 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetCo: Unsupervised Contrastive Learning for Object Detection
Feb 09, 2021
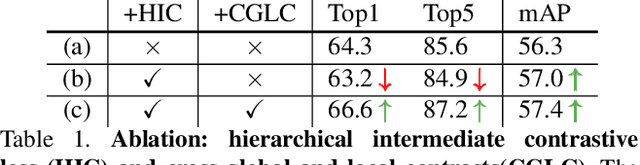
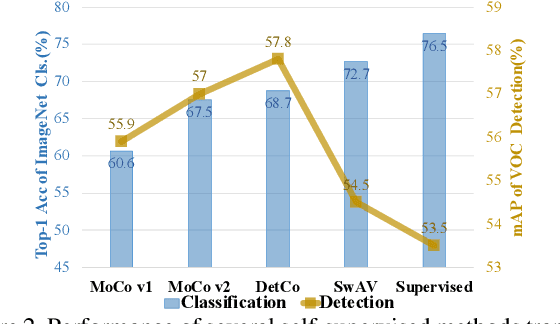
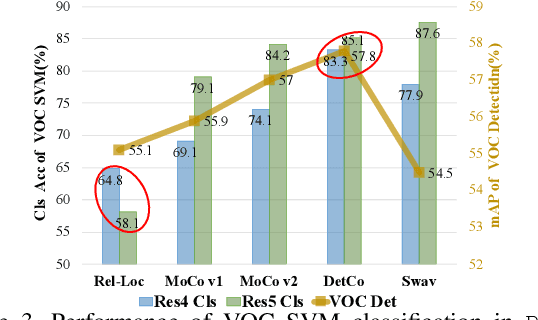
Unsupervised contrastive learning achieves great success in learning image representations with CNN. Unlike most recent methods that focused on improving accuracy of image classification, we present a novel contrastive learning approach, named DetCo, which fully explores the contrasts between global image and local image patches to learn discriminative representations for object detection. DetCo has several appealing benefits. (1) It is carefully designed by investigating the weaknesses of current self-supervised methods, which discard important representations for object detection. (2) DetCo builds hierarchical intermediate contrastive losses between global image and local patches to improve object detection, while maintaining global representations for image recognition. Theoretical analysis shows that the local patches actually remove the contextual information of an image, improving the lower bound of mutual information for better contrastive learning. (3) Extensive experiments on PASCAL VOC, COCO and Cityscapes demonstrate that DetCo not only outperforms state-of-the-art methods on object detection, but also on segmentation, pose estimation, and 3D shape prediction, while it is still competitive on image classification. For example, on PASCAL VOC, DetCo-100ep achieves 57.4 mAP, which is on par with the result of MoCov2-800ep. Moreover, DetCo consistently outperforms supervised method by 1.6/1.2/1.0 AP on Mask RCNN-C4/FPN/RetinaNet with 1x schedule. Code will be released at \href{https://github.com/xieenze/DetCo}{\color{blue}{\tt github.com/xieenze/DetCo}} and \href{https://github.com/open-mmlab/OpenSelfSup}{\color{blue}{\tt github.com/open-mmlab/OpenSelfSup}}.
