 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConRPG: Paraphrase Generation using Contexts as Regularizer
Sep 01, 2021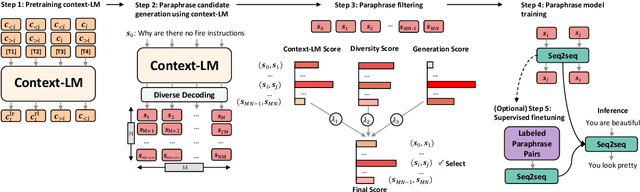
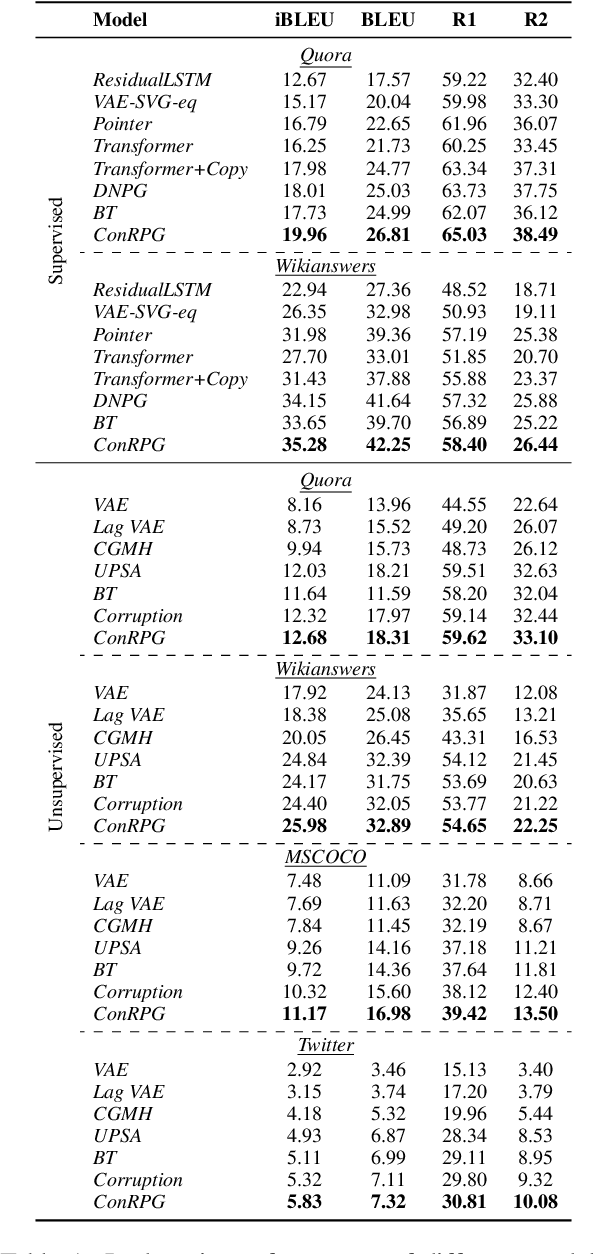
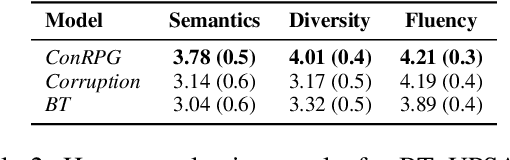
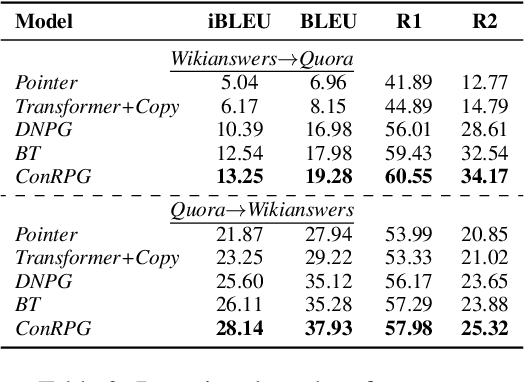
A long-standing issue with paraphrase generation is how to obtain reliable supervision signals. In this paper, we propose an unsupervised paradigm for paraphrase generation based on the assumption that the probabilities of generating two sentences with the same meaning given the same context should be the same. Inspired by this fundamental idea, we propose a pipelined system which consists of paraphrase candidate generation based on contextual language models, candidate filtering using scoring functions, and paraphrase model training based on the selected candidates. The proposed paradigm offers merits over existing paraphrase generation methods: (1) using the context regularizer on meanings, the model is able to generate massive amounts of high-quality paraphrase pairs; and (2) using human-interpretable scoring functions to select paraphrase pairs from candidates, the proposed framework provides a channel for developers to intervene with the data generation process, leading to a more controllable model. Experimental results across different tasks and datasets demonstrate that the effectiveness of the proposed model in both supervised and unsupervised setups.
