 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLAS: Metric Learning on Attributed Sequences
Nov 08, 2020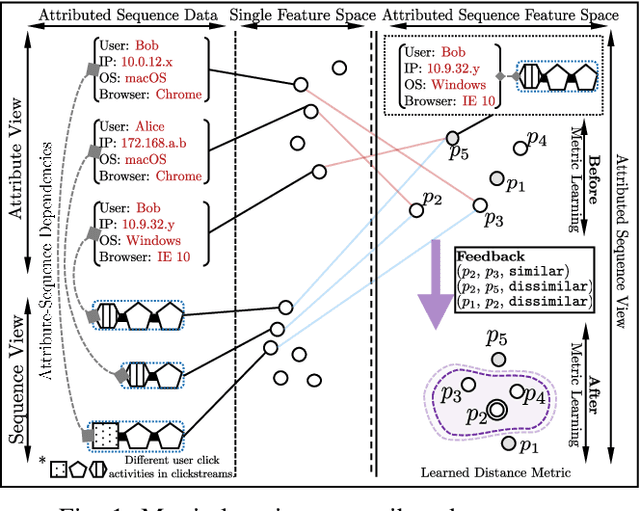
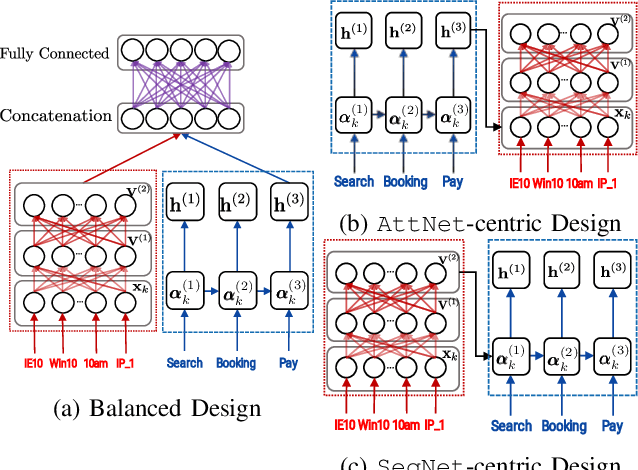
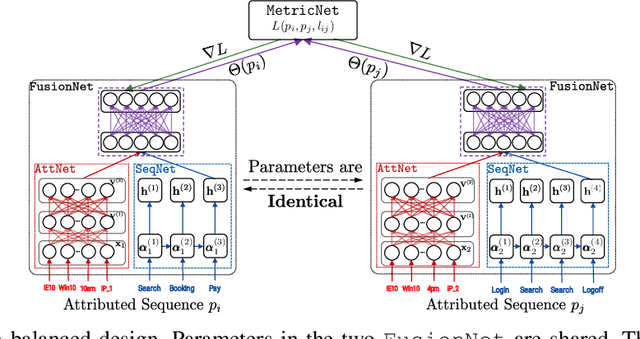

Distance metric learning has attracted much attention in recent years, where the goal is to learn a distance metric based on user feedback. Conventional approaches to metric learning mainly focus on learning the Mahalanobis distance metric on data attributes. Recent research on metric learning has been extended to sequential data, where we only have structural information in the sequences, but no attribute is available. However, real-world applications often involve attributed sequence data (e.g., clickstreams), where each instance consists of not only a set of attributes (e.g., user session context) but also a sequence of categorical items (e.g., user actions). In this paper, we study the problem of metric learning on attributed sequences. Unlike previous work on metric learning, we now need to go beyond the Mahalanobis distance metric in the attribute feature space while also incorporating the structural information in sequences. We propose a deep learning framework, called MLAS (Metric Learning on Attributed Sequences), to learn a distance metric that effectively measures dissimilarities between attributed sequences. Empirical results on real-world datasets demonstrate that the proposed MLAS framework significantly improves the performance of metric learning compared to state-of-the-art methods on attributed sequences.
