 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxMatch: Semi-Supervised Learning with Worst-Case Consistency
Sep 26, 2022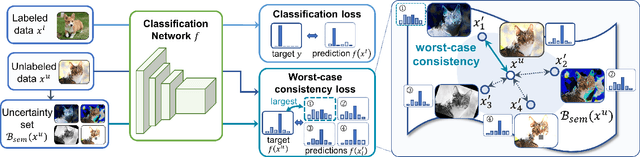
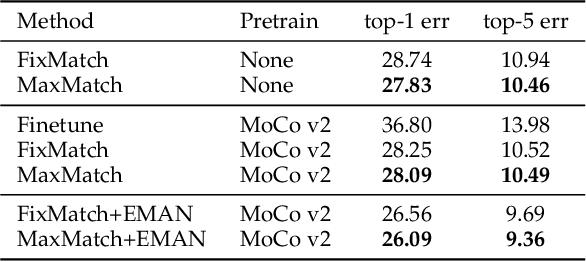

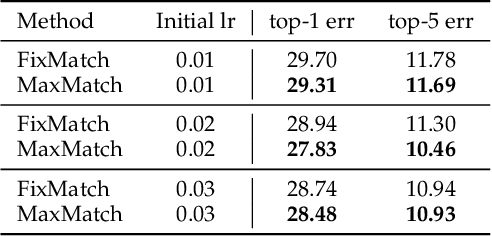
In recent years, great progress has been made to incorporate unlabeled data to overcome the inefficiently supervised problem via semi-supervised learning (SSL). Most state-of-the-art models are based on the idea of pursuing consistent model predictions over unlabeled data toward the input noise, which is called consistency regularization. Nonetheless, there is a lack of theoretical insights into the reason behind its success. To bridge the gap between theoretical and practical results, we propose a worst-case consistency regularization technique for SSL in this paper. Specifically, we first present a generalization bound for SSL consisting of the empirical loss terms observed on labeled and unlabeled training data separately. Motivated by this bound, we derive an SSL objective that minimizes the largest inconsistency between an original unlabeled sample and its multiple augmented variants. We then provide a simple but effective algorithm to solve the proposed minimax problem, and theoretically prove that it converges to a stationary point. Experiments on five popular benchmark datasets validate the effectiveness of our proposed method.
Enhance the Visual Representation via Discrete Adversarial Training
Sep 16, 2022



Adversarial Training (AT), which is commonly accepted as one of the most effective approaches defending against adversarial examples, can largely harm the standard performance, thus has limited usefulness on industrial-scale production and applications. Surprisingly, this phenomenon is totally opposite in Natural Language Processing (NLP) task, where AT can even benefit for generalization. We notice the merit of AT in NLP tasks could derive from the discrete and symbolic input space. For borrowing the advantage from NLP-style AT, we propose Discrete Adversarial Training (DAT). DAT leverages VQGAN to reform the image data to discrete text-like inputs, i.e. visual words. Then it minimizes the maximal risk on such discrete images with symbolic adversarial perturbations. We further give an explanation from the perspective of distribution to demonstrate the effectiveness of DAT. As a plug-and-play technique for enhancing the visual representation, DAT achieves significant improvement on multiple tasks including image classification, object detection and self-supervised learning. Especially, the model pre-trained with Masked Auto-Encoding (MAE) and fine-tuned by our DAT without extra data can get 31.40 mCE on ImageNet-C and 32.77% top-1 accuracy on Stylized-ImageNet, building the new state-of-the-art. The code will be available at https://github.com/alibaba/easyrobust.
