 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRLE: Decentralized Reinforcement Learning at the Edge for Traffic Light Control
Sep 03, 2020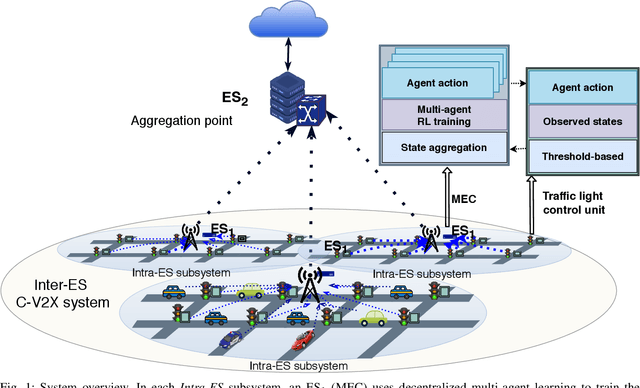
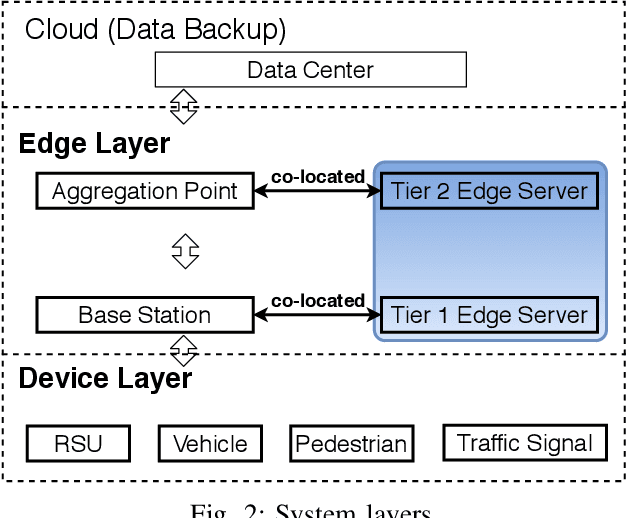
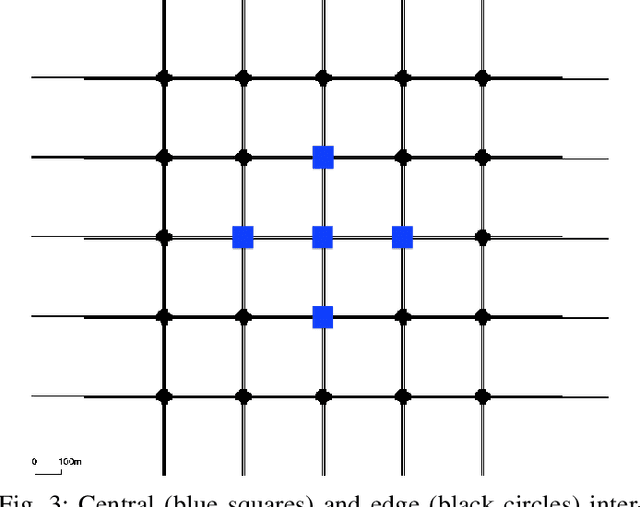
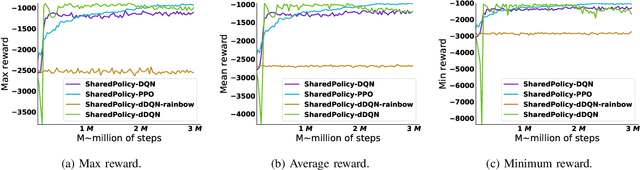
The Internet of Vehicles (IoV) enables real-time data exchange among vehicles and roadside units and thus provides a promising solution to alleviate traffic jams in the urban area. Meanwhile, better traffic management via efficient traffic light control can benefit the IoV as well by enabling a better communication environment and decreasing the network load. As such, IoV and efficient traffic light control can formulate a virtuous cycle. Edge computing, an emerging technology to provide low-latency computation capabilities at the edge of the network, can further improve the performance of this cycle. However, while the collected information is valuable, an efficient solution for better utilization and faster feedback has yet to be developed for edge-empowered IoV. To this end, we propose a Decentralized Reinforcement Learning at the Edge for traffic light control in the IoV (DRLE). DRLE exploits the ubiquity of the IoV to accelerate the collection of traffic data and its interpretation towards alleviating congestion and providing better traffic light control. DRLE operates within the coverage of the edge servers and uses aggregated data from neighboring edge servers to provide city-scale traffic light control. DRLE decomposes the highly complex problem of large area control. into a decentralized multi-agent problem. We prove its global optima with concrete mathematical reasoning. The proposed decentralized reinforcement learning algorithm running at each edge node adapts the traffic lights in real time. We conduct extensive evaluations and demonstrate the superiority of this approach over several state-of-the-art algorithms.
