 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWindINR: Latent-State INR for Fast Local Wind Query and Correction in Complex Terrain
May 10, 2026Many downstream decisions in complex terrain require fast wind estimates at a small number of user-specified locations and heights for a given forecast valid time, rather than another dense forecast field on a fixed grid. We present WindINR, a latent-state implicit neural representation framework for continuous high-resolution local wind query and sparse-observation correction. WindINR maps static terrain descriptors, a low-resolution background field, and continuous query coordinates to a high-resolution wind state through a latent-conditioned decoder. To enable rapid inference-time correction, WindINR separates reusable representation learning from sample-specific latent-state correction. During training, a privileged encoder infers a reference latent state from high-resolution supervision, a deployable latent predictor estimates an initial latent state from inference-time inputs alone, and their discrepancies are summarized into a dataset-adaptive Gaussian prior over latent corrections. At inference time, within the WindINR module, network weights remain fixed and only the latent state is updated by minimizing a regularized correction objective using sparse observations and their uncertainty. In controlled OSSEs over the Senja region, including a UAV-aided approach scenario and random-observation robustness tests, WindINR improves local high-resolution wind estimates by updating only a compact latent state rather than the full network. The corrected representation remains continuously queryable at arbitrary coordinates and, in our CPU benchmark, yields about a $2.6\times$ online-correction speedup over full-network fine-tuning, suggesting a practical interface between kilometer-scale background products, sparse local observations, and wind queries in complex terrain.
Think How to Think: Mitigating Overthinking with Autonomous Difficulty Cognition in Large Reasoning Models
Jul 03, 2025Recent Long Reasoning Models(LRMs) have demonstrated remarkable capabilities in handling complex reasoning tasks, but are hindered by excessive overthinking. To explore its essence, our empirical analysis reveals that LRMs are primarily limited to recognizing task properties (i.e., difficulty levels) like humans before solving the problem, leading to a one-size-fits-all reasoning process. Inspired by this, a pressing and natural question emerges: Can we bootstrap such ability to further alleviate the overthinking phenomenon in LRMs? In this paper, we propose Think-How-to-Think (TH2T), a novel two-stage fine-tuning strategy that progressively inspires LRMs' difficulty cognition and redundancy cognition. First, we introduce difficulty-hypnosis in the prefixes of model outputs to intervene in the internal reasoning trajectory. Combined with a heterogeneous short and long reasoning dataset, the trained model enhances its sensitivity to task difficulty, enabling native, differentiated reasoning strategies across various tasks. Second, we further extend redundancy-hypnosis to the internal reasoning process, guiding the model to identify redundant structures within the reasoning steps and generate more concise reasoning outputs. Experiments on 7B/14B/32B models demonstrate that TH2T significantly reduces inference costs (more than 70% on easy tasks and 40% on hard tasks) while maintaining performance stability. The resulting outputs exhibit clear difficulty-aware capabilities and reduced redundancy (e.g., reflection).
Solving Normalized Cut Problem with Constrained Action Space
May 20, 2025



Reinforcement Learning (RL) has emerged as an important paradigm to solve combinatorial optimization problems primarily due to its ability to learn heuristics that can generalize across problem instances. However, integrating external knowledge that will steer combinatorial optimization problem solutions towards domain appropriate outcomes remains an extremely challenging task. In this paper, we propose the first RL solution that uses constrained action spaces to guide the normalized cut problem towards pre-defined template instances. Using transportation networks as an example domain, we create a Wedge and Ring Transformer that results in graph partitions that are shaped in form of Wedges and Rings and which are likely to be closer to natural optimal partitions. However, our approach is general as it is based on principles that can be generalized to other domains.
