 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCornerFormer: Boosting Corner Representation for Fine-Grained Structured Reconstruction
Apr 22, 2023Structured reconstruction is a non-trivial dense prediction problem, which extracts structural information (\eg, building corners and edges) from a raster image, then reconstructs it to a 2D planar graph accordingly. Compared with common segmentation or detection problems, it significantly relays on the capability that leveraging holistic geometric information for structural reasoning. Current transformer-based approaches tackle this challenging problem in a two-stage manner, which detect corners in the first model and classify the proposed edges (corner-pairs) in the second model. However, they separate two-stage into different models and only share the backbone encoder. Unlike the existing modeling strategies, we present an enhanced corner representation method: 1) It fuses knowledge between the corner detection and edge prediction by sharing feature in different granularity; 2) Corner candidates are proposed in four heatmap channels w.r.t its direction. Both qualitative and quantitative evaluations demonstrate that our proposed method can better reconstruct fine-grained structures, such as adjacent corners and tiny edges. Consequently, it outperforms the state-of-the-art model by +1.9\%@F-1 on Corner and +3.0\%@F-1 on Edge.
A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model
Apr 18, 2023



Recently, the instruction-tuning of large language models is a crucial area of research in the field of natural language processing. Due to resource and cost limitations, several researchers have employed parameter-efficient tuning techniques, such as LoRA, for instruction tuning, and have obtained encouraging results In comparison to full-parameter fine-tuning, LoRA-based tuning demonstrates salient benefits in terms of training costs. In this study, we undertook experimental comparisons between full-parameter fine-tuning and LoRA-based tuning methods, utilizing LLaMA as the base model. The experimental results show that the selection of the foundational model, training dataset scale, learnable parameter quantity, and model training cost are all important factors. We hope that the experimental conclusions of this paper can provide inspiration for training large language models, especially in the field of Chinese, and help researchers find a better trade-off strategy between training cost and model performance. To facilitate the reproduction of the paper's results, the dataset, model and code will be released.
Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation
Apr 16, 2023Recently, significant public efforts have been directed towards developing low-cost models with capabilities akin to ChatGPT, thereby fostering the growth of open-source conversational models. However, there remains a scarcity of comprehensive and in-depth evaluations of these models' performance. In this study, we examine the influence of training data factors, including quantity, quality, and linguistic distribution, on model performance. Our analysis is grounded in several publicly accessible, high-quality instruction datasets, as well as our own Chinese multi-turn conversations. We assess various models using a evaluation set of 1,000 samples, encompassing nine real-world scenarios. Our goal is to supplement manual evaluations with quantitative analyses, offering valuable insights for the continued advancement of open-source chat models. Furthermore, to enhance the performance and training and inference efficiency of models in the Chinese domain, we extend the vocabulary of LLaMA - the model with the closest open-source performance to proprietary language models like GPT-3 - and conduct secondary pre-training on 3.4B Chinese words. We make our model, data, as well as code publicly available.
Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases
Mar 26, 2023



The success of ChatGPT has recently attracted numerous efforts to replicate it, with instruction-tuning strategies being a key factor in achieving remarkable results. Instruction-tuning not only significantly enhances the model's performance and generalization but also makes the model's generated results more consistent with human speech patterns. However current research rarely studies the impact of different amounts of instruction data on model performance, especially in the real-world use cases. In this paper we explore the performance of large language models based on instruction tuning across different scales of instruction data. An evaluation dataset consisting of 12 major online use cases is constructed in the experiment. With Bloomz-7B1-mt as the base model, the results show that 1) merely increasing the amount of instruction data leads to continuous improvement in tasks such as open-ended generation, 2) in tasks such as math and code, the model performance curve remains quite flat while increasing data size. We further analyze the possible causes of these phenomena and propose potential future research directions such as effectively selecting high-quality training data, scaling base models and training methods specialized for hard tasks. We will release our training and evaluation datasets, as well as model checkpoints.
Exploring ChatGPT's Ability to Rank Content: A Preliminary Study on Consistency with Human Preferences
Mar 14, 2023



