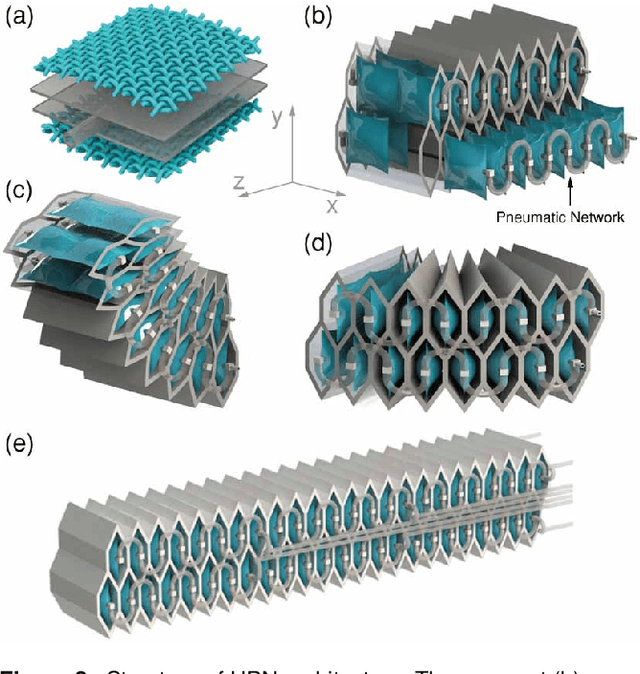

This paper presents the design, control, and applications of a multi-segment soft robotic arm. In order to design a soft arm with large load capacity, several design principles are proposed by analyzing two kinds of buckling issues, under which we present a novel structure named Honeycomb Pneumatic Networks (HPN). Parameter optimization method, based on finite element method (FEM), is proposed to optimize HPN Arm design parameters. Through a quick fabrication process, several prototypes with different performance are made, one of which can achieve the transverse load capacity of 3 kg under 3 bar pressure. Next, considering different internal and external conditions, we develop three controllers according to different model precision. Specifically, based on accurate model, an open-loop controller is realized by combining piece-wise constant curvature (PCC) modeling method and machine learning method. Based on inaccurate model, a feedback controller, using estimated Jacobian, is realized in 3D space. A model-free controller, using reinforcement learning to learn a control policy rather than a model, is realized in 2D plane, with minimal training data. Then, these three control methods are compared on a same experiment platform to explore the applicability of different methods under different conditions. Lastly, we figure out that soft arm can greatly simplify the perception, planning, and control of interaction tasks through its compliance, which is its main advantage over the rigid arm. Through plentiful experiments in three interaction application scenarios, human-robot interaction, free space interaction task, and confined space interaction task, we demonstrate the potential application prospect of the soft arm.
LIT: Light-field Inference of Transparency for Refractive Object Localization
Oct 24, 2019
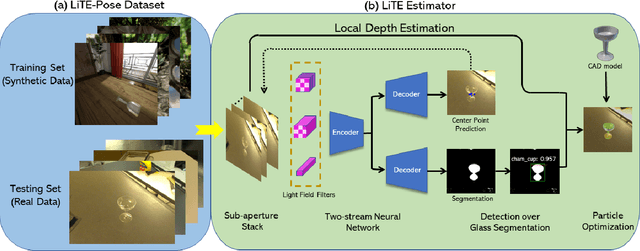
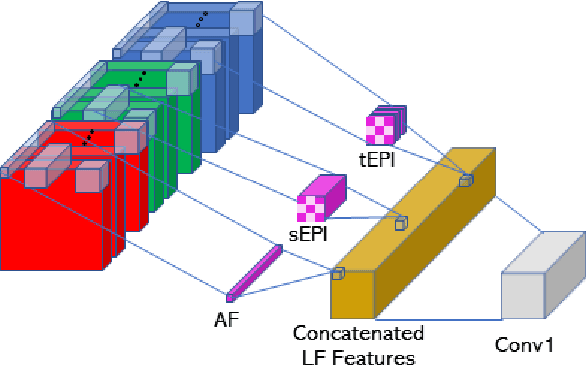

Translucency is prevalent in everyday scenes. As such, perception of transparent objects is essential for robots to perform manipulation. Compared with texture-rich or texture-less Lambertian objects, transparency induces significant uncertainty on object appearance. Ambiguity can be due to changes in lighting, viewpoint, and backgrounds, each of which brings challenges to existing object pose estimation algorithms. In this work, we propose LIT, a two-stage method for transparent object pose estimation using light-field sensing and photorealistic rendering. LIT employs multiple filters specific to light-field imagery in deep networks to capture transparent material properties combined with robust depth and pose estimators based on generative sampling. Along with the LIT algorithm, we introduce the first light-field transparent object dataset for the task of recognition, localization and pose estimation. Using proposed algorithm on our dataset, we show that LIT outperforms both a state-of-the-art end-to-end pose estimation method and a generative pose estimator on transparent objects.
GRIP: Generative Robust Inference and Perception for Semantic Robot Manipulation in Adversarial Environments
Mar 20, 2019
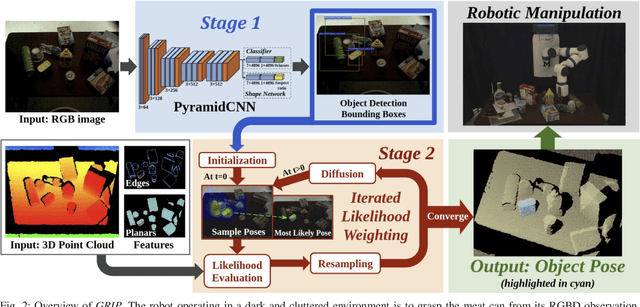
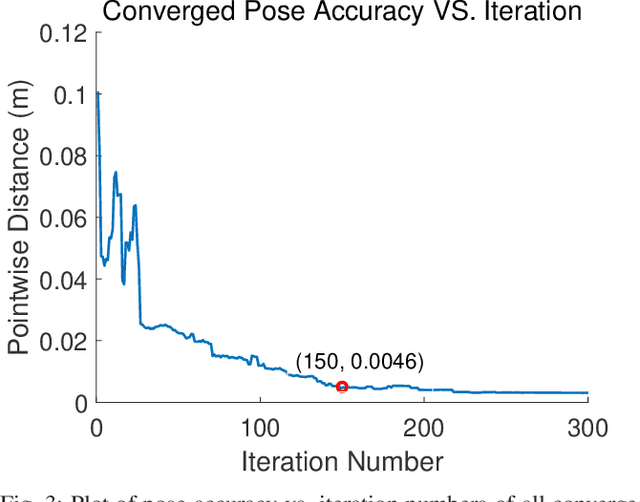

Recent advancements have led to a proliferation of machine learning systems used to assist humans in a wide range of tasks. However, we are still far from accurate, reliable, and resource-efficient operations of these systems. For robot perception, convolutional neural networks (CNNs) for object detection and pose estimation are recently coming into widespread use. However, neural networks are known to suffer overfitting during training process and are less robust within unseen conditions, which are especially vulnerable to {\em adversarial scenarios}. In this work, we propose {\em Generative Robust Inference and Perception (GRIP)} as a two-stage object detection and pose estimation system that aims to combine relative strengths of discriminative CNNs and generative inference methods to achieve robust estimation. Our results show that a second stage of sample-based generative inference is able to recover from false object detection by CNNs, and produce robust estimations in adversarial conditions. We demonstrate the efficacy of {\em GRIP} robustness through comparison with state-of-the-art learning-based pose estimators and pick-and-place manipulation in dark and cluttered environments.