Information Freshness-Aware Task Offloading in Air-Ground Integrated Edge Computing Systems
Jul 15, 2020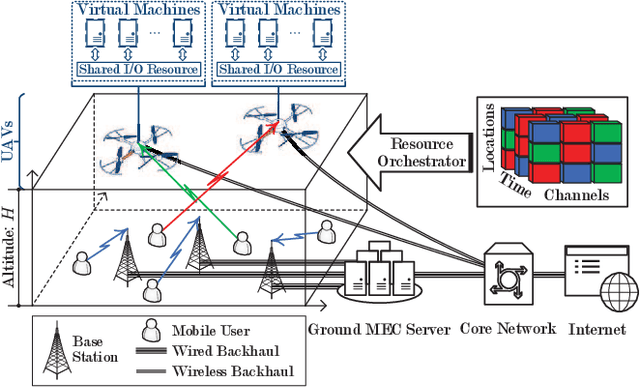
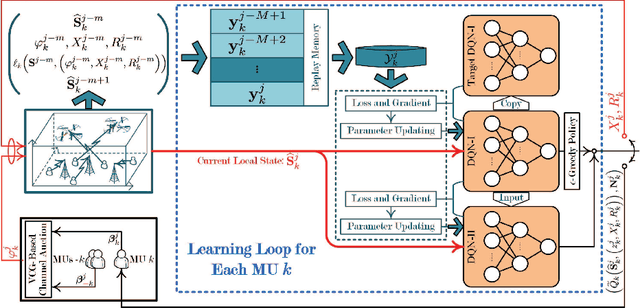


This paper studies the problem of information freshness-aware task offloading in an air-ground integrated multi-access edge computing system, which is deployed by an infrastructure provider (InP). A third-party real-time application service provider provides computing services to the subscribed mobile users (MUs) with the limited communication and computation resources from the InP based on a long-term business agreement. Due to the dynamic characteristics, the interactions among the MUs are modelled by a non-cooperative stochastic game, in which the control policies are coupled and each MU aims to selfishly maximize its own expected long-term payoff. To address the Nash equilibrium solutions, we propose that each MU behaves in accordance with the local system states and conjectures, based on which the stochastic game is transformed into a single-agent Markov decision process. Moreover, we derive a novel online deep reinforcement learning (RL) scheme that adopts two separate double deep Q-networks for each MU to approximate the Q-factor and the post-decision Q-factor. Using the proposed deep RL scheme, each MU in the system is able to make decisions without a priori statistical knowledge of dynamics. Numerical experiments examine the potentials of the proposed scheme in balancing the age of information and the energy consumption.
Computation Offloading in Beyond 5G Networks: A Distributed Learning Framework and Applications