Attributed Sequence Embedding
Nov 03, 2019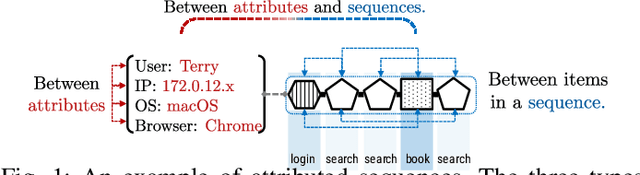
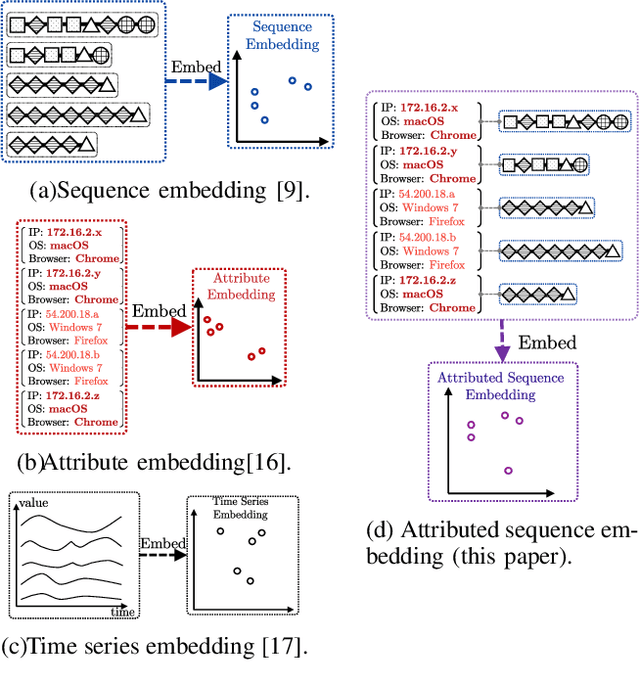
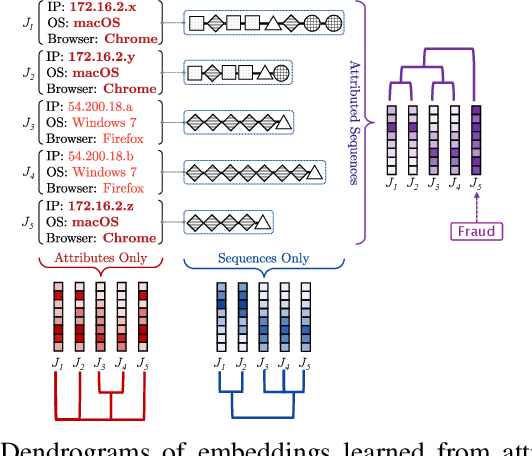
Mining tasks over sequential data, such as clickstreams and gene sequences, require a careful design of embeddings usable by learning algorithms. Recent research in feature learning has been extended to sequential data, where each instance consists of a sequence of heterogeneous items with a variable length. However, many real-world applications often involve attributed sequences, where each instance is composed of both a sequence of categorical items and a set of attributes. In this paper, we study this new problem of attributed sequence embedding, where the goal is to learn the representations of attributed sequences in an unsupervised fashion. This problem is core to many important data mining tasks ranging from user behavior analysis to the clustering of gene sequences. This problem is challenging due to the dependencies between sequences and their associated attributes. We propose a deep multimodal learning framework, called NAS, to produce embeddings of attributed sequences. The embeddings are task independent and can be used on various mining tasks of attributed sequences. We demonstrate the effectiveness of our embeddings of attributed sequences in various unsupervised learning tasks on real-world datasets.
Signed Distance-based Deep Memory Recommender
May 01, 2019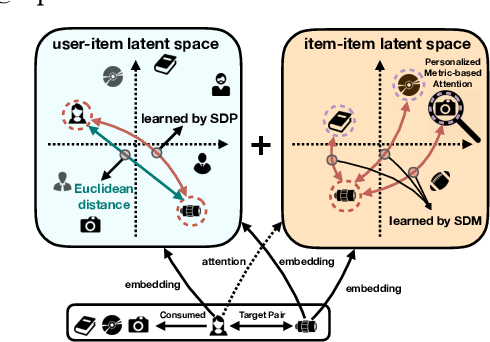
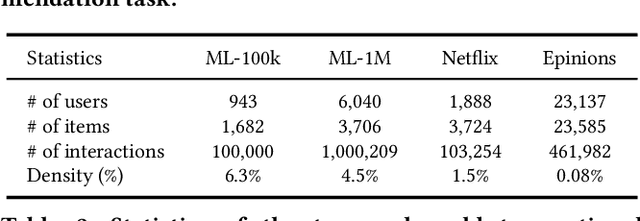

Personalized recommendation algorithms learn a user's preference for an item by measuring a distance/similarity between them. However, some of the existing recommendation models (e.g., matrix factorization) assume a linear relationship between the user and item. This approach limits the capacity of recommender systems, since the interactions between users and items in real-world applications are much more complex than the linear relationship. To overcome this limitation, in this paper, we design and propose a deep learning framework called Signed Distance-based Deep Memory Recommender, which captures non-linear relationships between users and items explicitly and implicitly, and work well in both general recommendation task and shopping basket-based recommendation task. Through an extensive empirical study on six real-world datasets in the two recommendation tasks, our proposed approach achieved significant improvement over ten state-of-the-art recommendation models.
