 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Motion Primitives: Behavioral Activity Recognition from Head-Mounted IMU
May 26, 2026AR smart glasses need continuous behavioral context to offer proactive assistance, yet their most practical always-on sensor, the head-mounted Inertial Measurement Unit (IMU), detects only motion primitives such as walking or standing. We push beyond motion primitives to behavioral-level recognition, defining five categories that balance AR application need with sensor observability. To this end, we construct a 160K-sample Ego4D dataset with a four-tier quality assurance framework spanning 8 activity scenarios, and propose HiT-HAR, a 703K-parameter hierarchical model that outperforms prior head-mounted IMU models on five-class action and eight-class scenario recognition. We further map the observability frontier of head-mounted IMU through per-class separability analysis, identifying which behavioral categories are reliably observable (Locomotion), which benefit from temporal context (Object Transfer, Task Operation), and where scenario-dependent signal overlap poses remaining challenges. Our results indicate that architectural choices exploiting temporal context and scenario structure outperform simply scaling model size. The code and dataset are publicly available at https://github.com/Harvard-AI-and-Robotics-Lab/HiT-HAR.
Fair Benchmarking of Emerging One-Step Generative Models Against Multistep Diffusion and Flow Models
Mar 15, 2026State-of-the-art text-to-image models produce high-quality images, but inference remains expensive as generation requires several sequential ODE or denoising steps. Native one-step models aim to reduce this cost by mapping noise to an image in a single step, yet fair comparisons to multi-step systems are difficult because studies use mismatched sampling steps and different classifier-free guidance (CFG) settings, where CFG can shift FID, Inception Score, and CLIP-based alignment in opposing directions. It is also unclear how well one-step models scale to multi-step inference, and there is limited standardized out-of-distribution evaluation for label-ID-conditioned generators beyond ImageNet. To address this, We benchmark eight models spanning one-step flows (MeanFlow, Improved MeanFlow, SoFlow), multi-step baselines (RAE, Scale-RAE), and established systems (SiT, Stable Diffusion 3.5, FLUX.1) under a controlled class-conditional protocol on ImageNet validation, ImageNetV2, and reLAIONet, our new proofread out-of-distribution dataset aligned to ImageNet label IDs. Using FID, Inception Score, CLIP Score, and Pick Score, we show that FID-focused model development and CFG selection can be misleading in few-step regimes, where guidance changes can improve FID while degrading text-image alignment and human preference signals and worsening perceived quality. We further show that leading one-step models benefit from step scaling and become substantially more competitive under multi-step inference, although they still exhibit characteristic local distortions. To capture these tradeoffs, we introduce MinMax Harmonic Mean (MMHM), a composite proxy over all four metrics that stabilizes hyperparameter selection across guidance and step sweeps.
Document Layout Analysis via Dynamic Residual Feature Fusion
Apr 07, 2021
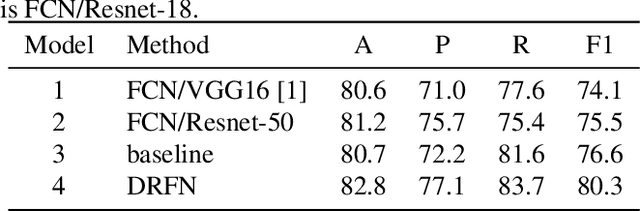
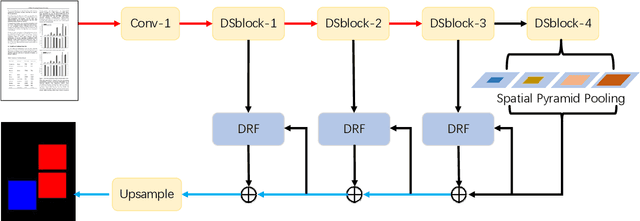
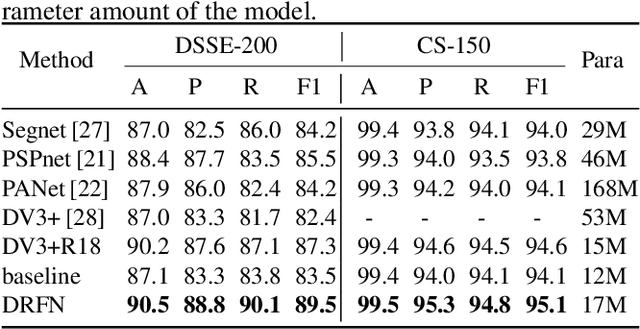
The document layout analysis (DLA) aims to split the document image into different interest regions and understand the role of each region, which has wide application such as optical character recognition (OCR) systems and document retrieval. However, it is a challenge to build a DLA system because the training data is very limited and lacks an efficient model. In this paper, we propose an end-to-end united network named Dynamic Residual Fusion Network (DRFN) for the DLA task. Specifically, we design a dynamic residual feature fusion module which can fully utilize low-dimensional information and maintain high-dimensional category information. Besides, to deal with the model overfitting problem that is caused by lacking enough data, we propose the dynamic select mechanism for efficient fine-tuning in limited train data. We experiment with two challenging datasets and demonstrate the effectiveness of the proposed module.
* 7 pages, 6 figures