$k$Folden: $k$-Fold Ensemble for Out-Of-Distribution Detection
Aug 29, 2021
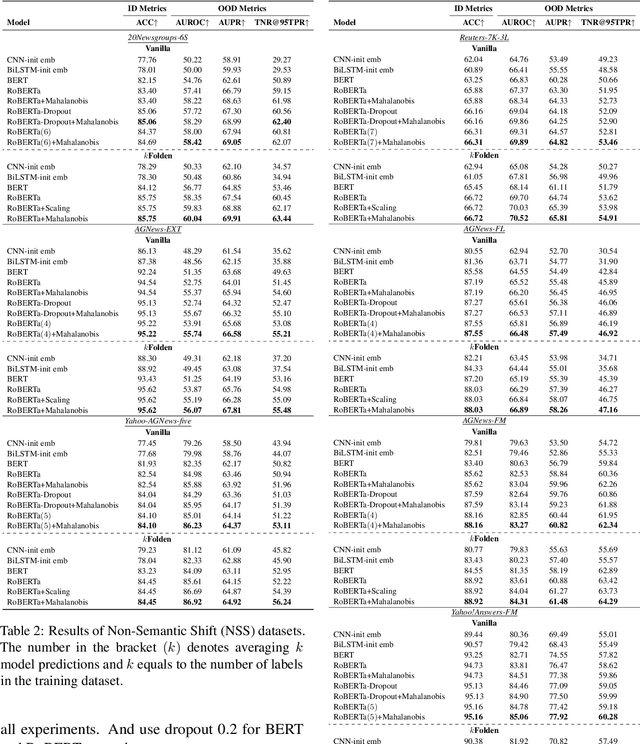

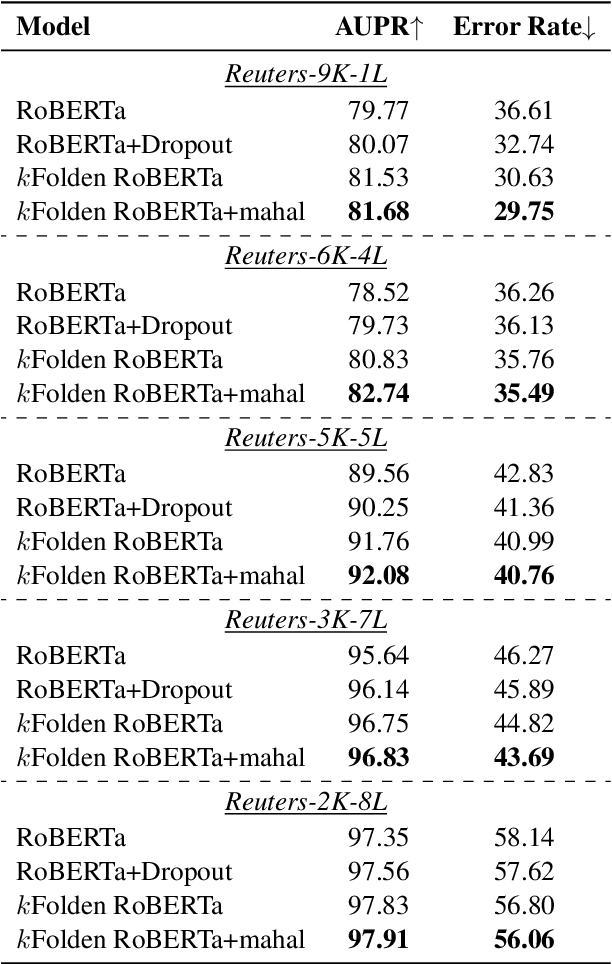
Out-of-Distribution (OOD) detection is an important problem in natural language processing (NLP). In this work, we propose a simple yet effective framework $k$Folden, which mimics the behaviors of OOD detection during training without the use of any external data. For a task with $k$ training labels, $k$Folden induces $k$ sub-models, each of which is trained on a subset with $k-1$ categories with the left category masked unknown to the sub-model. Exposing an unknown label to the sub-model during training, the model is encouraged to learn to equally attribute the probability to the seen $k-1$ labels for the unknown label, enabling this framework to simultaneously resolve in- and out-distribution examples in a natural way via OOD simulations. Taking text classification as an archetype, we develop benchmarks for OOD detection using existing text classification datasets. By conducting comprehensive comparisons and analyses on the developed benchmarks, we demonstrate the superiority of $k$Folden against current methods in terms of improving OOD detection performances while maintaining improved in-domain classification accuracy.
