 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Travel Planning with Behavior Forest
Apr 23, 2026Behavior sequences, composed of executable steps, serve as the operational foundation for multi-constraint planning problems such as travel planning. In such tasks, each planning step is not only constrained locally but also influenced by global constraints spanning multiple subtasks, leading to a tightly coupled and complex decision process. Existing travel planning methods typically rely on a single decision space that entangles all subtasks and constraints, failing to distinguish between locally acting constraints within a subtask and global constraints that span multiple subtasks. Consequently, the model is forced to jointly reason over local and global constraints at each decision step, increasing the reasoning burden and reducing planning efficiency. To address this problem, we propose the Behavior Forest method. Specifically, our approach structures the decision-making process into a forest of parallel behavior trees, where each behavior tree is responsible for a subtask. A global coordination mechanism is introduced to orchestrate the interactions among these trees, enabling modular and coherent travel planning. Within this framework, large language models are embedded as decision engines within behavior tree nodes, performing localized reasoning conditioned on task-specific constraints to generate candidate subplans and adapt decisions based on coordination feedback. The behavior trees, in turn, provide an explicit control structure that guides LLM generation. This design decouples complex tasks and constraints into manageable subspaces, enabling task-specific reasoning and reducing the cognitive load of LLM. Experimental results show that our method outperforms state-of-the-art methods by 6.67% on the TravelPlanner and by 11.82% on the ChinaTravel benchmarks, demonstrating its effectiveness in increasing LLM performance for complex multi-constraint travel planning.
ImgCoT: Compressing Long Chain of Thought into Compact Visual Tokens for Efficient Reasoning of Large Language Model
Jan 30, 2026Compressing long chains of thought (CoT) into compact latent tokens is crucial for efficient reasoning with large language models (LLMs). Recent studies employ autoencoders to achieve this by reconstructing textual CoT from latent tokens, thus encoding CoT semantics. However, treating textual CoT as the reconstruction target forces latent tokens to preserve surface-level linguistic features (e.g., word choice and syntax), introducing a strong linguistic inductive bias that prioritizes linguistic form over reasoning structure and limits logical abstraction. Thus, we propose ImgCoT that replaces the reconstruction target from textual CoT to the visual CoT obtained by rendering CoT into images. This substitutes linguistic bias with spatial inductive bias, i.e., a tendency to model spatial layouts of the reasoning steps in visual CoT, enabling latent tokens to better capture global reasoning structure. Moreover, although visual latent tokens encode abstract reasoning structure, they may blur reasoning details. We thus propose a loose ImgCoT, a hybrid reasoning that augments visual latent tokens with a few key textual reasoning steps, selected based on low token log-likelihood. This design allows LLMs to retain both global reasoning structure and fine-grained reasoning details with fewer tokens than the complete CoT. Extensive experiments across multiple datasets and LLMs demonstrate the effectiveness of the two versions of ImgCoT.
Soft Reasoning Paths for Knowledge Graph Completion
May 06, 2025Reasoning paths are reliable information in knowledge graph completion (KGC) in which algorithms can find strong clues of the actual relation between entities. However, in real-world applications, it is difficult to guarantee that computationally affordable paths exist toward all candidate entities. According to our observation, the prediction accuracy drops significantly when paths are absent. To make the proposed algorithm more stable against the missing path circumstances, we introduce soft reasoning paths. Concretely, a specific learnable latent path embedding is concatenated to each relation to help better model the characteristics of the corresponding paths. The combination of the relation and the corresponding learnable embedding is termed a soft path in our paper. By aligning the soft paths with the reasoning paths, a learnable embedding is guided to learn a generalized path representation of the corresponding relation. In addition, we introduce a hierarchical ranking strategy to make full use of information about the entity, relation, path, and soft path to help improve both the efficiency and accuracy of the model. Extensive experimental results illustrate that our algorithm outperforms the compared state-of-the-art algorithms by a notable margin. The code will be made publicly available after the paper is officially accepted.
Knowledge Graph Completion with Relation-Aware Anchor Enhancement
Apr 08, 2025



Text-based knowledge graph completion methods take advantage of pre-trained language models (PLM) to enhance intrinsic semantic connections of raw triplets with detailed text descriptions. Typical methods in this branch map an input query (textual descriptions associated with an entity and a relation) and its candidate entities into feature vectors, respectively, and then maximize the probability of valid triples. These methods are gaining promising performance and increasing attention for the rapid development of large language models. According to the property of the language models, the more related and specific context information the input query provides, the more discriminative the resultant embedding will be. In this paper, through observation and validation, we find a neglected fact that the relation-aware neighbors of the head entities in queries could act as effective contexts for more precise link prediction. Driven by this finding, we propose a relation-aware anchor enhanced knowledge graph completion method (RAA-KGC). Specifically, in our method, to provide a reference of what might the target entity be like, we first generate anchor entities within the relation-aware neighborhood of the head entity. Then, by pulling the query embedding towards the neighborhoods of the anchors, it is tuned to be more discriminative for target entity matching. The results of our extensive experiments not only validate the efficacy of RAA-KGC but also reveal that by integrating our relation-aware anchor enhancement strategy, the performance of current leading methods can be notably enhanced without substantial modifications.
