 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisit Batch Normalization: New Understanding from an Optimization View and a Refinement via Composition Optimization
Oct 15, 2018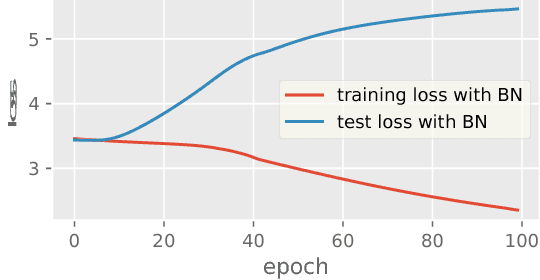
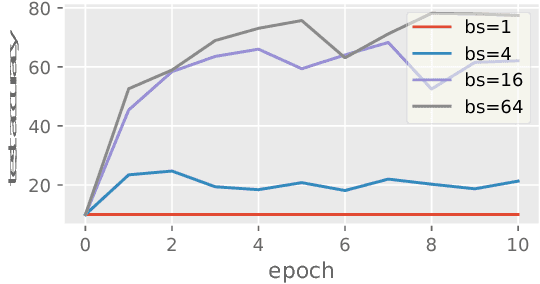
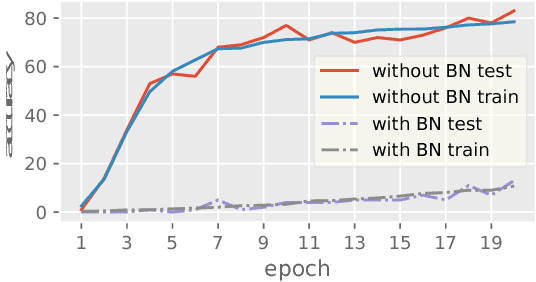
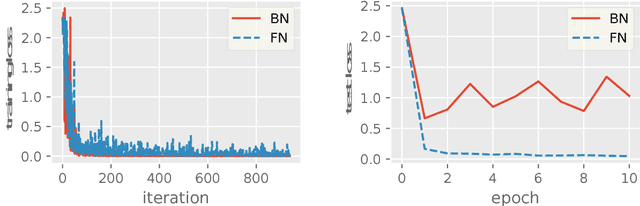
Batch Normalization (BN) has been used extensively in deep learning to achieve faster training process and better resulting models. However, whether BN works strongly depends on how the batches are constructed during training and it may not converge to a desired solution if the statistics on a batch are not close to the statistics over the whole dataset. In this paper, we try to understand BN from an optimization perspective by formulating the optimization problem which motivates BN. We show when BN works and when BN does not work by analyzing the optimization problem. We then propose a refinement of BN based on compositional optimization techniques called Full Normalization (FN) to alleviate the issues of BN when the batches are not constructed ideally. We provide convergence analysis for FN and empirically study its effectiveness to refine BN.
Asynchronous Decentralized Parallel Stochastic Gradient Descent
Sep 25, 2018
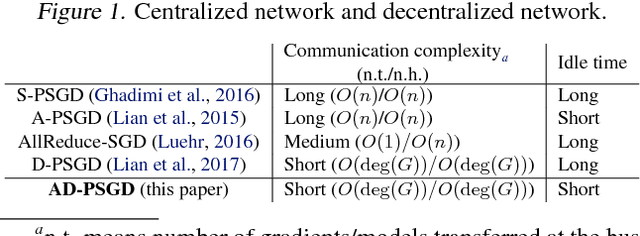
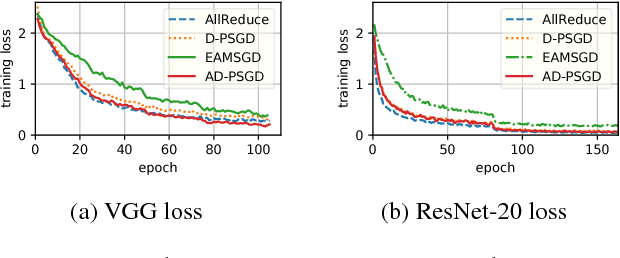
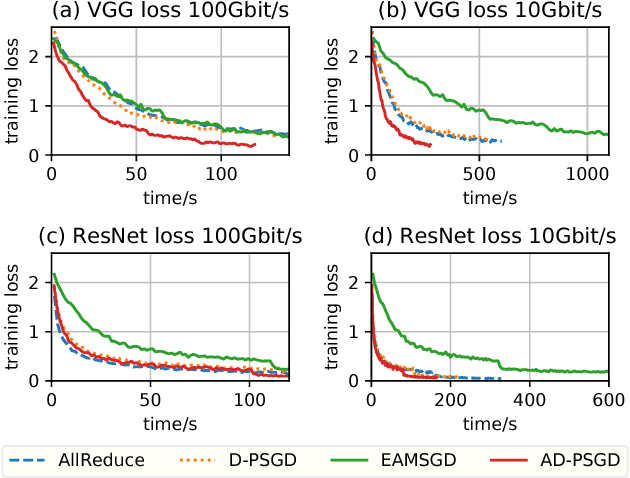
Most commonly used distributed machine learning systems are either synchronous or centralized asynchronous. Synchronous algorithms like AllReduce-SGD perform poorly in a heterogeneous environment, while asynchronous algorithms using a parameter server suffer from 1) communication bottleneck at parameter servers when workers are many, and 2) significantly worse convergence when the traffic to parameter server is congested. Can we design an algorithm that is robust in a heterogeneous environment, while being communication efficient and maintaining the best-possible convergence rate? In this paper, we propose an asynchronous decentralized stochastic gradient decent algorithm (AD-PSGD) satisfying all above expectations. Our theoretical analysis shows AD-PSGD converges at the optimal $O(1/\sqrt{K})$ rate as SGD and has linear speedup w.r.t. number of workers. Empirically, AD-PSGD outperforms the best of decentralized parallel SGD (D-PSGD), asynchronous parallel SGD (A-PSGD), and standard data parallel SGD (AllReduce-SGD), often by orders of magnitude in a heterogeneous environment. When training ResNet-50 on ImageNet with up to 128 GPUs, AD-PSGD converges (w.r.t epochs) similarly to the AllReduce-SGD, but each epoch can be up to 4-8X faster than its synchronous counterparts in a network-sharing HPC environment. To the best of our knowledge, AD-PSGD is the first asynchronous algorithm that achieves a similar epoch-wise convergence rate as AllReduce-SGD, at an over 100-GPU scale.
D$^2$: Decentralized Training over Decentralized Data
Apr 20, 2018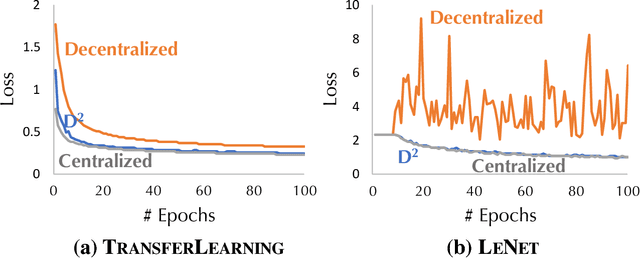
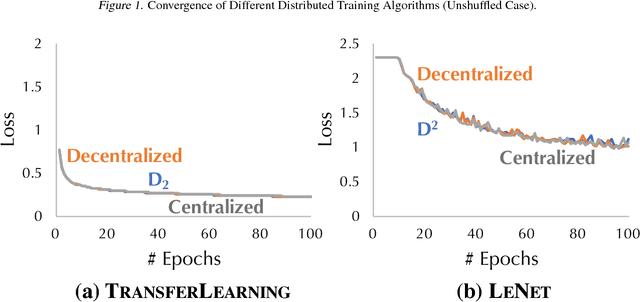
While training a machine learning model using multiple workers, each of which collects data from their own data sources, it would be most useful when the data collected from different workers can be {\em unique} and {\em different}. Ironically, recent analysis of decentralized parallel stochastic gradient descent (D-PSGD) relies on the assumption that the data hosted on different workers are {\em not too different}. In this paper, we ask the question: {\em Can we design a decentralized parallel stochastic gradient descent algorithm that is less sensitive to the data variance across workers?} In this paper, we present D$^2$, a novel decentralized parallel stochastic gradient descent algorithm designed for large data variance \xr{among workers} (imprecisely, "decentralized" data). The core of D$^2$ is a variance blackuction extension of the standard D-PSGD algorithm, which improves the convergence rate from $O\left({\sigma \over \sqrt{nT}} + {(n\zeta^2)^{\frac{1}{3}} \over T^{2/3}}\right)$ to $O\left({\sigma \over \sqrt{nT}}\right)$ where $\zeta^{2}$ denotes the variance among data on different workers. As a result, D$^2$ is robust to data variance among workers. We empirically evaluated D$^2$ on image classification tasks where each worker has access to only the data of a limited set of labels, and find that D$^2$ significantly outperforms D-PSGD.
