 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGR-OCC: Evolving Monocular Priors for Embodied 3D Occupancy Prediction via Soft-Gating Lifting and Semantic-Adaptive Geometric Refinement
Mar 14, 20263D semantic occupancy prediction is a cornerstone for embodied AI, enabling agents to perceive dense scene geometry and semantics incrementally from monocular video streams. However, current online frameworks face two critical bottlenecks: the inherent depth ambiguity of monocular estimation that causes "feature bleeding" at object boundaries , and the "cold start" instability where uninitialized temporal fusion layers distort high-quality spatial priors during early training stages. In this paper, we propose SGR-OCC (Soft-Gating and Ray-refinement Occupancy), a unified framework driven by the philosophy of "Inheritance and Evolution". To perfectly inherit monocular spatial expertise, we introduce a Soft-Gating Feature Lifter that explicitly models depth uncertainty via a Gaussian gate to probabilistically suppress background noise. Furthermore, a Dynamic Ray-Constrained Anchor Refinement module simplifies complex 3D displacement searches into efficient 1D depth corrections along camera rays, ensuring sub-voxel adherence to physical surfaces. To ensure stable evolution toward temporal consistency, we employ a Two-Phase Progressive Training Strategy equipped with identity-initialized fusion, effectively resolving the cold start problem and shielding spatial priors from noisy early gradients. Extensive experiments on the EmbodiedOcc-ScanNet and Occ-ScanNet benchmarks demonstrate that SGR-OCC achieves state-of-the-art performance. In local prediction tasks, SGR-OCC achieves a completion IoU of 58.55$\%$ and a semantic mIoU of 49.89$\%$, surpassing the previous best method, EmbodiedOcc++, by 3.65$\%$ and 3.69$\%$ respectively. In challenging embodied prediction tasks, our model reaches 55.72$\%$ SC-IoU and 46.22$\%$ mIoU. Qualitative results further confirm our model's superior capability in preserving structural integrity and boundary sharpness in complex indoor environments.
Large-Scale LiDAR-Inertial Dataset for Degradation-Robust High-Precision Mapping
Jul 28, 2025



This paper introduces a large-scale, high-precision LiDAR-Inertial Odometry (LIO) dataset, aiming to address the insufficient validation of LIO systems in complex real-world scenarios in existing research. The dataset covers four diverse real-world environments spanning 60,000 to 750,000 square meters, collected using a custom backpack-mounted platform equipped with multi-beam LiDAR, an industrial-grade IMU, and RTK-GNSS modules. The dataset includes long trajectories, complex scenes, and high-precision ground truth, generated by fusing SLAM-based optimization with RTK-GNSS anchoring, and validated for trajectory accuracy through the integration of oblique photogrammetry and RTK-GNSS. This dataset provides a comprehensive benchmark for evaluating the generalization ability of LIO systems in practical high-precision mapping scenarios.
Rendering Anywhere You See: Renderability Field-guided Gaussian Splatting
Apr 27, 2025



Scene view synthesis, which generates novel views from limited perspectives, is increasingly vital for applications like virtual reality, augmented reality, and robotics. Unlike object-based tasks, such as generating 360{\deg} views of a car, scene view synthesis handles entire environments where non-uniform observations pose unique challenges for stable rendering quality. To address this issue, we propose a novel approach: renderability field-guided gaussian splatting (RF-GS). This method quantifies input inhomogeneity through a renderability field, guiding pseudo-view sampling to enhanced visual consistency. To ensure the quality of wide-baseline pseudo-views, we train an image restoration model to map point projections to visible-light styles. Additionally, our validated hybrid data optimization strategy effectively fuses information of pseudo-view angles and source view textures. Comparative experiments on simulated and real-world data show that our method outperforms existing approaches in rendering stability.