Beyond Single Instance Multi-view Unsupervised Representation Learning
Nov 26, 2020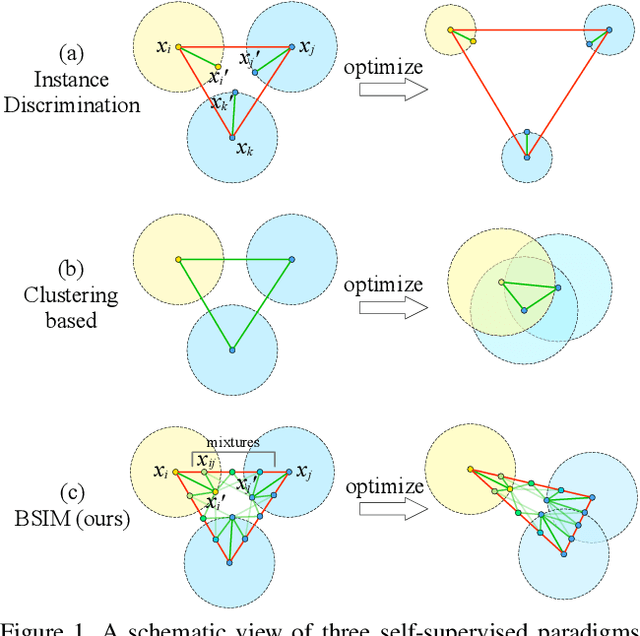
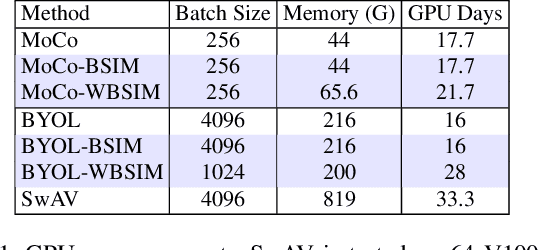
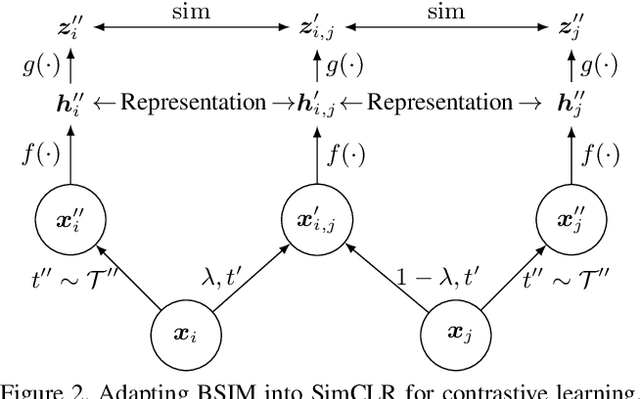
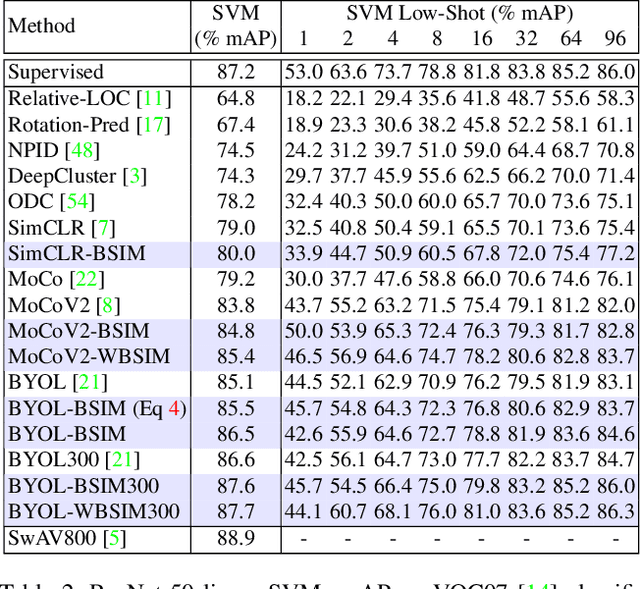
Recent unsupervised contrastive representation learning follows a Single Instance Multi-view (SIM) paradigm where positive pairs are usually constructed with intra-image data augmentation. In this paper, we propose an effective approach called Beyond Single Instance Multi-view (BSIM). Specifically, we impose more accurate instance discrimination capability by measuring the joint similarity between two randomly sampled instances and their mixture, namely spurious-positive pairs. We believe that learning joint similarity helps to improve the performance when encoded features are distributed more evenly in the latent space. We apply it as an orthogonal improvement for unsupervised contrastive representation learning, including current outstanding methods SimCLR, MoCo, and BYOL. We evaluate our learned representations on many downstream benchmarks like linear classification on ImageNet-1k and PASCAL VOC 2007, object detection on MS COCO 2017 and VOC, etc. We obtain substantial gains with a large margin almost on all these tasks compared with prior arts.