Layer-wise Model Pruning based on Mutual Information
Aug 28, 2021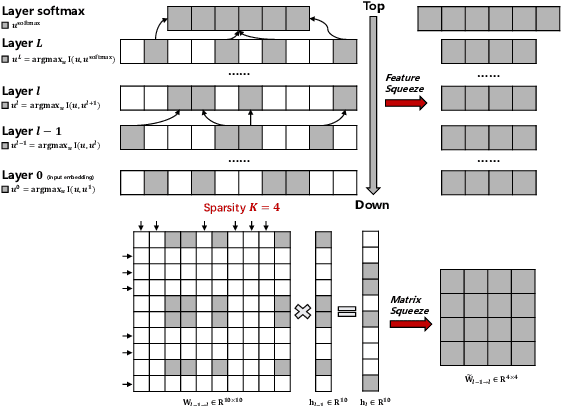
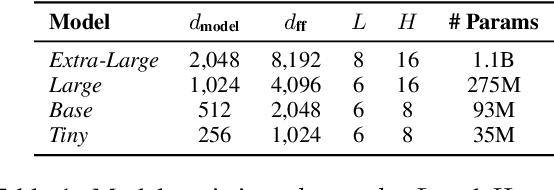
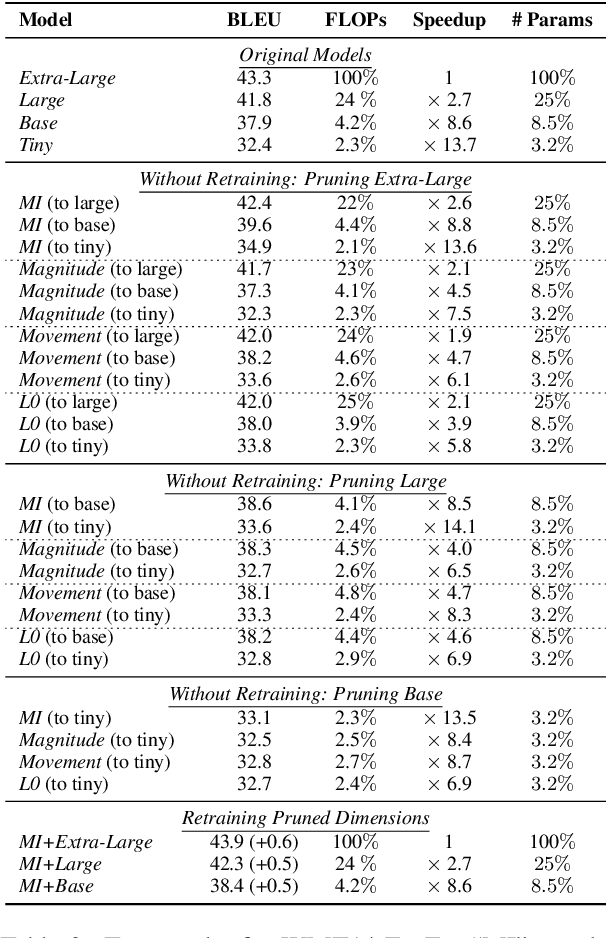
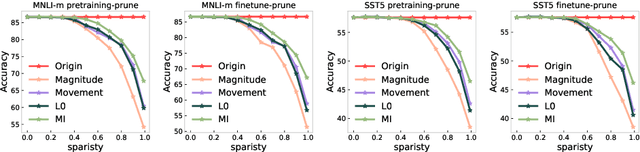
The proposed pruning strategy offers merits over weight-based pruning techniques: (1) it avoids irregular memory access since representations and matrices can be squeezed into their smaller but dense counterparts, leading to greater speedup; (2) in a manner of top-down pruning, the proposed method operates from a more global perspective based on training signals in the top layer, and prunes each layer by propagating the effect of global signals through layers, leading to better performances at the same sparsity level. Extensive experiments show that at the same sparsity level, the proposed strategy offers both greater speedup and higher performances than weight-based pruning methods (e.g., magnitude pruning, movement pruning).
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
Jun 30, 2021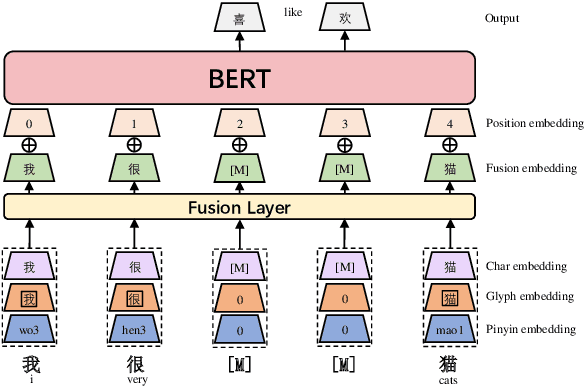

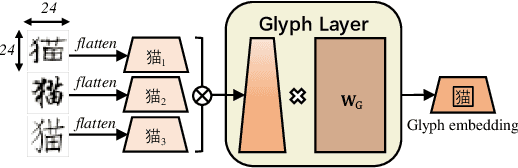
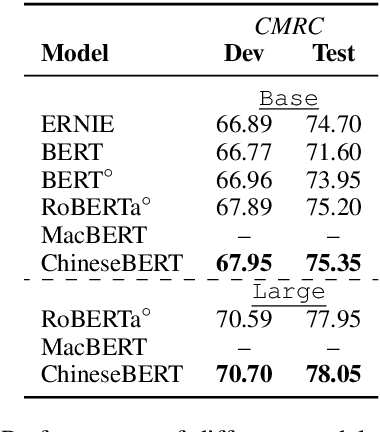
Recent pretraining models in Chinese neglect two important aspects specific to the Chinese language: glyph and pinyin, which carry significant syntax and semantic information for language understanding. In this work, we propose ChineseBERT, which incorporates both the {\it glyph} and {\it pinyin} information of Chinese characters into language model pretraining. The glyph embedding is obtained based on different fonts of a Chinese character, being able to capture character semantics from the visual features, and the pinyin embedding characterizes the pronunciation of Chinese characters, which handles the highly prevalent heteronym phenomenon in Chinese (the same character has different pronunciations with different meanings). Pretrained on large-scale unlabeled Chinese corpus, the proposed ChineseBERT model yields significant performance boost over baseline models with fewer training steps. The porpsoed model achieves new SOTA performances on a wide range of Chinese NLP tasks, including machine reading comprehension, natural language inference, text classification, sentence pair matching, and competitive performances in named entity recognition. Code and pretrained models are publicly available at https://github.com/ShannonAI/ChineseBert.