As a natural language assistant, ChatGPT is capable of performing various tasks, including but not limited to article generation, code completion, and data analysis. Furthermore, ChatGPT has consistently demonstrated a remarkable level of accuracy and reliability in terms of content evaluation, exhibiting the capability of mimicking human preferences. To further explore ChatGPT's potential in this regard, a study is conducted to assess its ability to rank content. In order to do so, a test set consisting of prompts is created, covering a wide range of use cases, and five models are utilized to generate corresponding responses. ChatGPT is then instructed to rank the responses generated by these models. The results on the test set show that ChatGPT's ranking preferences are consistent with human to a certain extent. This preliminary experimental finding implies that ChatGPT's zero-shot ranking capability could be used to reduce annotation pressure in a number of ranking tasks.
Semi-Supervised 2D Human Pose Estimation Driven by Position Inconsistency Pseudo Label Correction Module
Mar 08, 2023



In this paper, we delve into semi-supervised 2D human pose estimation. The previous method ignored two problems: (i) When conducting interactive training between large model and lightweight model, the pseudo label of lightweight model will be used to guide large models. (ii) The negative impact of noise pseudo labels on training. Moreover, the labels used for 2D human pose estimation are relatively complex: keypoint category and keypoint position. To solve the problems mentioned above, we propose a semi-supervised 2D human pose estimation framework driven by a position inconsistency pseudo label correction module (SSPCM). We introduce an additional auxiliary teacher and use the pseudo labels generated by the two teacher model in different periods to calculate the inconsistency score and remove outliers. Then, the two teacher models are updated through interactive training, and the student model is updated using the pseudo labels generated by two teachers. To further improve the performance of the student model, we use the semi-supervised Cut-Occlude based on pseudo keypoint perception to generate more hard and effective samples. In addition, we also proposed a new indoor overhead fisheye human keypoint dataset WEPDTOF-Pose. Extensive experiments demonstrate that our method outperforms the previous best semi-supervised 2D human pose estimation method. We will release the code and dataset at https://github.com/hlz0606/SSPCM.
BEIKE NLP at SemEval-2022 Task 4: Prompt-Based Paragraph Classification for Patronizing and Condescending Language Detection
Aug 02, 2022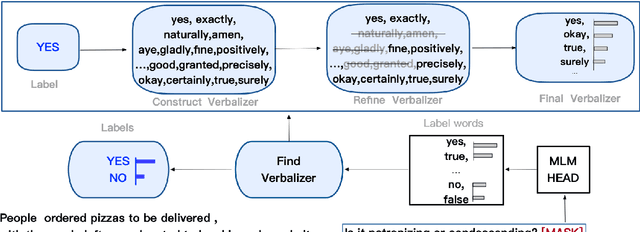
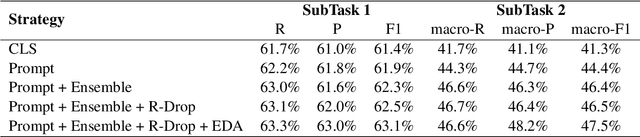
PCL detection task is aimed at identifying and categorizing language that is patronizing or condescending towards vulnerable communities in the general media.Compared to other NLP tasks of paragraph classification, the negative language presented in the PCL detection task is usually more implicit and subtle to be recognized, making the performance of common text-classification approaches disappointed. Targeting the PCL detection problem in SemEval-2022 Task 4, in this paper, we give an introduction to our team's solution, which exploits the power of prompt-based learning on paragraph classification. We reformulate the task as an appropriate cloze prompt and use pre-trained Masked Language Models to fill the cloze slot. For the two subtasks, binary classification and multi-label classification, DeBERTa model is adopted and fine-tuned to predict masked label words of task-specific prompts. On the evaluation dataset, for binary classification, our approach achieves an F1-score of 0.6406; for multi-label classification, our approach achieves an macro-F1-score of 0.4689 and ranks first in the leaderboard.
To Answer or Not to Answer? Improving Machine Reading Comprehension Model with Span-based Contrastive Learning
Aug 02, 2022