Higher-order Graph Convolutional Networks
Sep 12, 2018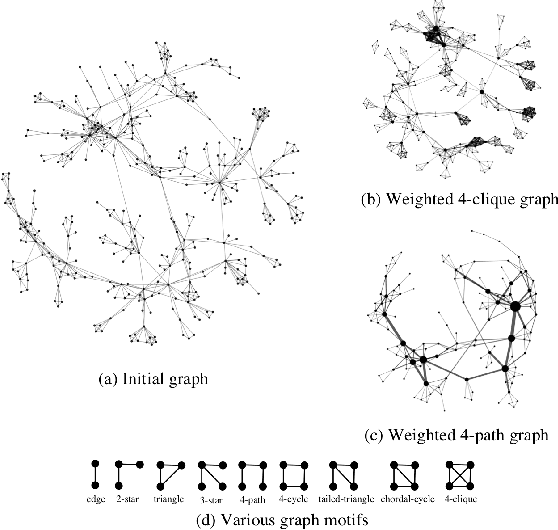

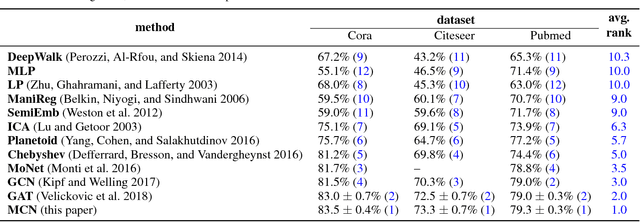
Following the success of deep convolutional networks in various vision and speech related tasks, researchers have started investigating generalizations of the well-known technique for graph-structured data. A recently-proposed method called Graph Convolutional Networks has been able to achieve state-of-the-art results in the task of node classification. However, since the proposed method relies on localized first-order approximations of spectral graph convolutions, it is unable to capture higher-order interactions between nodes in the graph. In this work, we propose a motif-based graph attention model, called Motif Convolutional Networks (MCNs), which generalizes past approaches by using weighted multi-hop motif adjacency matrices to capture higher-order neighborhoods. A novel attention mechanism is used to allow each individual node to select the most relevant neighborhood to apply its filter. Experiments show that our proposed method is able to achieve state-of-the-art results on the semi-supervised node classification task.
TreeGAN: Syntax-Aware Sequence Generation with Generative Adversarial Networks
Aug 22, 2018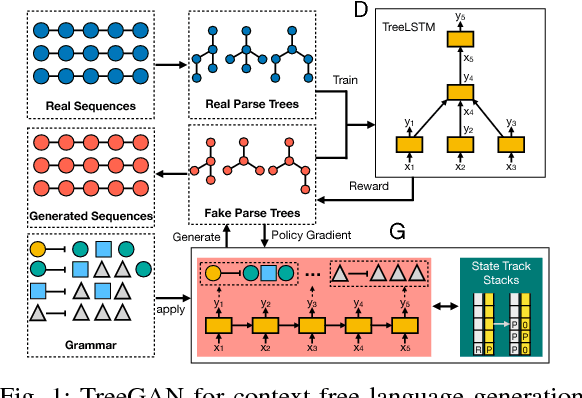
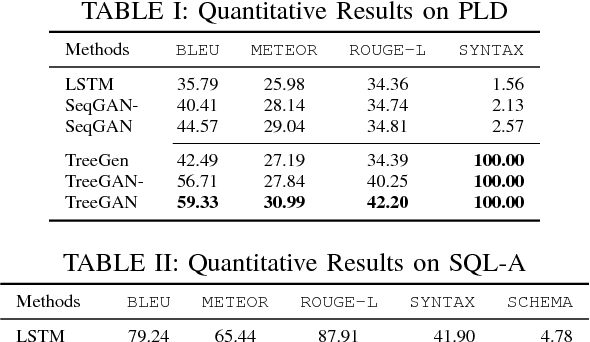
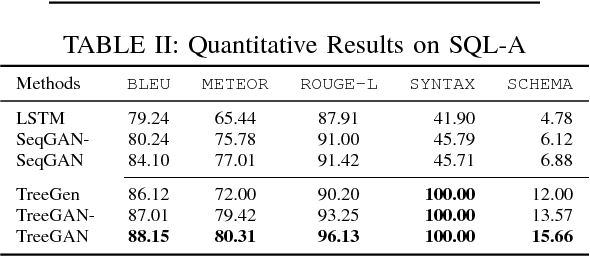
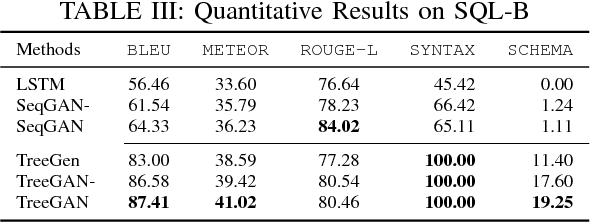
Generative Adversarial Networks (GANs) have shown great capacity on image generation, in which a discriminative model guides the training of a generative model to construct images that resemble real images. Recently, GANs have been extended from generating images to generating sequences (e.g., poems, music and codes). Existing GANs on sequence generation mainly focus on general sequences, which are grammar-free. In many real-world applications, however, we need to generate sequences in a formal language with the constraint of its corresponding grammar. For example, to test the performance of a database, one may