Delving into Inter-Image Invariance for Unsupervised Visual Representations
Aug 26, 2020
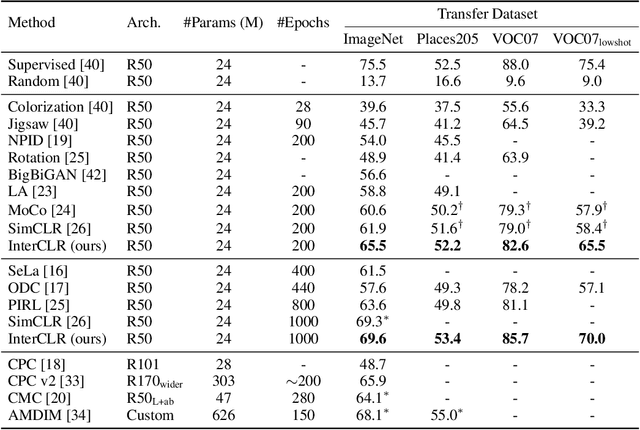
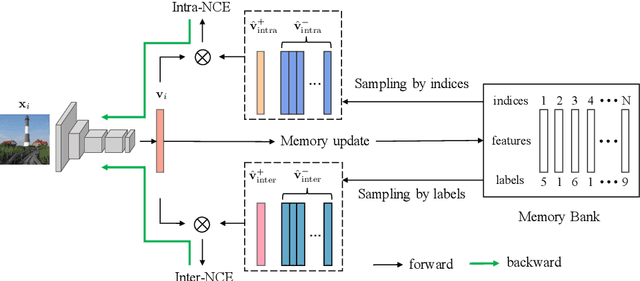
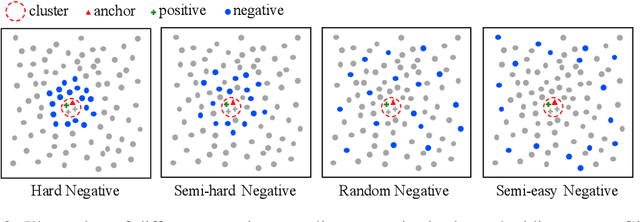
Contrastive learning has recently shown immense potential in unsupervised visual representation learning. Existing studies in this track mainly focus on intra-image invariance learning. The learning typically uses rich intra-image transformations to construct positive pairs and then maximizes agreement using a contrastive loss. The merits of inter-image invariance, conversely, remain much less explored. One major obstacle to exploit inter-image invariance is that it is unclear how to reliably construct inter-image positive pairs, and further derive effective supervision from them since there are no pair annotations available. In this work, we present a rigorous and comprehensive study on inter-image invariance learning from three main constituting components: pseudo-label maintenance, sampling strategy, and decision boundary design. Through carefully-designed comparisons and analysis, we propose a unified framework that supports the integration of unsupervised intra- and inter-image invariance learning. With all the obtained recipes, our final model, namely InterCLR, achieves state-of-the-art performance on standard benchmarks. Code and models will be available at https://github.com/open-mmlab/OpenSelfSup.