Jul 15, 2020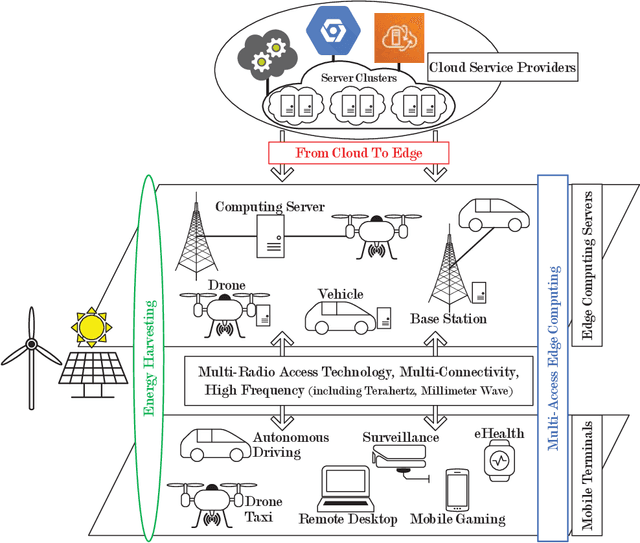
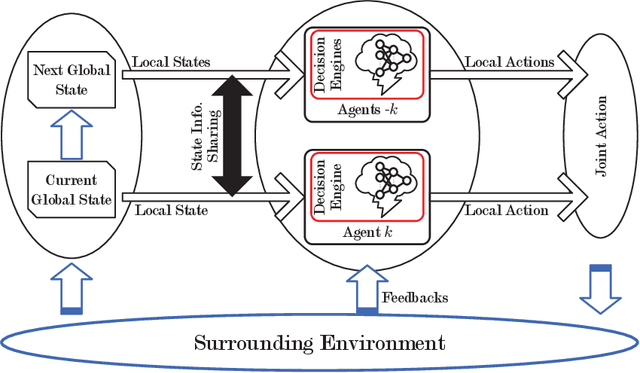
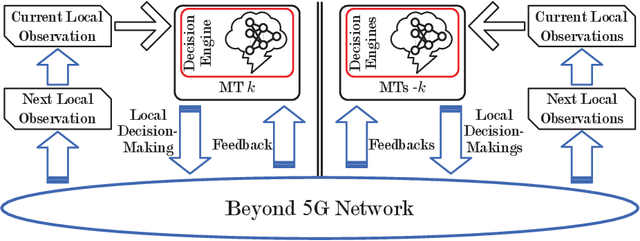
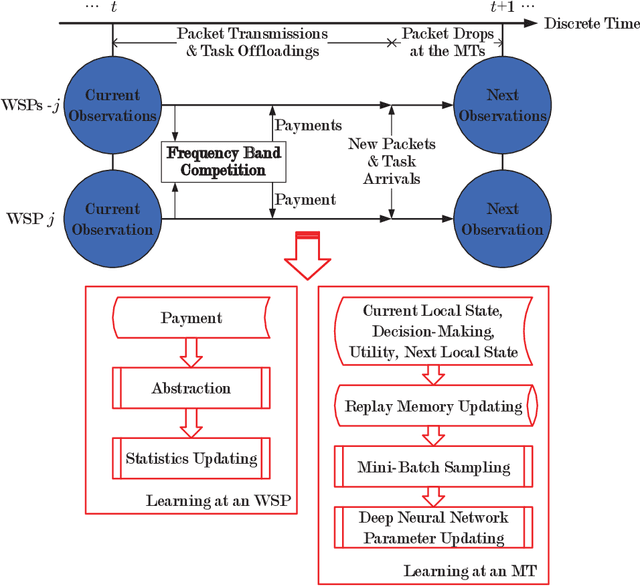
Facing the trend of merging wireless communications and multi-access edge computing (MEC), this article studies computation offloading in the beyond fifth-generation networks. To address the technical challenges originating from the uncertainties and the sharing of limited resource in an MEC system, we formulate the computation offloading problem as a multi-agent Markov decision process, for which a distributed learning framework is proposed. We present a case study on resource orchestration in computation offloading to showcase the potentials of an online distributed reinforcement learning algorithm developed under the proposed framework. Experimental results demonstrate that our learning algorithm outperforms the benchmark resource orchestration algorithms. Furthermore, we outline the research directions worth in-depth investigation to minimize the time cost, which is one of the main practical issues that prevent the implementation of the proposed distributed learning framework.
Age of Information-Aware Radio Resource Management in Vehicular Networks: A Proactive Deep Reinforcement Learning Perspective
Aug 06, 2019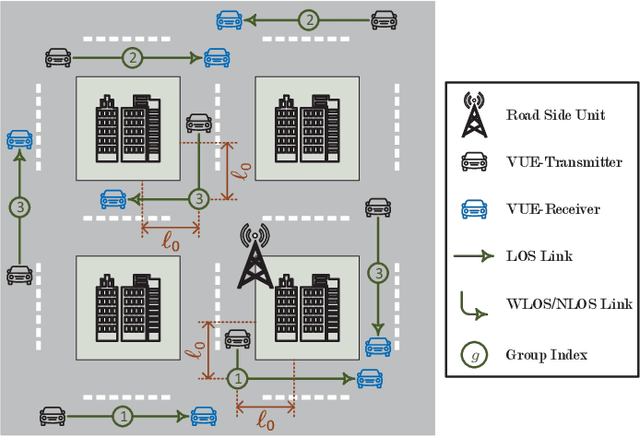
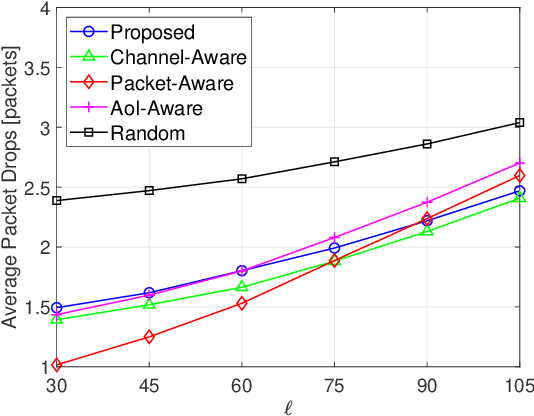
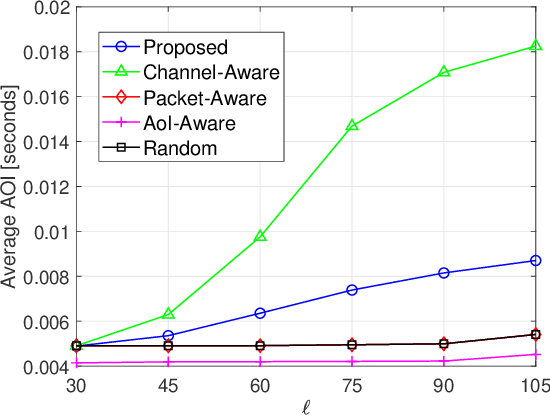
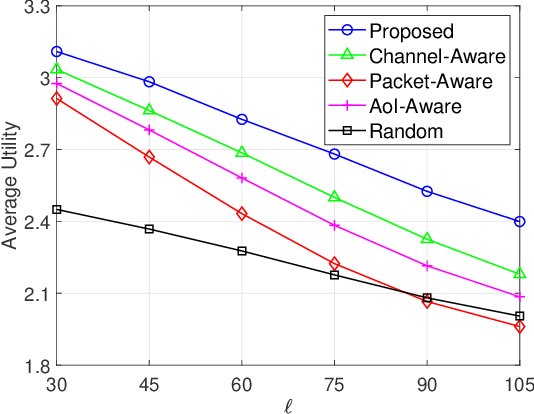