want to generate a collection of SQL queries, which are not only similar to the queries of real users, but also follow the SQL syntax of the target database. Generating such sequences is highly challenging because both the generator and discriminator of GANs need to consider the structure of the sequences and the given grammar in the formal language. To address these issues, we study the problem of syntax-aware sequence generation with GANs, in which a collection of real sequences and a set of pre-defined grammatical rules are given to both discriminator and generator. We propose a novel GAN framework, namely TreeGAN, to incorporate a given Context-Free Grammar (CFG) into the sequence generation process. In TreeGAN, the generator employs a recurrent neural network (RNN) to construct a parse tree. Each generated parse tree can then be translated to a valid sequence of the given grammar. The discriminator uses a tree-structured RNN to distinguish the generated trees from real trees. We show that TreeGAN can generate sequences for any CFG and its generation fully conforms with the given syntax. Experiments on synthetic and real data sets demonstrated that TreeGAN significantly improves the quality of the sequence generation in context-free languages.
Learning Role-based Graph Embeddings
Jul 02, 2018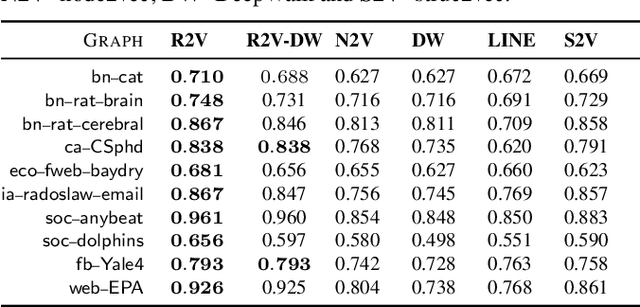
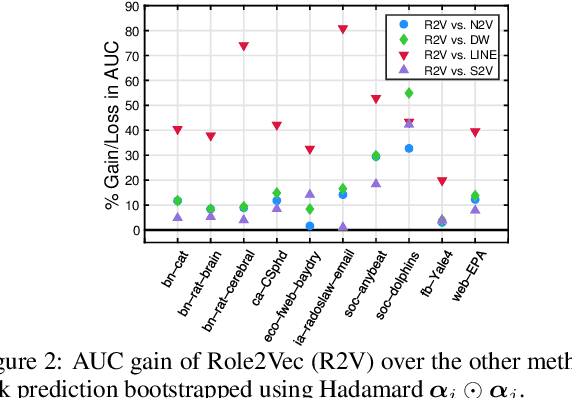
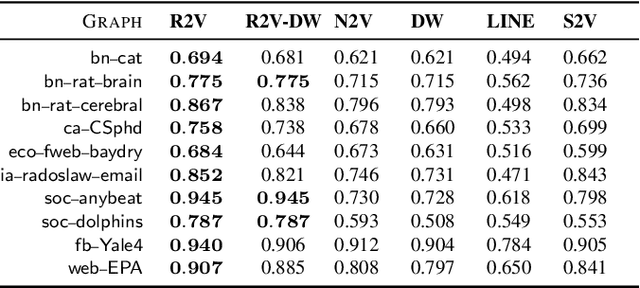
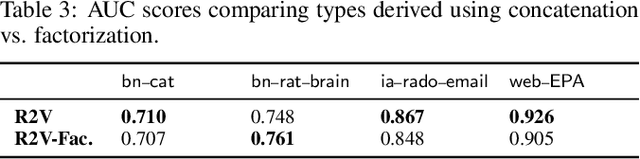
Random walks are at the heart of many existing network embedding methods. However, such algorithms have many limitations that arise from the use of random walks, e.g., the features resulting from these methods are unable to transfer to new nodes and graphs as they are tied to vertex identity. In this work, we introduce the Role2Vec framework which uses the flexible notion of attributed random walks, and serves as a basis for generalizing existing methods such as DeepWalk, node2vec, and many others that leverage random walks. Our proposed framework enables these methods to