Online Deep Clustering for Unsupervised Representation Learning
Jun 18, 2020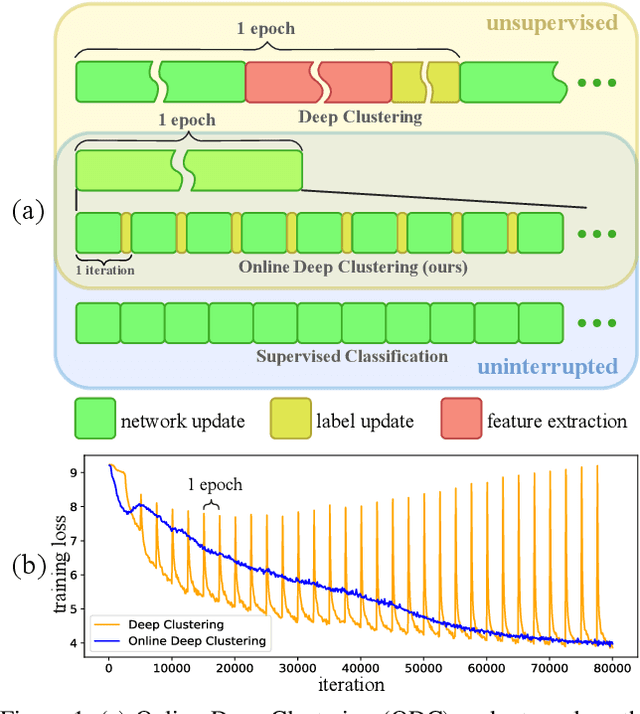
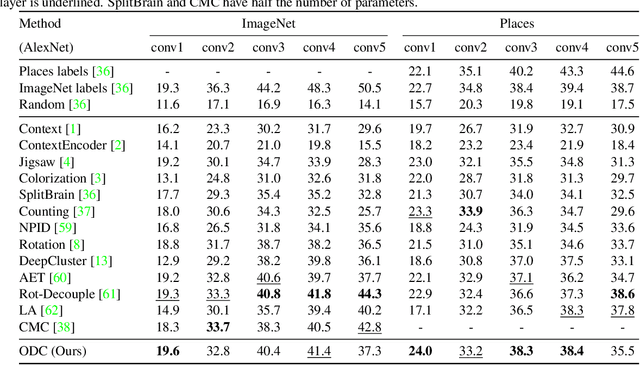
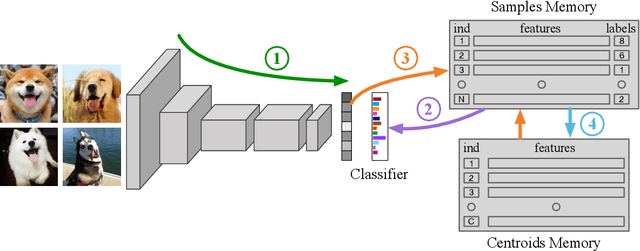
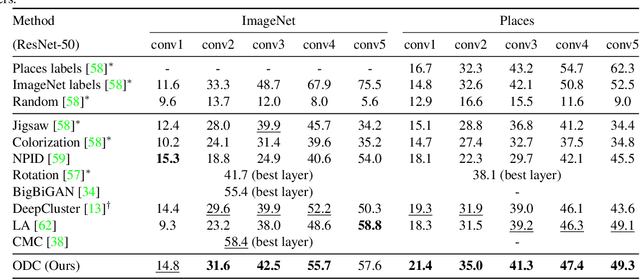
Joint clustering and feature learning methods have shown remarkable performance in unsupervised representation learning. However, the training schedule alternating between feature clustering and network parameters update leads to unstable learning of visual representations. To overcome this challenge, we propose Online Deep Clustering (ODC) that performs clustering and network update simultaneously rather than alternatingly. Our key insight is that the cluster centroids should evolve steadily in keeping the classifier stably updated. Specifically, we design and maintain two dynamic memory modules, i.e., samples memory to store samples labels and features, and centroids memory for centroids evolution. We break down the abrupt global clustering into steady memory update and batch-wise label re-assignment. The process is integrated into network update iterations. In this way, labels and the network evolve shoulder-to-shoulder rather than alternatingly. Extensive experiments demonstrate that ODC stabilizes the training process and boosts the performance effectively. Code: https://github.com/open-mmlab/OpenSelfSup.