Towards Unbiased Training in Federated Open-world Semi-supervised Learning
May 01, 2023Federated Semi-supervised Learning (FedSSL) has emerged as a new paradigm for allowing distributed clients to collaboratively train a machine learning model over scarce labeled data and abundant unlabeled data. However, existing works for FedSSL rely on a closed-world assumption that all local training data and global testing data are from seen classes observed in the labeled dataset. It is crucial to go one step further: adapting FL models to an open-world setting, where unseen classes exist in the unlabeled data. In this paper, we propose a novel Federatedopen-world Semi-Supervised Learning (FedoSSL) framework, which can solve the key challenge in distributed and open-world settings, i.e., the biased training process for heterogeneously distributed unseen classes. Specifically, since the advent of a certain unseen class depends on a client basis, the locally unseen classes (exist in multiple clients) are likely to receive differentiated superior aggregation effects than the globally unseen classes (exist only in one client). We adopt an uncertainty-aware suppressed loss to alleviate the biased training between locally unseen and globally unseen classes. Besides, we enable a calibration module supplementary to the global aggregation to avoid potential conflicting knowledge transfer caused by inconsistent data distribution among different clients. The proposed FedoSSL can be easily adapted to state-of-the-art FL methods, which is also validated via extensive experiments on benchmarks and real-world datasets (CIFAR-10, CIFAR-100 and CINIC-10).
* 12 pages
Understand Data Preprocessing for Effective End-to-End Training of Deep Neural Networks
Apr 18, 2023



In this paper, we primarily focus on understanding the data preprocessing pipeline for DNN Training in the public cloud. First, we run experiments to test the performance implications of the two major data preprocessing methods using either raw data or record files. The preliminary results show that data preprocessing is a clear bottleneck, even with the most efficient software and hardware configuration enabled by NVIDIA DALI, a high-optimized data preprocessing library. Second, we identify the potential causes, exercise a variety of optimization methods, and present their pros and cons. We hope this work will shed light on the new co-design of ``data storage, loading pipeline'' and ``training framework'' and flexible resource configurations between them so that the resources can be fully exploited and performance can be maximized.
Ten Years after ImageNet: A 360° Perspective on AI
Oct 01, 2022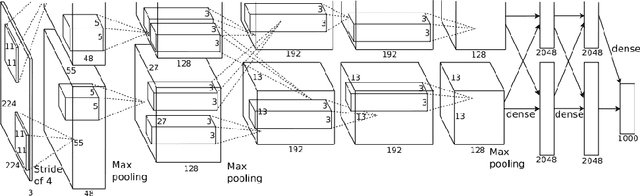
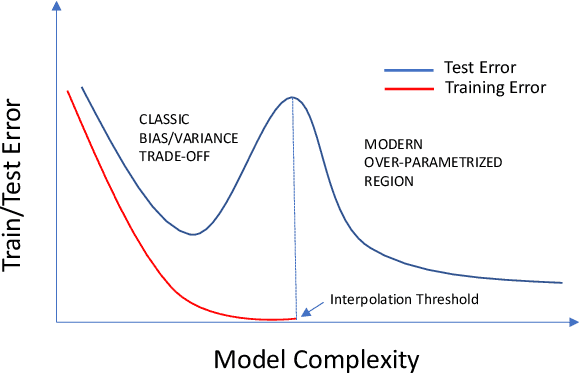
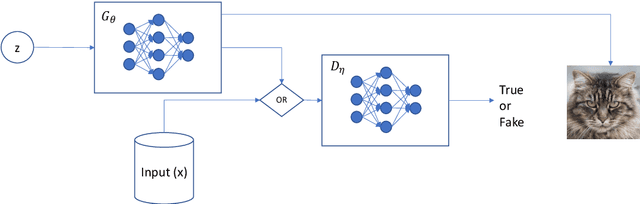
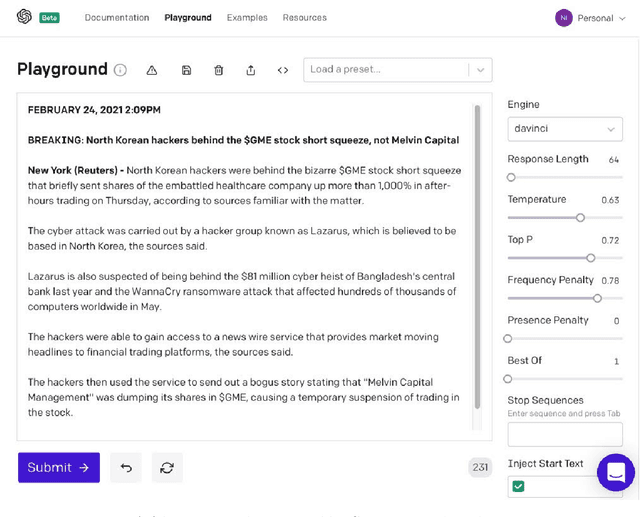
It is ten years since neural networks made their spectacular comeback. Prompted by this anniversary, we take a holistic perspective on Artificial Intelligence (AI). Supervised Learning for cognitive tasks is effectively solved - provided we have enough high-quality labeled data. However, deep neural network models are not easily interpretable, and thus the debate between blackbox and whitebox modeling has come to the fore. The rise of attention networks, self-supervised learning, generative modeling, and graph neural networks has widened the application space of AI. Deep Learning has also propelled the return of reinforcement learning as a core building block of autonomous decision making systems. The possible harms made possible by new AI technologies have raised socio-technical issues such as transparency, fairness, and accountability. The dominance of AI by Big-Tech who control talent, computing resources, and most importantly, data may lead to an extreme AI divide. Failure to meet high expectations in high profile, and much heralded flagship projects like self-driving vehicles could trigger another AI winter.