Beyond ImageNet Attack: Towards Crafting Adversarial Examples for Black-box Domains
Feb 10, 2022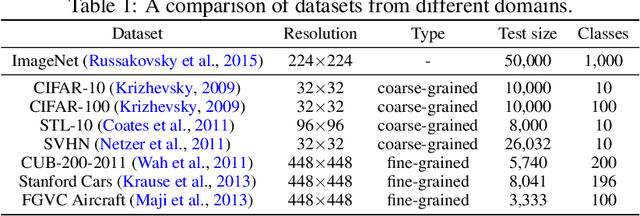
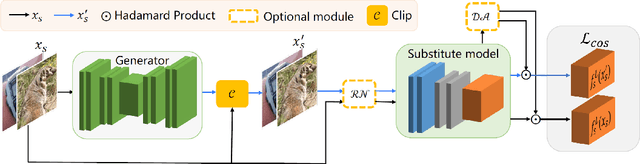
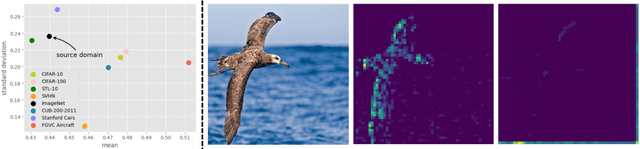
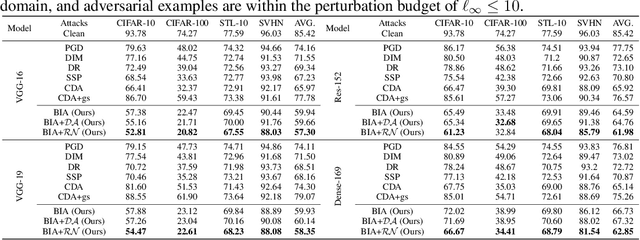
Adversarial examples have posed a severe threat to deep neural networks due to their transferable nature. Currently, various works have paid great efforts to enhance the cross-model transferability, which mostly assume the substitute model is trained in the same domain as the target model. However, in reality, the relevant information of the deployed model is unlikely to leak. Hence, it is vital to build a more practical black-box threat model to overcome this limitation and evaluate the vulnerability of deployed models. In this paper, with only the knowledge of the ImageNet domain, we propose a Beyond ImageNet Attack (BIA) to investigate the transferability towards black-box domains (unknown classification tasks). Specifically, we leverage a generative model to learn the adversarial function for disrupting low-level features of input images. Based on this framework, we further propose two variants to narrow the gap between the source and target domains from the data and model perspectives, respectively. Extensive experiments on coarse-grained and fine-grained domains demonstrate the effectiveness of our proposed methods. Notably, our methods outperform state-of-the-art approaches by up to 7.71\% (towards coarse-grained domains) and 25.91\% (towards fine-grained domains) on average. Our code is available at \url{https://github.com/qilong-zhang/Beyond-ImageNet-Attack}.
Towards Robust Vision Transformer
May 26, 2021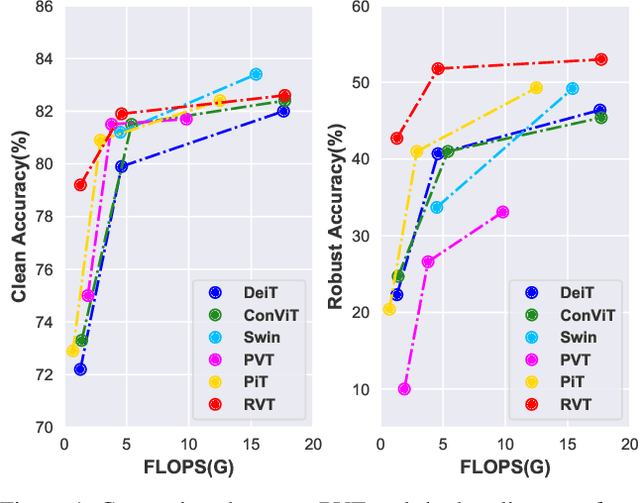
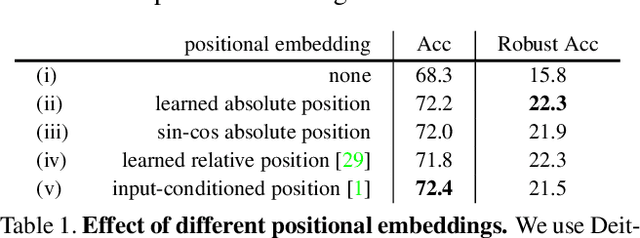
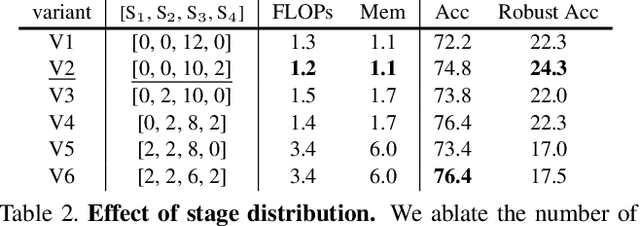
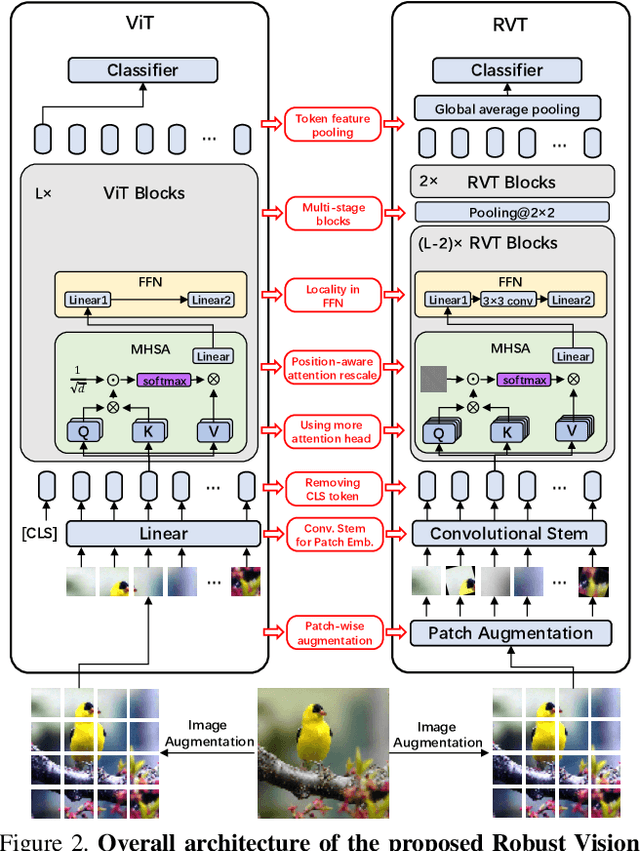