be more widely applicable for both transductive and inductive learning as well as for use on graphs with attributes (if available). This is achieved by learning functions that generalize to new nodes and graphs. We show that our proposed framework is effective with an average AUC improvement of 16.55% while requiring on average 853x less space than existing methods on a variety of graphs.
Inductive Representation Learning in Large Attributed Graphs
Nov 22, 2017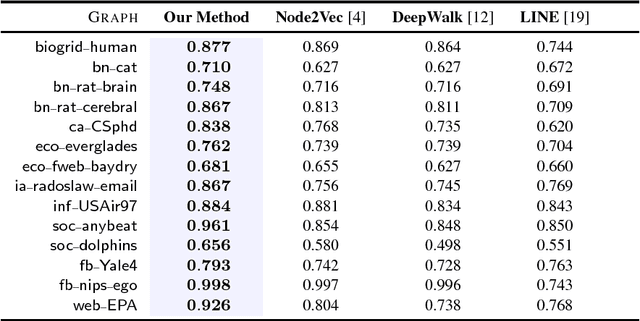
Graphs (networks) are ubiquitous and allow us to model entities (nodes) and the dependencies (edges) between them. Learning a useful feature representation from graph data lies at the heart and success of many machine learning tasks such as classification, anomaly detection, link prediction, among many others. Many existing techniques use random walks as a basis for learning features or estimating the parameters of a graph model for a downstream prediction task. Examples include recent node embedding methods such as DeepWalk, node2vec, as well as graph-based deep learning algorithms. However, the simple random walk used by these methods is fundamentally tied to the identity of the node. This has three main disadvantages. First, these approaches are inherently transductive and do not generalize to unseen nodes and other graphs. Second, they are not space-efficient as a feature vector is learned for each node which is impractical for large graphs. Third, most of these approaches lack support for attributed graphs. To make these methods more generally applicable, we propose a framework for inductive network representation learning based on the notion of attributed random walk that is not tied to node identity and is instead based on learning a function $\Phi : \mathrm{\rm \bf x} \rightarrow w$ that maps a node attribute vector $\mathrm{\rm \bf x}$ to a type $w$. This framework serves as a basis for generalizing existing methods such as DeepWalk, node2vec, and many other previous methods that leverage traditional random walks.