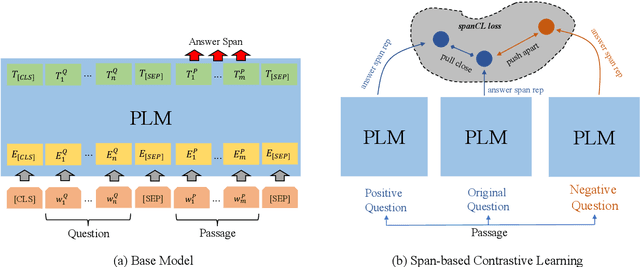
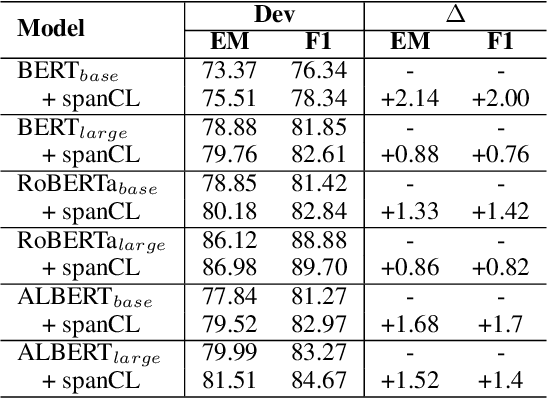
Machine Reading Comprehension with Unanswerable Questions is a difficult NLP task, challenged by the questions which can not be answered from passages. It is observed that subtle literal changes often make an answerable question unanswerable, however, most MRC models fail to recognize such changes. To address this problem, in this paper, we propose a span-based method of Contrastive Learning (spanCL) which explicitly contrast answerable questions with their answerable and unanswerable counterparts at the answer span level. With spanCL, MRC models are forced to perceive crucial semantic changes from slight literal differences. Experiments on SQuAD 2.0 dataset show that spanCL can improve baselines significantly, yielding 0.86-2.14 absolute EM improvements. Additional experiments also show that spanCL is an effective way to utilize generated questions.
Audio-Visual Wake Word Spotting System For MISP Challenge 2021
Apr 20, 2022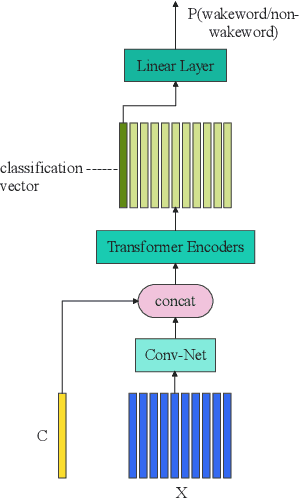
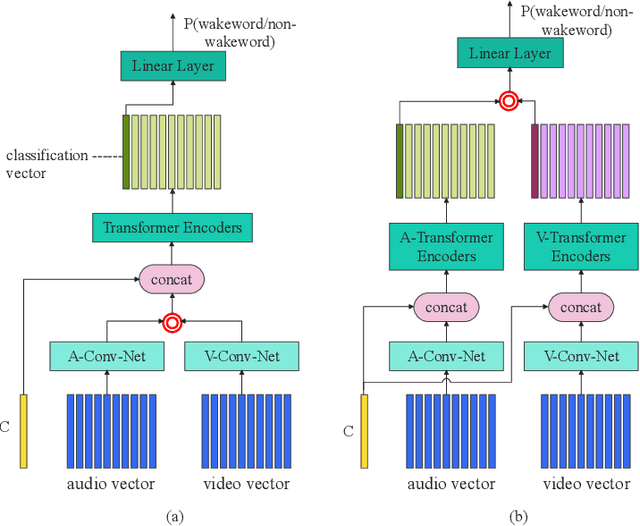