Defending against Backdoor Attacks in Natural Language Generation
Jun 03, 2021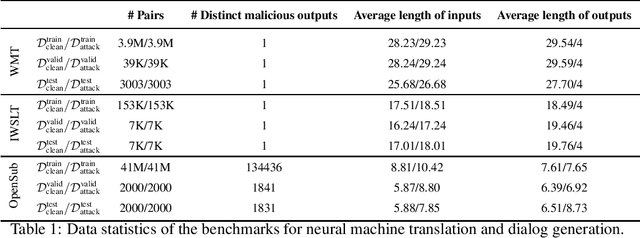

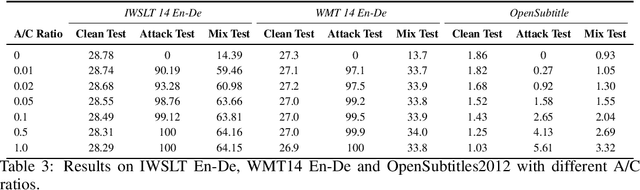
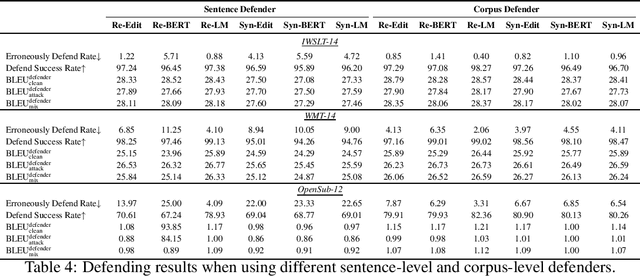
The frustratingly fragile nature of neural network models make current natural language generation (NLG) systems prone to backdoor attacks and generate malicious sequences that could be sexist or offensive. Unfortunately, little effort has been invested to how backdoor attacks can affect current NLG models and how to defend against these attacks. In this work, we investigate this problem on two important NLG tasks, machine translation and dialogue generation. By giving a formal definition for backdoor attack and defense, and developing corresponding benchmarks, we design methods to attack NLG models, which achieve high attack success to ask NLG models to generate malicious sequences. To defend against these attacks, we propose to detect the attack trigger by examining the effect of deleting or replacing certain words on the generation outputs, which we find successful for certain types of attacks. We will discuss the limitation of this work, and hope this work can raise the awareness of backdoor risks concealed in deep NLG systems. (Code and data are available at https://github.com/ShannonAI/backdoor_nlg.)
Fast Nearest Neighbor Machine Translation
May 30, 2021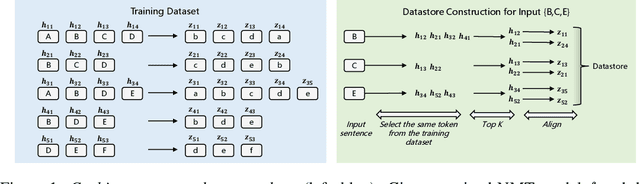


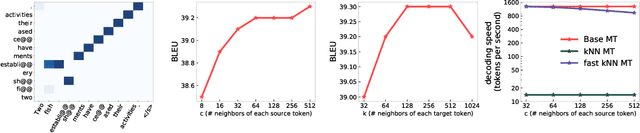
Though nearest neighbor Machine Translation ($k$NN-MT) \cite{khandelwal2020nearest} has proved to introduce significant performance boosts over standard neural MT systems, it is prohibitively slow since it uses the entire reference corpus as the datastore for the nearest neighbor search. This means each step for each beam in the beam search has to search over the entire reference corpus. $k$NN-MT is thus two-order slower than vanilla MT models, making it hard to be applied to real-world applications, especially online services. In this work, we propose Fast $k$NN-MT to address this issue. Fast $k$NN-MT constructs a significantly smaller datastore for the nearest neighbor search: for each word in a source sentence, Fast $k$NN-MT first selects its nearest