Can Decentralized Algorithms Outperform Centralized Algorithms? A Case Study for Decentralized Parallel Stochastic Gradient Descent
Sep 11, 2017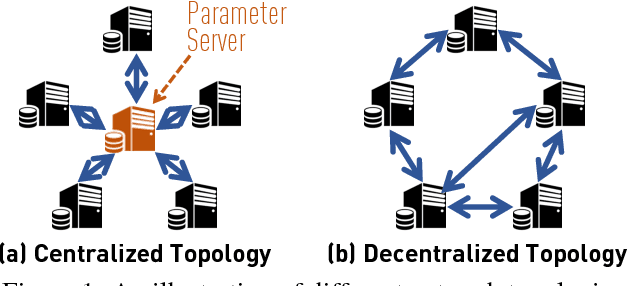
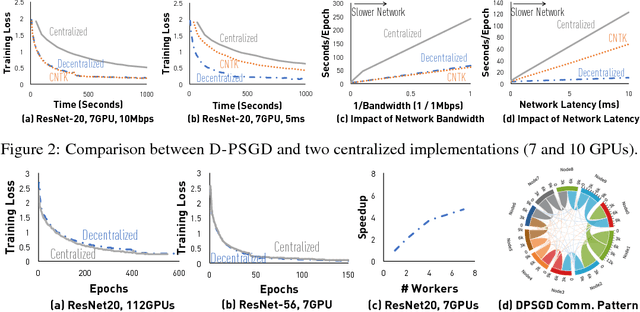
Most distributed machine learning systems nowadays, including TensorFlow and CNTK, are built in a centralized fashion. One bottleneck of centralized algorithms lies on high communication cost on the central node. Motivated by this, we ask, can decentralized algorithms be faster than its centralized counterpart? Although decentralized PSGD (D-PSGD) algorithms have been studied by the control community, existing analysis and theory do not show any advantage over centralized PSGD (C-PSGD) algorithms, simply assuming the application scenario where only the decentralized network is available. In this paper, we study a D-PSGD algorithm and provide the first theoretical analysis that indicates a regime in which decentralized algorithms might outperform centralized algorithms for distributed stochastic gradient descent. This is because D-PSGD has comparable total computational complexities to C-PSGD but requires much less communication cost on the busiest node. We further conduct an empirical study to validate our theoretical analysis across multiple frameworks (CNTK and Torch), different network configurations, and computation platforms up to 112 GPUs. On network configurations with low bandwidth or high latency, D-PSGD can be up to one order of magnitude faster than its well-optimized centralized counterparts.
Asynchronous Parallel Stochastic Gradient for Nonconvex Optimization
Jun 10, 2017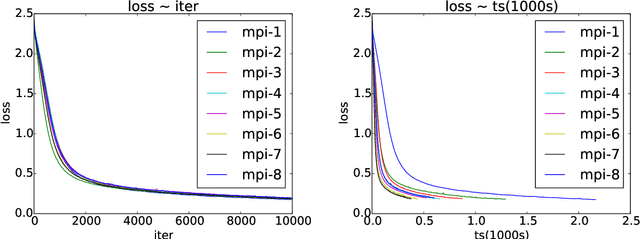

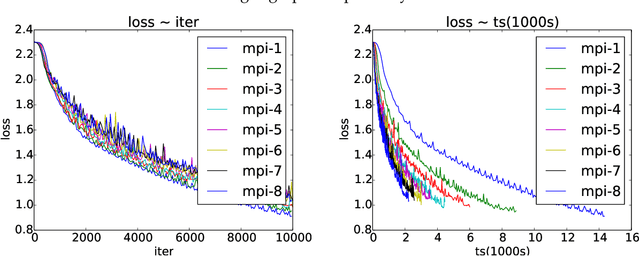

Asynchronous parallel implementations of stochastic gradient (SG) have been broadly used in solving deep neural network and received many successes in practice recently. However, existing theories cannot explain their convergence and speedup properties, mainly due to the nonconvexity of most deep learning formulations and the asynchronous parallel mechanism. To fill the gaps in theory and provide theoretical supports, this paper studies two asynchronous parallel implementations of SG: one is on the computer network and the other is on the shared memory system. We establish an ergodic convergence rate $O(1/\sqrt{K})$ for both algorithms and prove that the linear speedup is achievable if the number of workers is bounded by $\sqrt{K}$ ($K$ is the total number of iterations). Our results generalize and improve existing analysis for convex minimization.