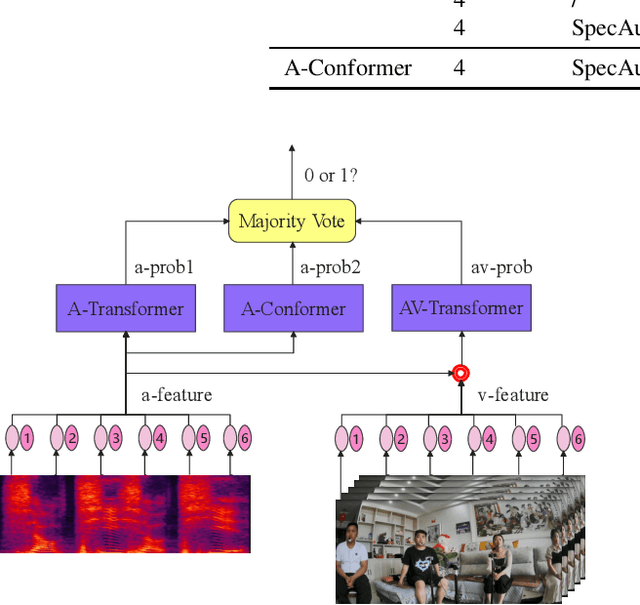
This paper presents the details of our system designed for the Task 1 of Multimodal Information Based Speech Processing (MISP) Challenge 2021. The purpose of Task 1 is to leverage both audio and video information to improve the environmental robustness of far-field wake word spotting. In the proposed system, firstly, we take advantage of speech enhancement algorithms such as beamforming and weighted prediction error (WPE) to address the multi-microphone conversational audio. Secondly, several data augmentation techniques are applied to simulate a more realistic far-field scenario. For the video information, the provided region of interest (ROI) is used to obtain visual representation. Then the multi-layer CNN is proposed to learn audio and visual representations, and these representations are fed into our two-branch attention-based network which can be employed for fusion, such as transformer and conformed. The focal loss is used to fine-tune the model and improve the performance significantly. Finally, multiple trained models are integrated by casting vote to achieve our final 0.091 score.
Time Domain Adversarial Voice Conversion for ADD 2022
Apr 20, 2022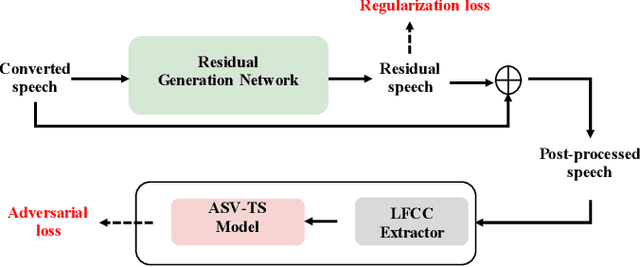

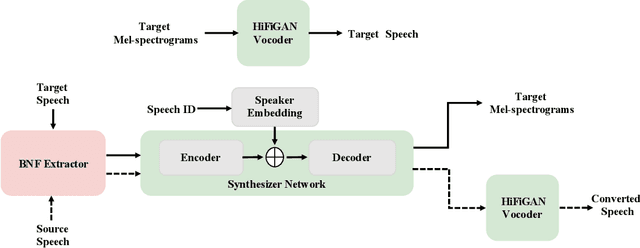
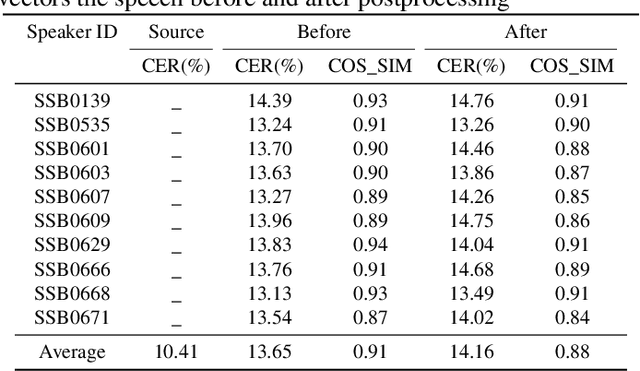
In this paper, we describe our speech generation system for the first Audio Deep Synthesis Detection Challenge (ADD 2022). Firstly, we build an any-to-many voice conversion (VC) system to convert source speech with arbitrary language content into the target speaker%u2019s fake speech. Then the converted speech generated from VC is post-processed in the time domain to improve the deception ability. The experimental results show that our system has adversarial ability against anti-spoofing detectors with a little compromise in audio quality and speaker similarity. This system ranks top in Track 3.1 in the ADD 2022, showing that our method could also gain good generalization ability against different detectors.