token-level neighbors, which is limited to tokens that are the same as the query token. Then at each decoding step, in contrast to using the entire corpus as the datastore, the search space is limited to target tokens corresponding to the previously selected reference source tokens. This strategy avoids search through the whole datastore for nearest neighbors and drastically improves decoding efficiency. Without loss of performance, Fast $k$NN-MT is two-order faster than $k$NN-MT, and is only two times slower than the standard NMT model. Fast $k$NN-MT enables the practical use of $k$NN-MT systems in real-world MT applications.\footnote{Code is available at \url{https://github.com/ShannonAI/fast-knn-nmt.}}
Parameter Estimation for the SEIR Model Using Recurrent Nets
May 30, 2021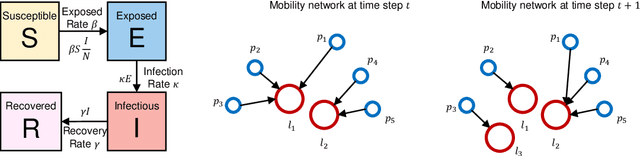
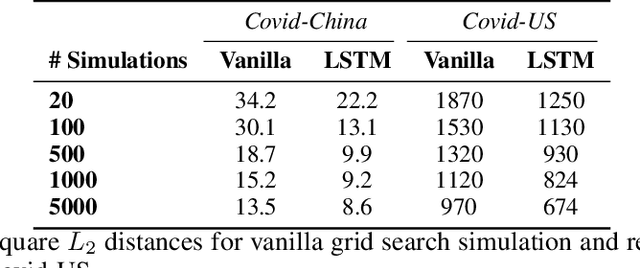


The standard way to estimate the parameters $\Theta_\text{SEIR}$ (e.g., the transmission rate $\beta$) of an SEIR model is to use grid search, where simulations are performed on each set of parameters, and the parameter set leading to the least $L_2$ distance between predicted number of infections and observed infections is selected. This brute-force strategy is not only time consuming, as simulations are slow when the population is large, but also inaccurate, since it is impossible to enumerate all parameter combinations. To address these issues, in this paper, we propose to transform the non-differentiable problem of finding optimal $\Theta_\text{SEIR}$ to a differentiable one, where we first train a recurrent net to fit a small number of simulation data. Next, based on this recurrent net that is able to generalize SEIR simulations, we are able to transform the objective to a differentiable one with respect to $\Theta_\text{SEIR}$, and straightforwardly obtain its optimal value. The proposed strategy is both time efficient as it only relies on a small number of SEIR simulations, and accurate as we are able to find the optimal $\Theta_\text{SEIR}$ based on the differentiable objective. On two COVID-19 datasets, we observe that the proposed strategy leads to significantly better parameter estimations with a smaller number of simulations.