Recent advances on Vision Transformer (ViT) and its improved variants have shown that self-attention-based networks surpass traditional Convolutional Neural Networks (CNNs) in most vision tasks. However, existing ViTs focus on the standard accuracy and computation cost, lacking the investigation of the intrinsic influence on model robustness and generalization. In this work, we conduct systematic evaluation on components of ViTs in terms of their impact on robustness to adversarial examples, common corruptions and distribution shifts. We find some components can be harmful to robustness. By using and combining robust components as building blocks of ViTs, we propose Robust Vision Transformer (RVT), which is a new vision transformer and has superior performance with strong robustness. We further propose two new plug-and-play techniques called position-aware attention scaling and patch-wise augmentation to augment our RVT, which we abbreviate as RVT*. The experimental results on ImageNet and six robustness benchmarks show the advanced robustness and generalization ability of RVT compared with previous ViTs and state-of-the-art CNNs. Furthermore, RVT-S* also achieves Top-1 rank on multiple robustness leaderboards including ImageNet-C and ImageNet-Sketch. The code will be available at \url{https://git.io/Jswdk}.
QAIR: Practical Query-efficient Black-Box Attacks for Image Retrieval
Mar 23, 2021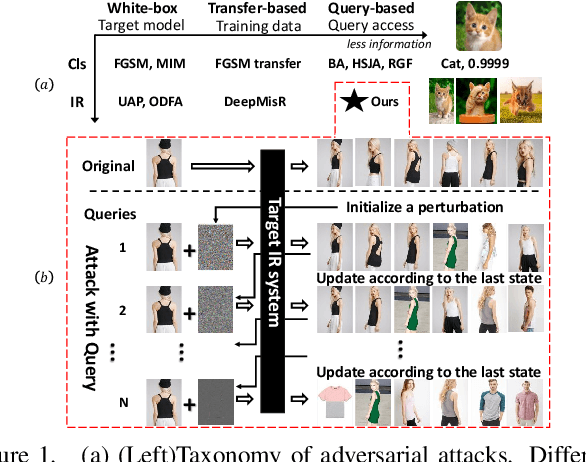
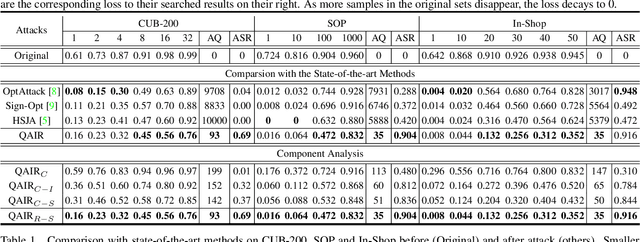
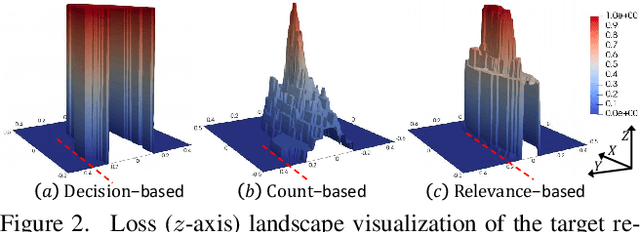
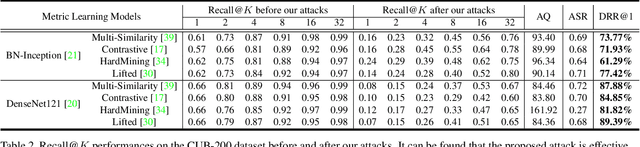
We study the query-based attack against image retrieval to evaluate its robustness against adversarial examples under the black-box setting, where the adversary only has query access to the top-k ranked unlabeled images from the database. Compared with query attacks in image classification, which produce adversaries according to the returned labels or confidence score, the challenge becomes even more prominent due to the difficulty in