Deep Graph Attention Model
Sep 15, 2017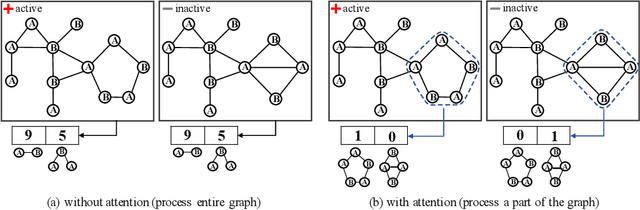
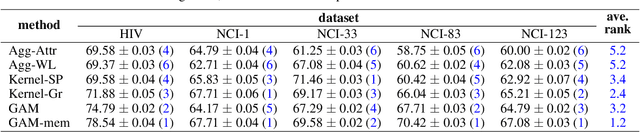
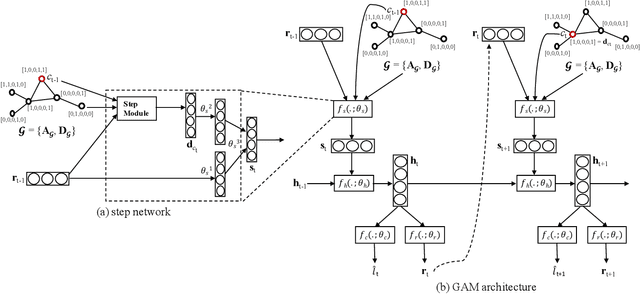

Graph classification is a problem with practical applications in many different domains. Most of the existing methods take the entire graph into account when calculating graph features. In a graphlet-based approach, for instance, the entire graph is processed to get the total count of different graphlets or sub-graphs. In the real-world, however, graphs can be both large and noisy with discriminative patterns confined to certain regions in the graph only. In this work, we study the problem of attentional processing for graph classification. The use of attention allows us to focus on small but informative parts of the graph, avoiding noise in the rest of the graph. We present a novel RNN model, called the Graph Attention Model (GAM), that processes only a portion of the graph by adaptively selecting a sequence of "interesting" nodes. The model is equipped with an external memory component which allows it to integrate information gathered from different parts of the graph. We demonstrate the effectiveness of the model through various experiments.
A Framework for Generalizing Graph-based Representation Learning Methods
Sep 14, 2017
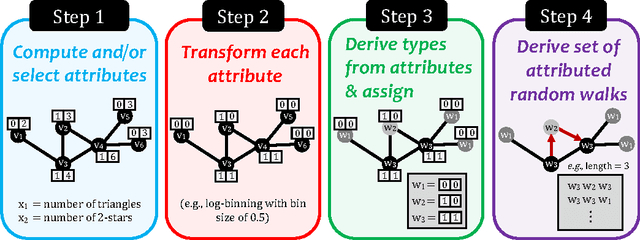
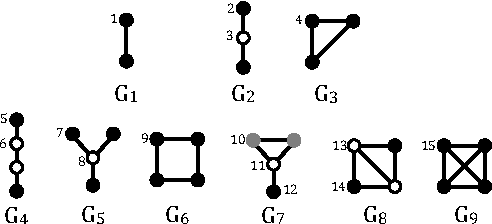
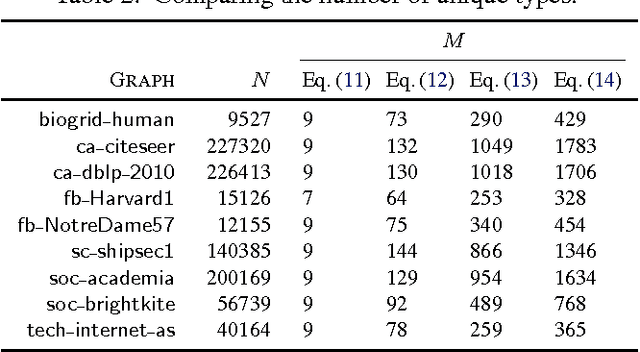
Random walks are at the heart of many existing deep learning algorithms for graph data. However, such algorithms have many limitations that arise from the use of random walks, e.g., the features resulting from these methods are unable to transfer to new nodes and graphs as they are tied to node identity. In this work, we introduce the notion of attributed random walks which serves as a basis for generalizing existing methods such as DeepWalk, node2vec, and many others that leverage random walks. Our proposed framework enables these methods to be more widely applicable for both transductive and inductive learning as well as for use on graphs with attributes (if available). This is achieved by learning functions that generalize to new nodes and graphs. We show that our proposed framework is effective with an average AUC improvement of 16.1% while requiring on average 853 times less space than existing methods on a variety of graphs from several domains.