Modeling Text-visual Mutual Dependency for Multi-modal Dialog Generation
May 30, 2021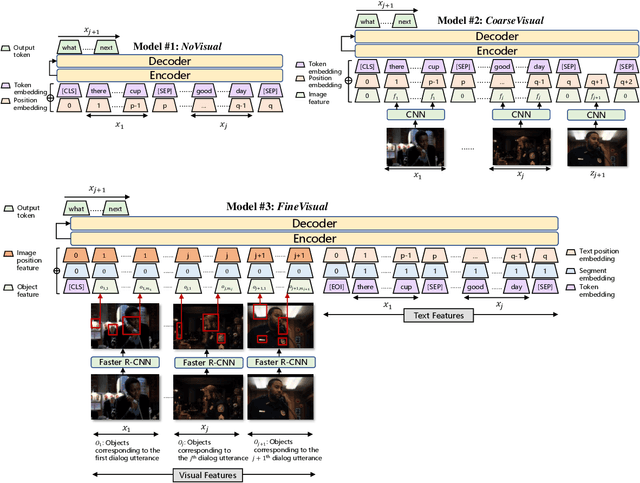
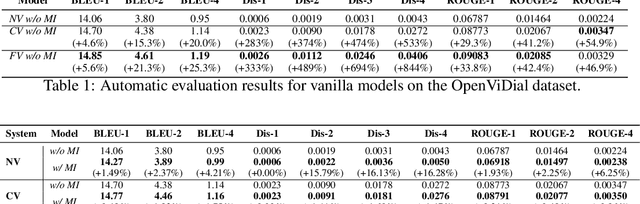
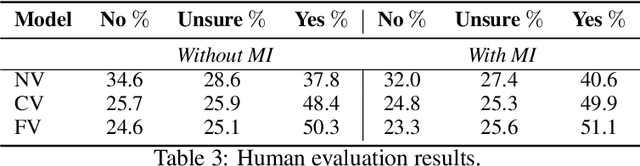

Multi-modal dialog modeling is of growing interest. In this work, we propose frameworks to resolve a specific case of multi-modal dialog generation that better mimics multi-modal dialog generation in the real world, where each dialog turn is associated with the visual context in which it takes place. Specifically, we propose to model the mutual dependency between text-visual features, where the model not only needs to learn the probability of generating the next dialog utterance given preceding dialog utterances and visual contexts, but also the probability of predicting the visual features in which a dialog utterance takes place, leading the generated dialog utterance specific to the visual context. We observe significant performance boosts over vanilla models when the mutual dependency between text and visual features is modeled. Code is available at https://github.com/ShannonAI/OpenViDial.
Dependency Parsing as MRC-based Span-Span Prediction
May 17, 2021

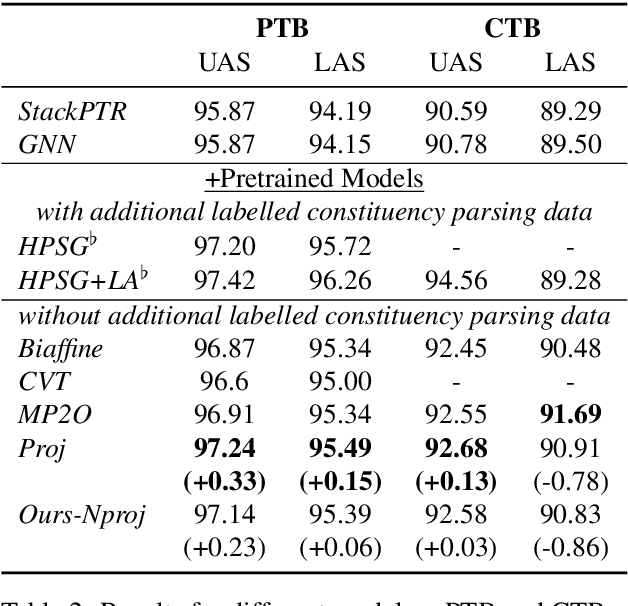
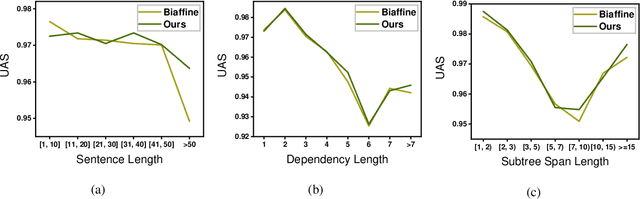
Higher-order methods for dependency parsing can partially but not fully addresses the issue that edges in dependency tree should be constructed at the text span/subtree level rather than word level. % This shortcoming can cause an incorrect span covered the corresponding tree rooted at a certain word though the word is correctly linked to its head. In this paper, we propose a new method for dependency parsing to address this issue. The proposed method constructs dependency trees by directly modeling span-span (in other words, subtree-subtree) relations. It consists of two modules: the {\it text span proposal module} which proposes candidate text spans, each of which represents a subtree in the dependency tree denoted by (root, start, end); and the {\it span linking module}, which constructs links between proposed spans. We use the machine reading comprehension (MRC) framework as the backbone to formalize the span linking module in an MRC setup, where one span is used as a query to extract the text span/subtree it should be linked to. The proposed method comes with the following merits: (1) it addresses the fundamental problem that edges in a dependency tree should be constructed between subtrees; (2) the MRC framework allows the method to retrieve missing spans in the span proposal stage, which leads to higher recall for eligible spans. Extensive experiments on the PTB, CTB and Universal Dependencies (UD) benchmarks demonstrate the effectiveness of the proposed method. We are able to achieve new SOTA performances on PTB and UD benchmarks, and competitive performances to previous SOTA models on the CTB dataset. Code is available at https://github.com/ShannonAI/mrc-for-dependency-parsing.