quantifying the attack effectiveness on the partial retrieved list. In this paper, we make the first attempt in Query-based Attack against Image Retrieval (QAIR), to completely subvert the top-k retrieval results. Specifically, a new relevance-based loss is designed to quantify the attack effects by measuring the set similarity on the top-k retrieval results before and after attacks and guide the gradient optimization. To further boost the attack efficiency, a recursive model stealing method is proposed to acquire transferable priors on the target model and generate the prior-guided gradients. Comprehensive experiments show that the proposed attack achieves a high attack success rate with few queries against the image retrieval systems under the black-box setting. The attack evaluations on the real-world visual search engine show that it successfully deceives a commercial system such as Bing Visual Search with 98% attack success rate by only 33 queries on average.
Spatial-Phase Shallow Learning: Rethinking Face Forgery Detection in Frequency Domain
Mar 10, 2021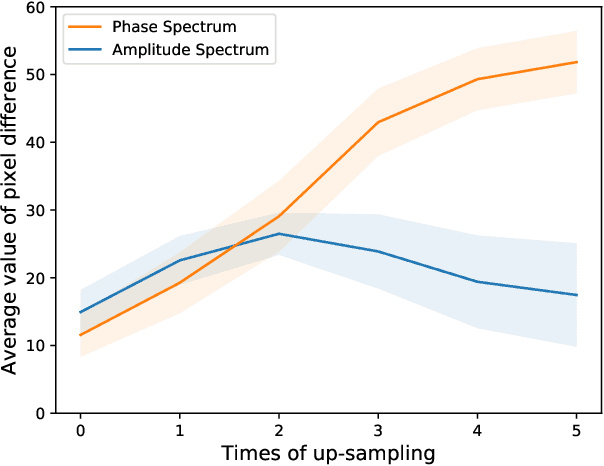
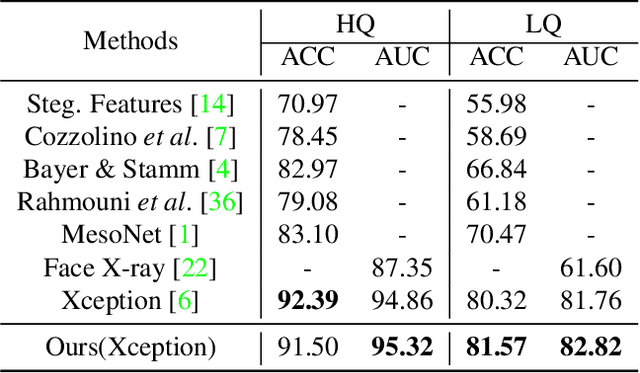
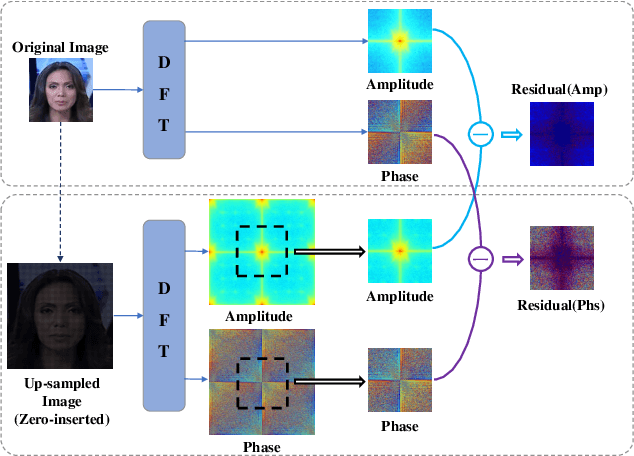
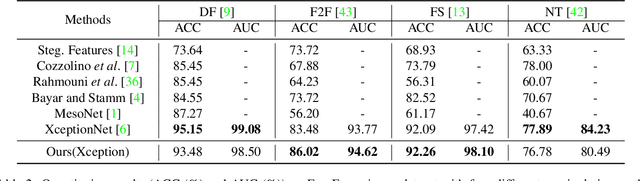
The remarkable success in face forgery techniques has received considerable attention in computer vision due to security concerns. We observe that up-sampling is a necessary step of most face forgery techniques, and cumulative up-sampling will result in obvious changes in the frequency domain, especially in the phase spectrum. According to the property of natural images, the phase spectrum preserves abundant frequency components that provide extra information and complement the loss of the amplitude spectrum. To this end, we present a novel Spatial-Phase Shallow Learning (SPSL) method, which combines spatial image and phase spectrum to capture the up-sampling artifacts of face forgery to improve