OpenFusion++: An Open-vocabulary Real-time Scene Understanding System
Apr 27, 2025



Real-time open-vocabulary scene understanding is essential for efficient 3D perception in applications such as vision-language navigation, embodied intelligence, and augmented reality. However, existing methods suffer from imprecise instance segmentation, static semantic updates, and limited handling of complex queries. To address these issues, we present OpenFusion++, a TSDF-based real-time 3D semantic-geometric reconstruction system. Our approach refines 3D point clouds by fusing confidence maps from foundational models, dynamically updates global semantic labels via an adaptive cache based on instance area, and employs a dual-path encoding framework that integrates object attributes with environmental context for precise query responses. Experiments on the ICL, Replica, ScanNet, and ScanNet++ datasets demonstrate that OpenFusion++ significantly outperforms the baseline in both semantic accuracy and query responsiveness.
Plane Spiral OAM Mode-Group Based MIMO Communications: An Experimental Study
Mar 11, 2021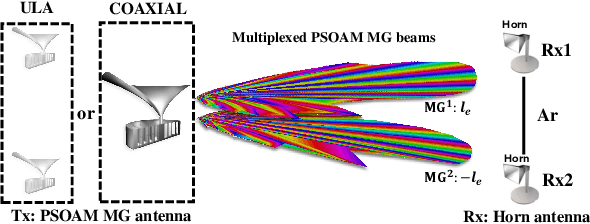
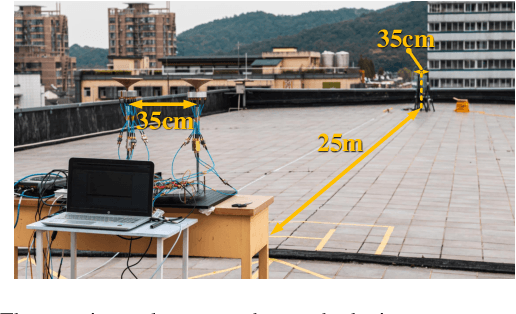
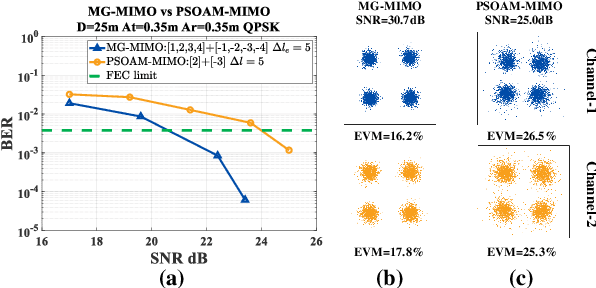
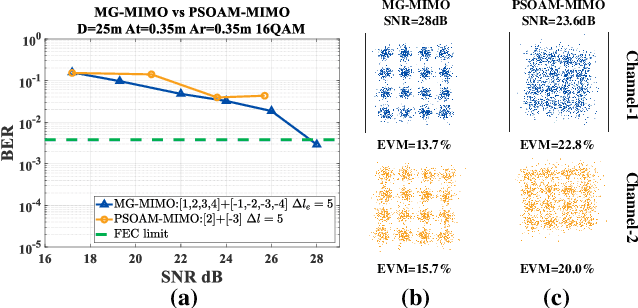
Spatial division multiplexing using conventional orbital angular momentum (OAM) has become a well-known physical layer transmission method over the past decade. The mode-group (MG) superposed by specific single mode plane spiral OAM (PSOAM) waves has been proved to be a flexible beamforming method to achieve the azimuthal pattern diversity, which inherits the spiral phase distribution of conventional OAM wave. Thus, it possesses both the beam directionality and vorticity. In this paper, it's the first time to show and verify novel PSOAM MG based multiple-in-multiple-out (MIMO) communication link (MG-MIMO) experimentally in a line-of-sight (LoS) scenario. A compact multi-mode PSOAM antenna is demonstrated experimentally to generate multiple independent controllable PSOAM waves, which can be used for constructing MGs. After several proof-of-principle tests, it has been verified that the beam directionality gain of MG can improve the receiving signal-to-noise (SNR) level in an actual system, meanwhile, the vorticity can provide another degree of freedom (DoF) to reduce the spatial correlation of MIMO system. Furthermore, a tentative long-distance transmission experiment operated at 10.2 GHz has been performed successfully at a distance of 50 m with a single-way spectrum efficiency of 3.7 bits/s/Hz/stream. The proposed MG-MIMO may have potential in the long-distance LoS back-haul scenario.