Mining Brain Networks using Multiple Side Views for Neurological Disorder Identification
Aug 19, 2015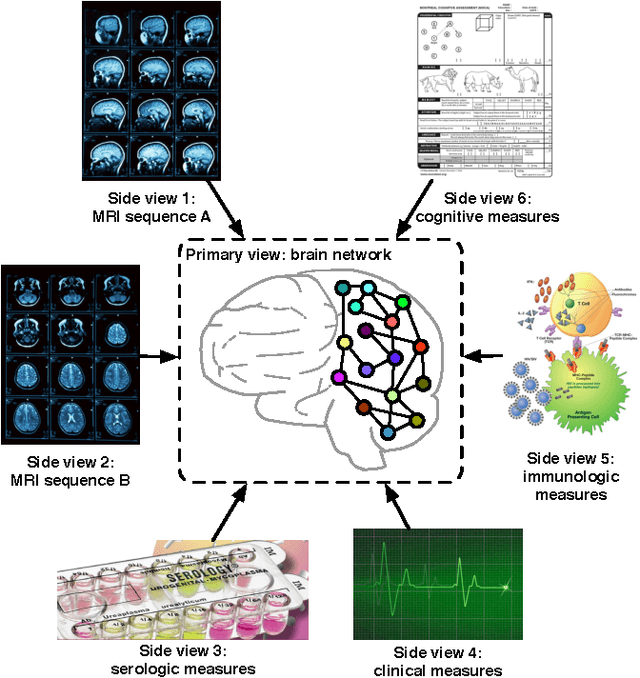
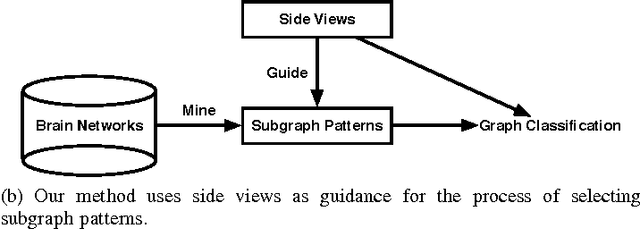
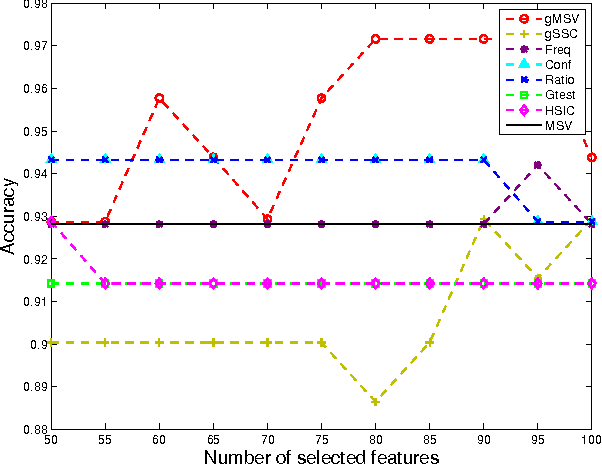
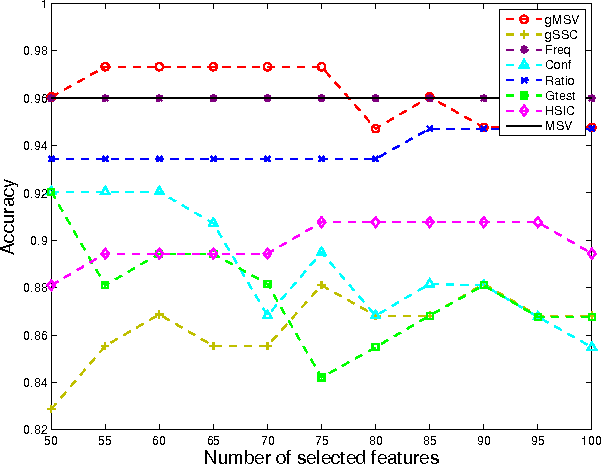
Mining discriminative subgraph patterns from graph data has attracted great interest in recent years. It has a wide variety of applications in disease diagnosis, neuroimaging, etc. Most research on subgraph mining focuses on the graph representation alone. However, in many real-world applications, the side information is available along with the graph data. For example, for neurological disorder identification, in addition to the brain networks derived from neuroimaging data, hundreds of clinical, immunologic, serologic and cognitive measures may also be documented for each subject. These measures compose multiple side views encoding a tremendous amount of supplemental information for diagnostic purposes, yet are often ignored. In this paper, we study the problem of discriminative subgraph selection using multiple side views and propose a novel solution to find an optimal set of subgraph features for graph classification by exploring a plurality of side views. We derive a feature evaluation criterion, named gSide, to estimate the usefulness of subgraph patterns based upon side views. Then we develop a branch-and-bound algorithm, called gMSV, to efficiently search for optimal subgraph features by integrating the subgraph mining process and the procedure of discriminative feature selection. Empirical studies on graph classification tasks for neurological disorders using brain networks demonstrate that subgraph patterns selected by the multi-side-view guided subgraph selection approach can effectively boost graph classification performances and are relevant to disease diagnosis.