the transferability, for face forgery detection. And we also theoretically analyze the validity of utilizing the phase spectrum. Moreover, we notice that local texture information is more crucial than high-level semantic information for the face forgery detection task. So we reduce the receptive fields by shallowing the network to suppress high-level features and focus on the local region. Extensive experiments show that SPSL can achieve the state-of-the-art performance on cross-datasets evaluation as well as multi-class classification and obtain comparable results on single dataset evaluation.
Sharp Multiple Instance Learning for DeepFake Video Detection
Aug 11, 2020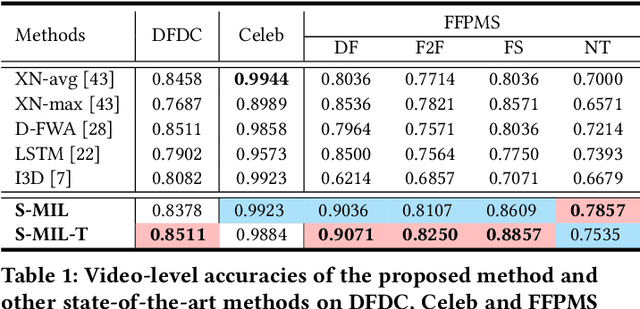
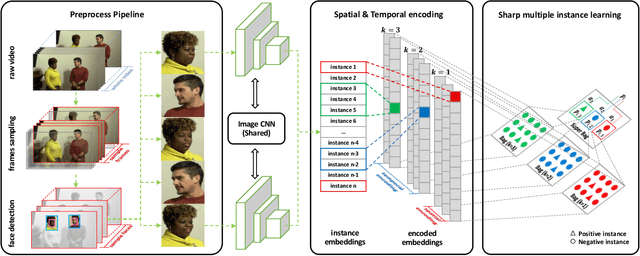
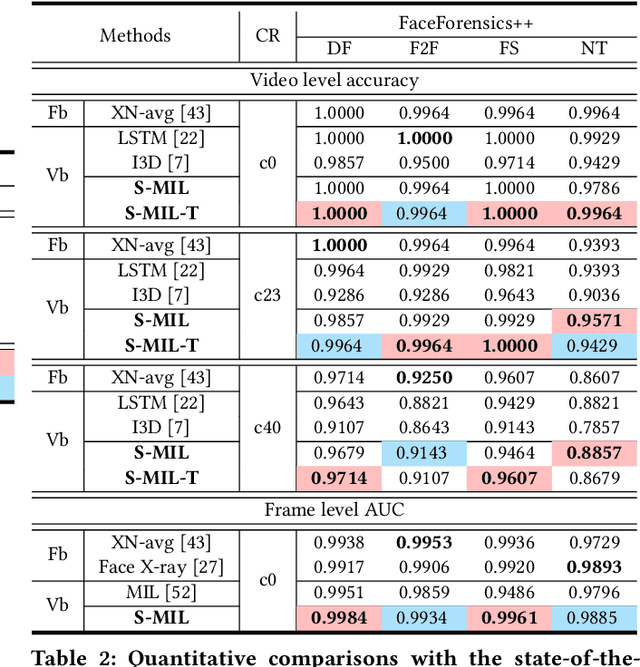

With the rapid development of facial manipulation techniques, face forgery has received considerable attention in multimedia and computer vision community due to security concerns. Existing methods are mostly designed for single-frame detection trained with precise image-level labels or for video-level prediction by only modeling the inter-frame inconsistency, leaving potential high risks for DeepFake attackers. In this paper, we introduce a new problem of partial face attack in DeepFake video, where only video-level labels are provided but not all the faces in the fake videos are manipulated. We address this problem by multiple instance learning framework, treating faces and input video as instances and bag respectively. A sharp MIL (S-MIL) is proposed which builds direct mapping from instance embeddings to bag prediction, rather than from instance embeddings to instance prediction and then to bag prediction in traditional MIL. Theoretical analysis proves that the gradient vanishing in traditional MIL is relieved in S-MIL. To generate instances that can accurately incorporate the partially manipulated faces, spatial-temporal