Sentence Similarity Based on Contexts
May 17, 2021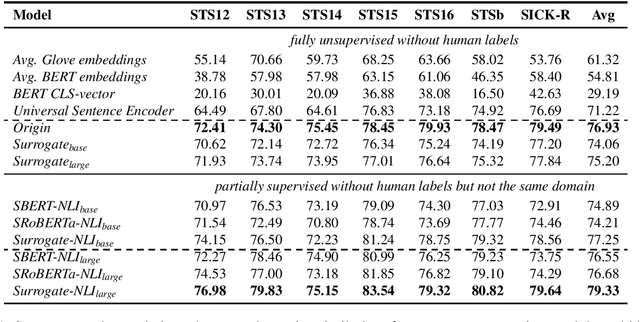

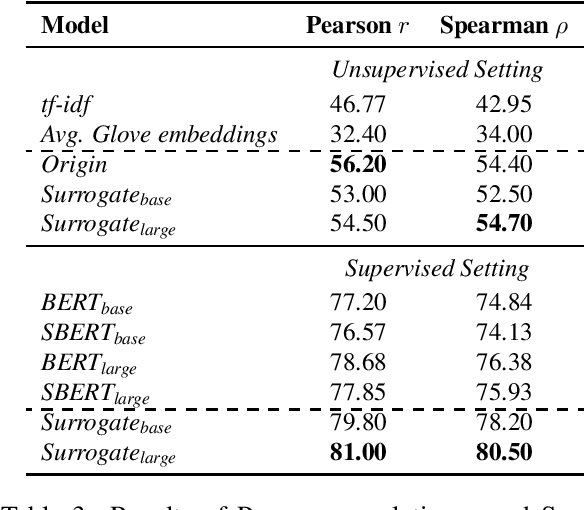
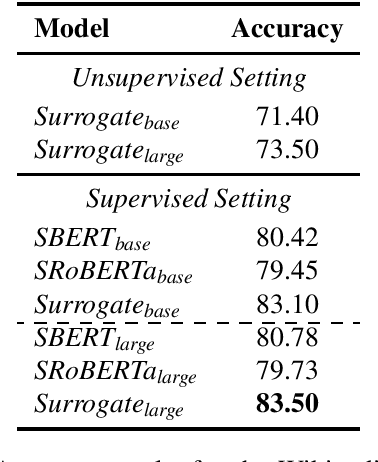
Existing methods to measure sentence similarity are faced with two challenges: (1) labeled datasets are usually limited in size, making them insufficient to train supervised neural models; (2) there is a training-test gap for unsupervised language modeling (LM) based models to compute semantic scores between sentences, since sentence-level semantics are not explicitly modeled at training. This results in inferior performances in this task. In this work, we propose a new framework to address these two issues. The proposed framework is based on the core idea that the meaning of a sentence should be defined by its contexts, and that sentence similarity can be measured by comparing the probabilities of generating two sentences given the same context. The proposed framework is able to generate high-quality, large-scale dataset with semantic similarity scores between two sentences in an unsupervised manner, with which the train-test gap can be largely bridged. Extensive experiments show that the proposed framework achieves significant performance boosts over existing baselines under both the supervised and unsupervised settings across different datasets.