Self-Supervised Scene De-occlusion
Apr 06, 2020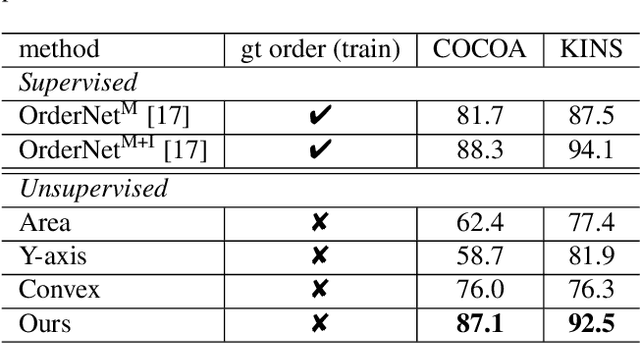
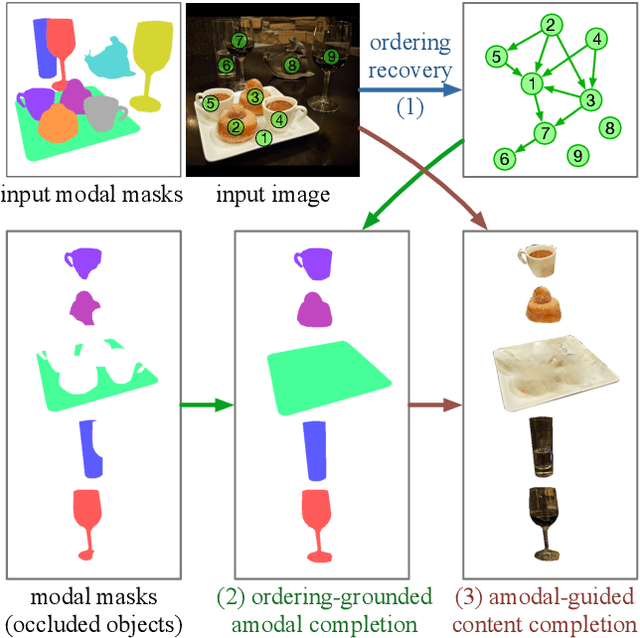
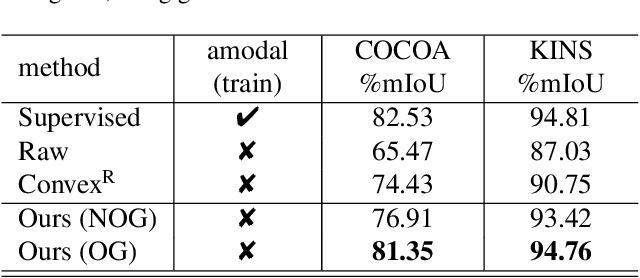
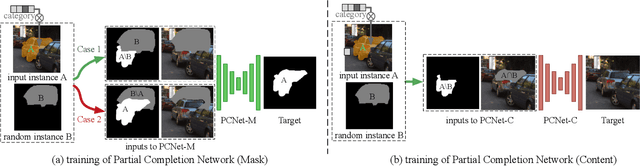
Natural scene understanding is a challenging task, particularly when encountering images of multiple objects that are partially occluded. This obstacle is given rise by varying object ordering and positioning. Existing scene understanding paradigms are able to parse only the visible parts, resulting in incomplete and unstructured scene interpretation. In this paper, we investigate the problem of scene de-occlusion, which aims to recover the underlying occlusion ordering and complete the invisible parts of occluded objects. We make the first attempt to address the problem through a novel and unified framework that recovers hidden scene structures without ordering and amodal annotations as supervisions. This is achieved via Partial Completion Network (PCNet)-mask (M) and -content (C), that learn to recover fractions of object masks and contents, respectively, in a self-supervised manner. Based on PCNet-M and PCNet-C, we devise a novel inference scheme to accomplish scene de-occlusion, via progressive ordering recovery, amodal completion and content completion. Extensive experiments on real-world scenes demonstrate the superior performance of our approach to other alternatives. Remarkably, our approach that is trained in a self-supervised manner achieves comparable results to fully-supervised methods. The proposed scene de-occlusion framework benefits many applications, including high-quality and controllable image manipulation and scene recomposition (see Fig. 1), as well as the conversion of existing modal mask annotations to amodal mask annotations.