Multi-Feature Integration for Perception-Dependent Examination-Bias Estimation
Feb 27, 2023Eliminating examination bias accurately is pivotal to apply click-through data to train an unbiased ranking model. However, most examination-bias estimators are limited to the hypothesis of Position-Based Model (PBM), which supposes that the calculation of examination bias only depends on the rank of the document. Recently, although some works introduce information such as clicks in the same query list and contextual information when calculating the examination bias, they still do not model the impact of document representation on search engine result pages (SERPs) that seriously affects one's perception of document relevance to a query when examining. Therefore, we propose a Multi-Feature Integration Model (MFIM) where the examination bias depends on the representation of document except the rank of it. Furthermore, we mine a key factor slipoff counts that can indirectly reflects the influence of all perception-bias factors. Real world experiments on Baidu-ULTR dataset demonstrate the superior effectiveness and robustness of the new approach. The source code is available at \href{https://github.com/lixsh6/Tencent_wsdm_cup2023/tree/main/pytorch_unbias}{https://github.com/lixsh6/Tencent\_wsdm\_cup2023}
Pretraining De-Biased Language Model with Large-scale Click Logs for Document Ranking
Feb 27, 2023Pre-trained language models have achieved great success in various large-scale information retrieval tasks. However, most of pretraining tasks are based on counterfeit retrieval data where the query produced by the tailored rule is assumed as the user's issued query on the given document or passage. Therefore, we explore to use large-scale click logs to pretrain a language model instead of replying on the simulated queries. Specifically, we propose to use user behavior features to pretrain a debiased language model for document ranking. Extensive experiments on Baidu desensitization click logs validate the effectiveness of our method. Our team on WSDM Cup 2023 Pre-training for Web Search won the 1st place with a Discounted Cumulative Gain @ 10 (DCG@10) score of 12.16525 on the final leaderboard.
HCNet: Hierarchical Context Network for Semantic Segmentation
Oct 20, 2020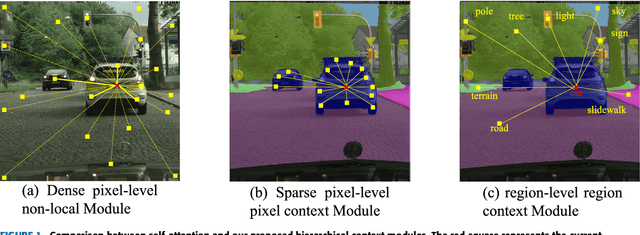

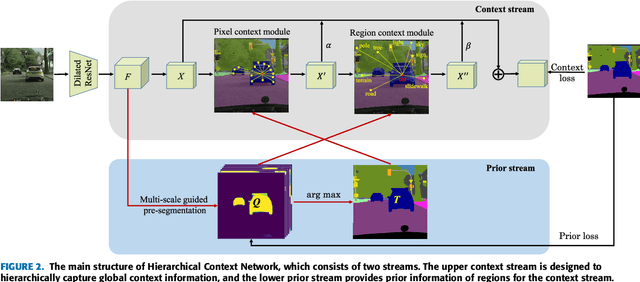
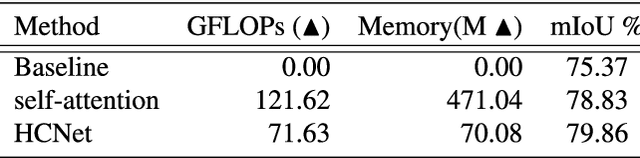
Global context information is vital in visual understanding problems, especially in pixel-level semantic segmentation. The mainstream methods adopt the self-attention mechanism to model global context information. However, pixels belonging to different classes usually have weak feature correlation. Modeling the global pixel-level correlation matrix indiscriminately is extremely redundant in the self-attention mechanism. In order to solve the above problem, we propose a hierarchical context network to differentially model homogeneous pixels with strong correlations and heterogeneous pixels with weak correlations. Specifically, we first propose a multi-scale guided pre-segmentation module to divide the entire feature map into different classed-based homogeneous regions. Within each homogeneous region, we design the pixel context module to capture pixel-level correlations. Subsequently, different from the self-attention mechanism that still models weak heterogeneous correlations in a dense pixel-level manner, the region context module is proposed to model sparse region-level dependencies using a unified representation of each region. Through aggregating fine-grained pixel context features and coarse-grained region context features, our proposed network can not only hierarchically model global context information but also harvest multi-granularity representations to more robustly identify multi-scale objects. We evaluate our approach on Cityscapes and the ISPRS Vaihingen dataset. Without Bells or Whistles, our approach realizes a mean IoU of 82.8% and overall accuracy of 91.4% on Cityscapes and ISPRS Vaihingen test set, achieving state-of-the-art results.