Staleness-aware Async-SGD for Distributed Deep Learning
Apr 05, 2016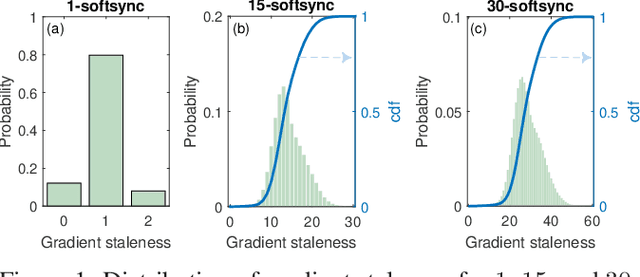
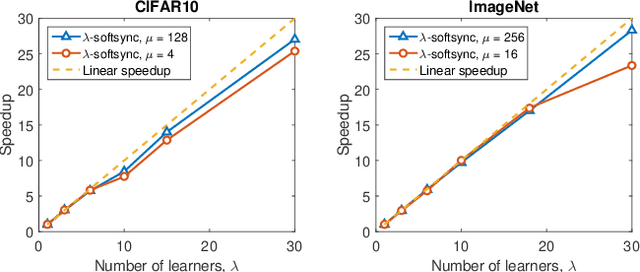
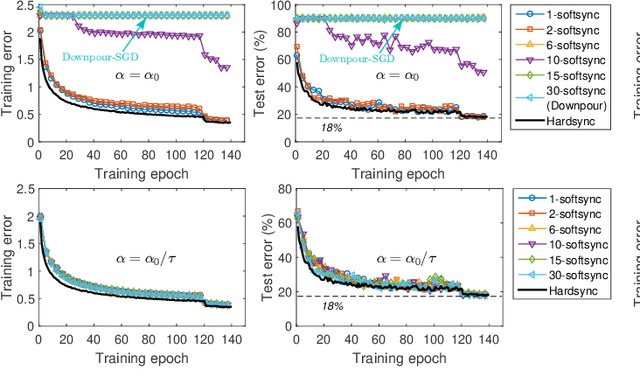
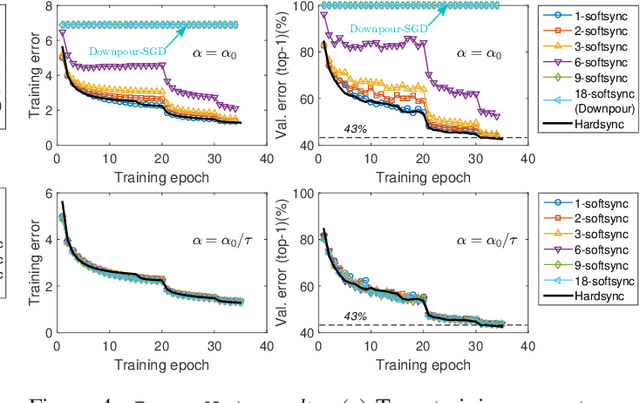
Deep neural networks have been shown to achieve state-of-the-art performance in several machine learning tasks. Stochastic Gradient Descent (SGD) is the preferred optimization algorithm for training these networks and asynchronous SGD (ASGD) has been widely adopted for accelerating the training of large-scale deep networks in a distributed computing environment. However, in practice it is quite challenging to tune the training hyperparameters (such as learning rate) when using ASGD so as achieve convergence and linear speedup, since the stability of the optimization algorithm is strongly influenced by the asynchronous nature of parameter updates. In this paper, we propose a variant of the ASGD algorithm in which the learning rate is modulated according to the gradient staleness and provide theoretical guarantees for convergence of this algorithm. Experimental verification is performed on commonly-used image classification benchmarks: CIFAR10 and Imagenet to demonstrate the superior effectiveness of the proposed approach, compared to SSGD (Synchronous SGD) and the conventional ASGD algorithm.