Learning to Cluster Faces via Confidence and Connectivity Estimation
Apr 03, 2020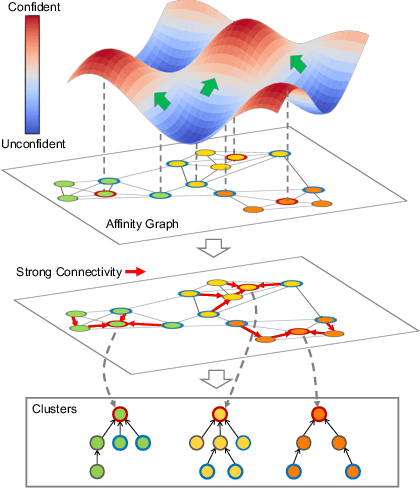
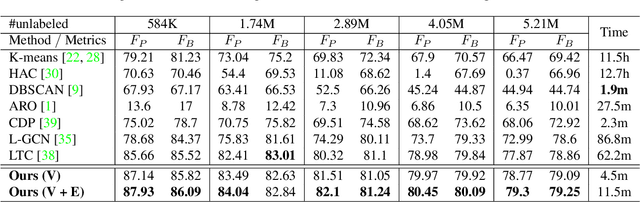
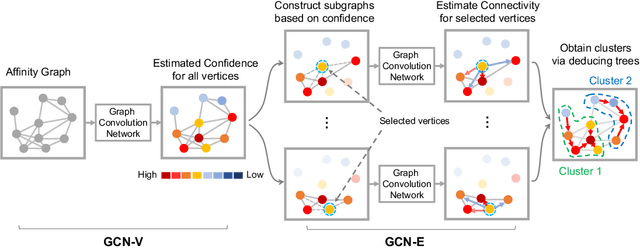
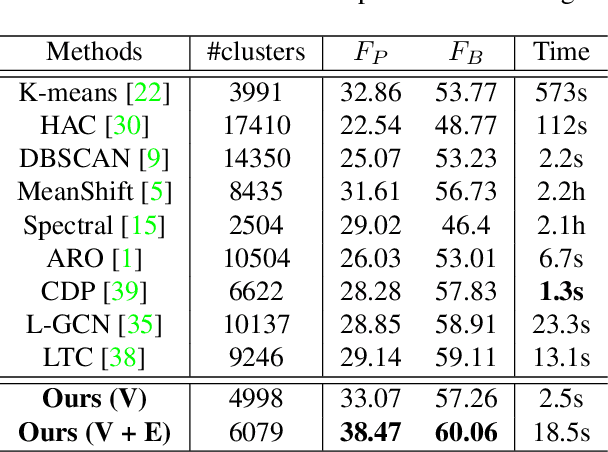
Face clustering is an essential tool for exploiting the unlabeled face data, and has a wide range of applications including face annotation and retrieval. Recent works show that supervised clustering can result in noticeable performance gain. However, they usually involve heuristic steps and require numerous overlapped subgraphs, severely restricting their accuracy and efficiency. In this paper, we propose a fully learnable clustering framework without requiring a large number of overlapped subgraphs. Instead, we transform the clustering problem into two sub-problems. Specifically, two graph convolutional networks, named GCN-V and GCN-E, are designed to estimate the confidence of vertices and the connectivity of edges, respectively. With the vertex confidence and edge connectivity, we can naturally organize more relevant vertices on the affinity graph and group them into clusters. Experiments on two large-scale benchmarks show that our method significantly improves clustering accuracy and thus performance of the recognition models trained on top, yet it is an order of magnitude more efficient than existing supervised methods.
Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation
Mar 31, 2020



Learning a good image prior is a long-term goal for image restoration and manipulation. While existing methods like deep image prior (DIP) capture low-level image statistics, there are still gaps toward an image prior that captures rich image semantics including color, spatial coherence, textures, and high-level concepts. This work presents an effective way to exploit the image prior captured by a generative adversarial network (GAN) trained on large-scale natural images. As shown in Fig.1, the deep generative prior (DGP) provides compelling results to restore missing semantics, e.g., color, patch, resolution, of various degraded images. It also enables diverse image manipulation including random jittering, image morphing, and category transfer. Such highly flexible restoration and manipulation are made possible through relaxing the assumption of existing GAN-inversion methods, which tend to fix the generator. Notably, we allow the generator to be fine-tuned on-the-fly in a progressive manner regularized by feature distance obtained by the discriminator in GAN. We show that these easy-to-implement and practical changes help preserve the reconstruction to remain in the manifold of nature image, and thus lead to more precise and faithful reconstruction for real images. Code is available at https://github.com/XingangPan/deepgenerative-prior.