Parameterized Knowledge Transfer for Personalized Federated Learning
Nov 04, 2021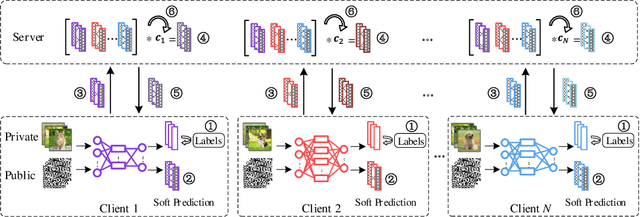
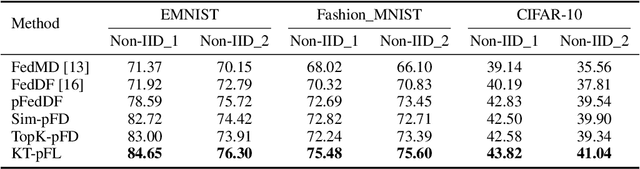
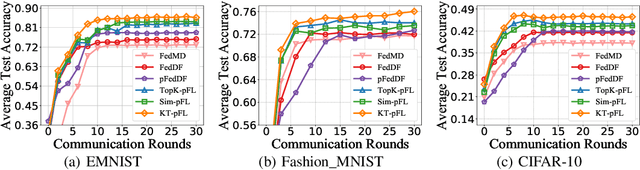
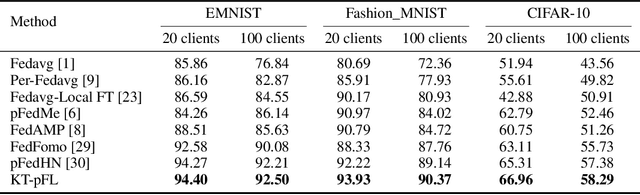
In recent years, personalized federated learning (pFL) has attracted increasing attention for its potential in dealing with statistical heterogeneity among clients. However, the state-of-the-art pFL methods rely on model parameters aggregation at the server side, which require all models to have the same structure and size, and thus limits the application for more heterogeneous scenarios. To deal with such model constraints, we exploit the potentials of heterogeneous model settings and propose a novel training framework to employ personalized models for different clients. Specifically, we formulate the aggregation procedure in original pFL into a personalized group knowledge transfer training algorithm, namely, KT-pFL, which enables each client to maintain a personalized soft prediction at the server side to guide the others' local training. KT-pFL updates the personalized soft prediction of each client by a linear combination of all local soft predictions using a knowledge coefficient matrix, which can adaptively reinforce the collaboration among clients who own similar data distribution. Furthermore, to quantify the contributions of each client to others' personalized training, the knowledge coefficient matrix is parameterized so that it can be trained simultaneously with the models. The knowledge coefficient matrix and the model parameters are alternatively updated in each round following the gradient descent way. Extensive experiments on various datasets (EMNIST, Fashion\_MNIST, CIFAR-10) are conducted under different settings (heterogeneous models and data distributions). It is demonstrated that the proposed framework is the first federated learning paradigm that realizes personalized model training via parameterized group knowledge transfer while achieving significant performance gain comparing with state-of-the-art algorithms.