encoded instance is designed to fully model the intra-frame and inter-frame inconsistency, which further helps to promote the detection performance. We also construct a new dataset FFPMS for partially attacked DeepFake video detection, which can benefit the evaluation of different methods at both frame and video levels. Experiments on FFPMS and the widely used DFDC dataset verify that S-MIL is superior to other counterparts for partially attacked DeepFake video detection. In addition, S-MIL can also be adapted to traditional DeepFake image detection tasks and achieve state-of-the-art performance on single-frame datasets.
* Accepted at ACM MM 2020. 11 pages, 8 figures, with appendix
AdvKnn: Adversarial Attacks On K-Nearest Neighbor Classifiers With Approximate Gradients
Nov 29, 2019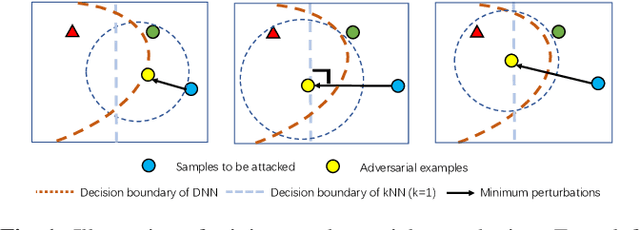
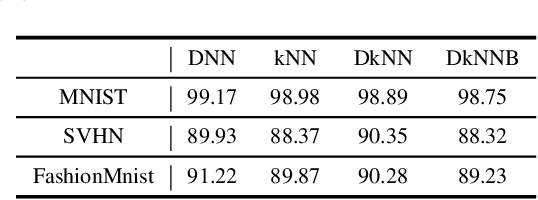
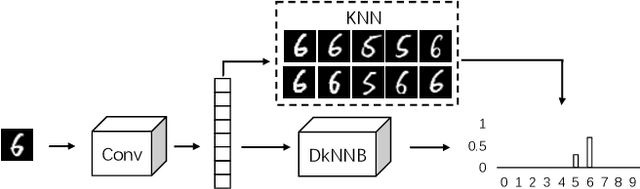
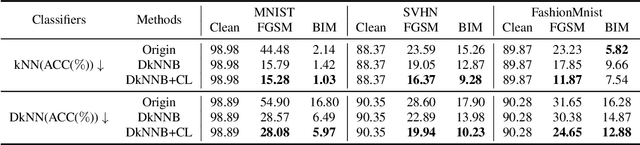
Deep neural networks have been shown to be vulnerable to adversarial examples---maliciously crafted examples that can trigger the target model to misbehave by adding imperceptible perturbations. Existing attack methods for k-nearest neighbor~(kNN) based algorithms either require large perturbations or are not applicable for large k. To handle this problem, this paper proposes a new method called AdvKNN for evaluating the adversarial robustness of kNN-based models. Firstly, we propose a deep kNN block to approximate the output of kNN methods, which is differentiable thus can provide gradients for attacks to cross the decision boundary with small distortions. Second, a new consistency learning for distribution instead of classification is proposed for the effectiveness in distribution based methods. Extensive experimental results indicate that the proposed method significantly outperforms state of the art in terms of attack success rate and the added perturbations.