Compound Domain Adaptation in an Open World
Sep 08, 2019
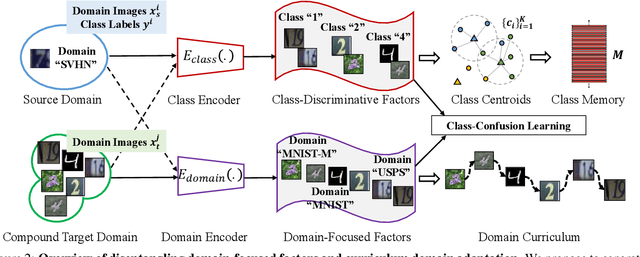

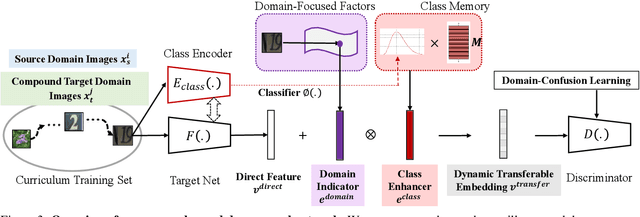
Existing works on domain adaptation often assume clear boundaries between source and target domains. Despite giving rise to a clean problem formalization, such form falls short of simulating the real world where domains are compounded of interleaving and confounding factors, blurring the domain boundaries. In this work, we opt for a different problem, dubbed open compound domain adaptation (OCDA), for studying the techniques of training domain-robust models in a more realistic setting. OCDA considers a compound (unlabeled) target domain which mixes several major factors (e.g., backgrounds, lighting conditions, etc.), along with a labeled training set, in the training stage and new open domains during inference. The compound target domain can be seen as a combination of multiple traditional target domains each with its own idiosyncrasy. To tackle OCDA, we propose a class-confusion loss to disentangle the domain-dominant factors out of the data and then use them to schedule a curriculum domain adaptation strategy. Moreover, we use a memory-augmented neural network architecture to increase the network's capacity for handling previously unseen domains. Extensive experiments on digit classification, facial expression recognition, semantic segmentation, and reinforcement learning verify the effectiveness of our approach.
Learning to Cluster Faces on an Affinity Graph
May 05, 2019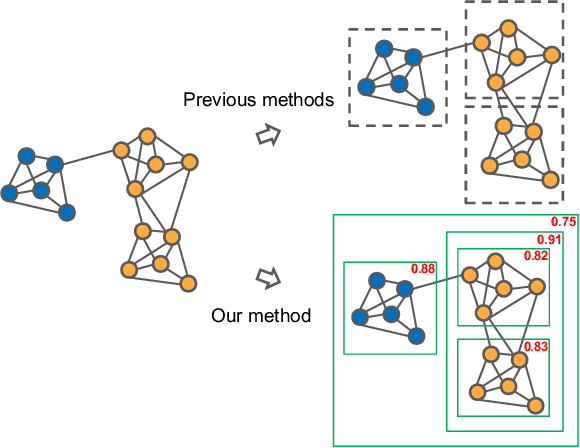
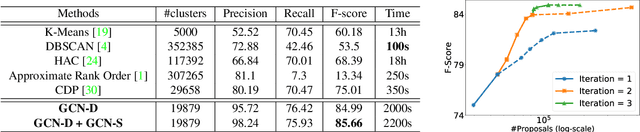
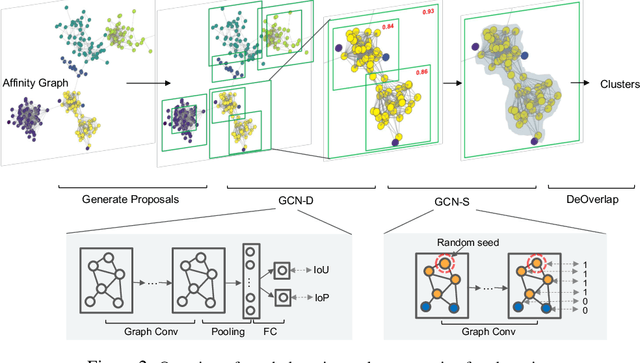
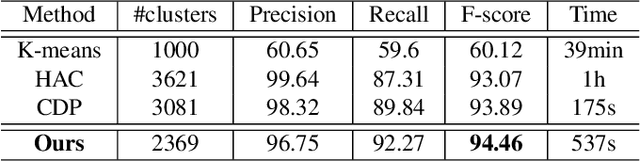
Face recognition sees remarkable progress in recent years, and its performance has reached a very high level. Taking it to a next level requires substantially larger data, which would involve prohibitive annotation cost. Hence, exploiting unlabeled data becomes an appealing alternative. Recent works have shown that clustering unlabeled faces is a promising approach, often leading to notable performance gains. Yet, how to effectively cluster, especially on a large-scale (i.e. million-level or above) dataset, remains an open question. A key challenge lies in the complex variations of cluster patterns, which make it difficult for conventional clustering methods to meet the needed accuracy. This work explores a novel approach, namely, learning to cluster instead of relying on hand-crafted criteria. Specifically, we propose a framework based on graph convolutional network, which combines a detection and a segmentation module to pinpoint face clusters. Experiments show that our method yields significantly more accurate face clusters, which, as a result, also lead to further performance gain in face recognition.