Variational Representation Learning for Vehicle Re-Identification
May 07, 2019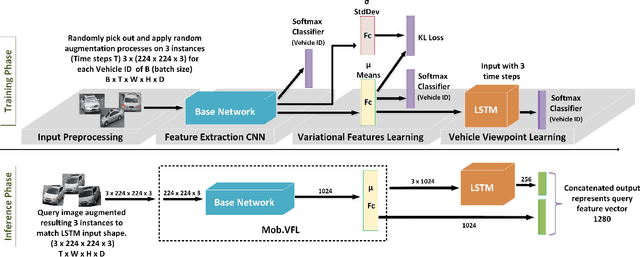
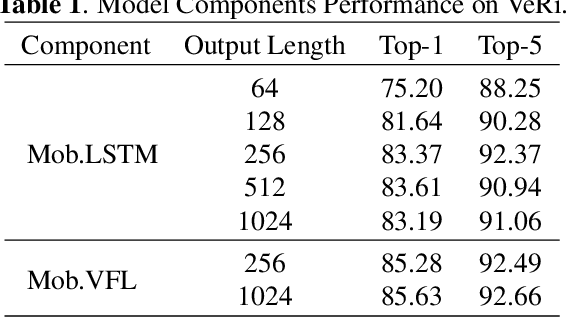
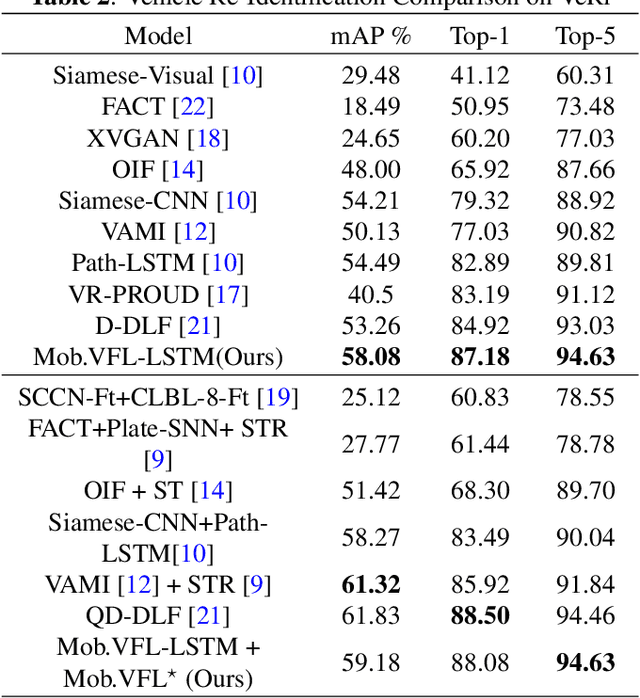
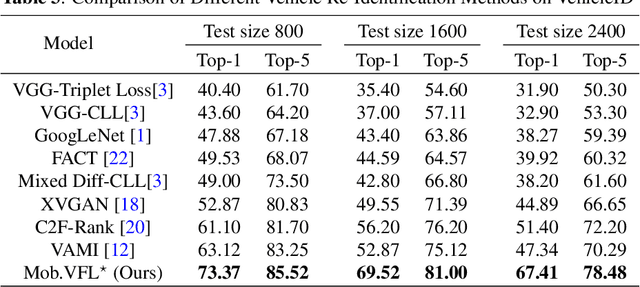
Vehicle Re-identification is attracting more and more attention in recent years. One of the most challenging problems is to learn an efficient representation for a vehicle from its multi-viewpoint images. Existing methods tend to derive features of dimensions ranging from thousands to tens of thousands. In this work we proposed a deep learning based framework that can lead to an efficient representation of vehicles. While the dimension of the learned features can be as low as 256, experiments on different datasets show that the Top-1 and Top-5 retrieval accuracies exceed multiple state-of-the-art methods. The key to our framework is two-fold. Firstly, variational feature learning is employed to generate variational features which are more discriminating. Secondly, long short-term memory (LSTM) is used to learn the relationship among different viewpoints of a vehicle. The LSTM also plays as an encoder to downsize the features.