A Deep Belief Network Based Machine Learning System for Risky Host Detection
Dec 29, 2017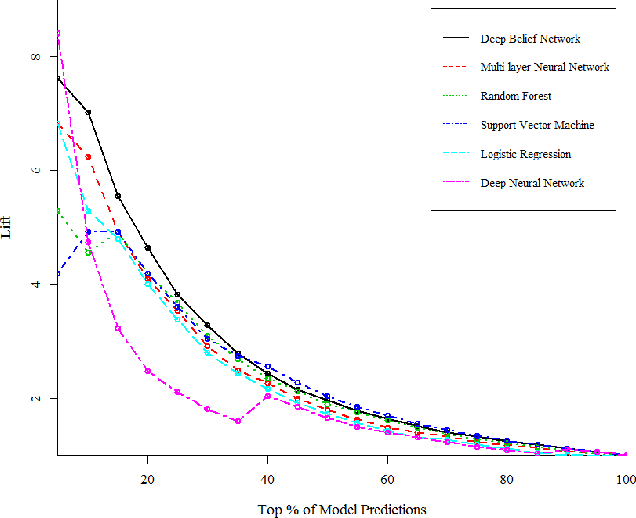
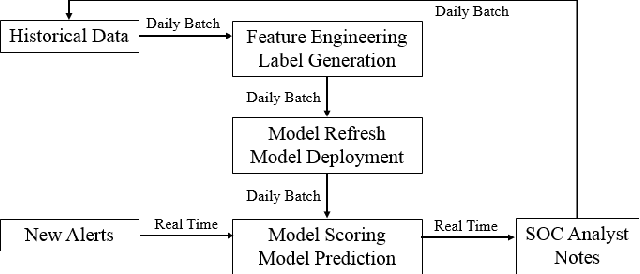
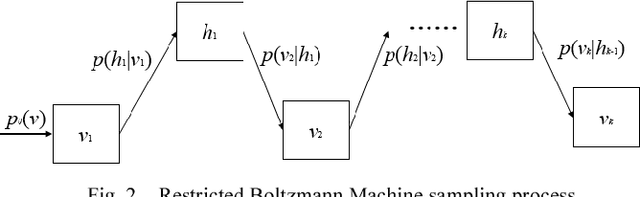
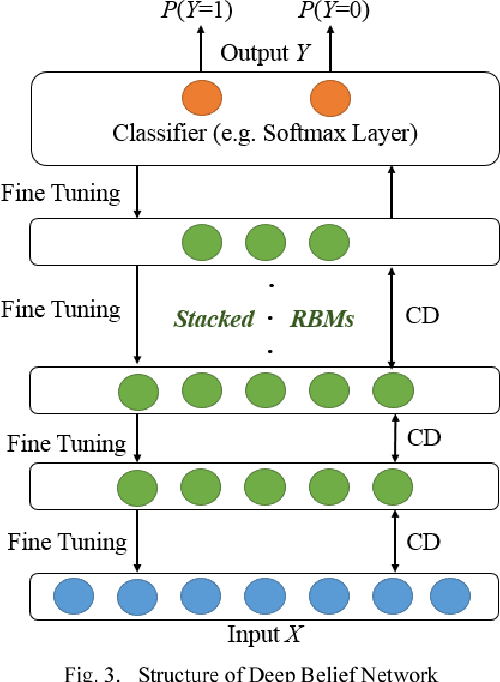
To assure cyber security of an enterprise, typically SIEM (Security Information and Event Management) system is in place to normalize security event from different preventive technologies and flag alerts. Analysts in the security operation center (SOC) investigate the alerts to decide if it is truly malicious or not. However, generally the number of alerts is overwhelming with majority of them being false positive and exceeding the SOC's capacity to handle all alerts. There is a great need to reduce the false positive rate as much as possible. While most previous research focused on network intrusion detection, we focus on risk detection and propose an intelligent Deep Belief Network machine learning system. The system leverages alert information, various security logs and analysts' investigation results in a real enterprise environment to flag hosts that have high likelihood of being compromised. Text mining and graph based method are used to generate targets and create features for machine learning. In the experiment, Deep Belief Network is compared with other machine learning algorithms, including multi-layer neural network, random forest, support vector machine and logistic regression. Results on real enterprise data indicate that the deep belief network machine learning system performs better than other algorithms for our problem and is six times more effective than current rule-based system. We also implement the whole system from data collection, label creation, feature engineering to host score generation in a real enterprise production environment.