Self-Supervised Learning via Conditional Motion Propagation
Apr 25, 2019
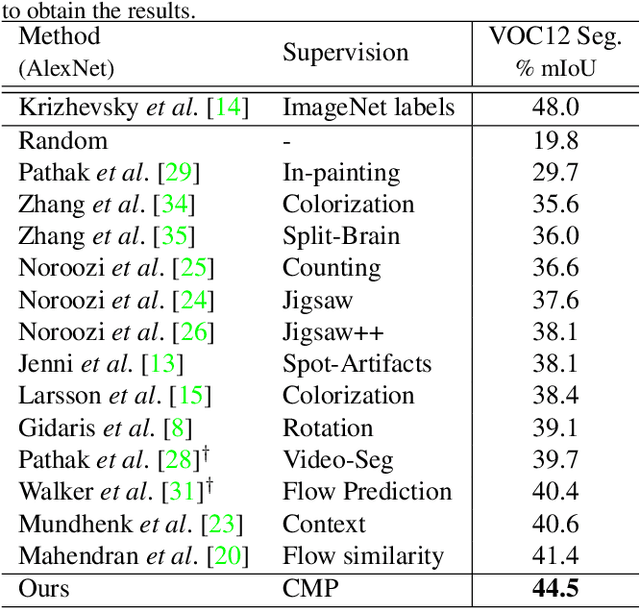
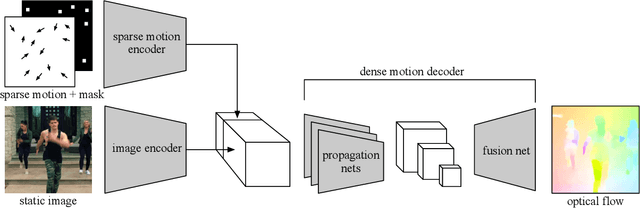
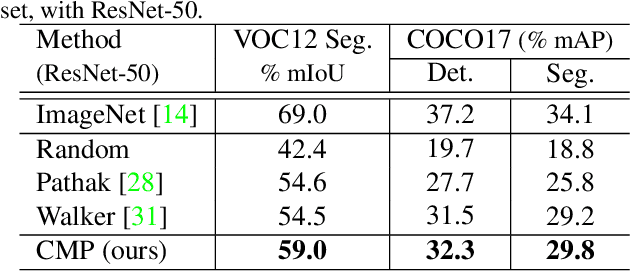
Intelligent agent naturally learns from motion. Various self-supervised algorithms have leveraged motion cues to learn effective visual representations. The hurdle here is that motion is both ambiguous and complex, rendering previous works either suffer from degraded learning efficacy, or resort to strong assumptions on object motions. In this work, we design a new learning-from-motion paradigm to bridge these gaps. Instead of explicitly modeling the motion probabilities, we design the pretext task as a conditional motion propagation problem. Given an input image and several sparse flow guidance vectors on it, our framework seeks to recover the full-image motion. Compared to other alternatives, our framework has several appealing properties: (1) Using sparse flow guidance during training resolves the inherent motion ambiguity, and thus easing feature learning. (2) Solving the pretext task of conditional motion propagation encourages the emergence of kinematically-sound representations that poss greater expressive power. Extensive experiments demonstrate that our framework learns structural and coherent features; and achieves state-of-the-art self-supervision performance on several downstream tasks including semantic segmentation, instance segmentation, and human parsing. Furthermore, our framework is successfully extended to several useful applications such as semi-automatic pixel-level annotation. Project page: "http://mmlab.ie.cuhk.edu.hk/projects/CMP/".