In this paper, we investigate the problem of age of information (AoI)-aware radio resource management for expected long-term performance optimization in a Manhattan grid vehicle-to-vehicle network. With the observation of global network state at each scheduling slot, the roadside unit (RSU) allocates the frequency bands and schedules packet transmissions for all vehicle user equipment-pairs (VUE-pairs). We model the stochastic decision-making procedure as a discrete-time single-agent Markov decision process (MDP). The technical challenges in solving the optimal control policy originate from high spatial mobility and temporally varying traffic information arrivals of the VUE-pairs. To make the problem solving tractable, we first decompose the original MDP into a series of per-VUE-pair MDPs. Then we propose a proactive algorithm based on long short-term memory and deep reinforcement learning techniques to address the partial observability and the curse of high dimensionality in local network state space faced by each VUE-pair. With the proposed algorithm, the RSU makes the optimal frequency band allocation and packet scheduling decision at each scheduling slot in a decentralized way in accordance with the partial observations of the global network state at the VUE-pairs. Numerical experiments validate the theoretical analysis and demonstrate the significant performance improvements from the proposed algorithm.
Decentralized Deep Reinforcement Learning for Delay-Power Tradeoff in Vehicular Communications
Jun 03, 2019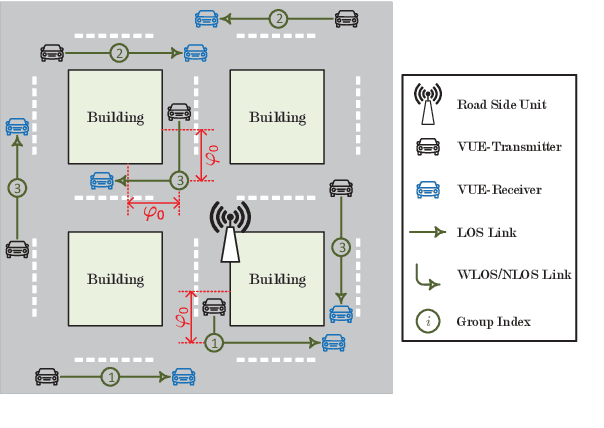
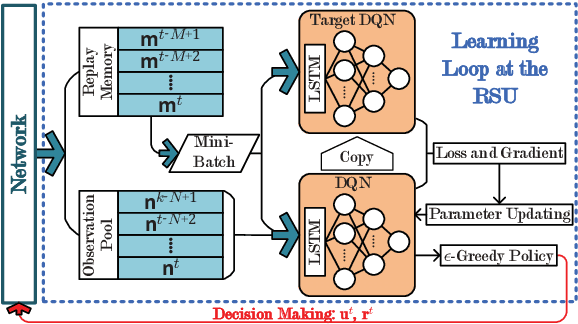
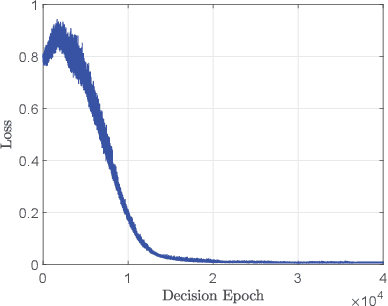
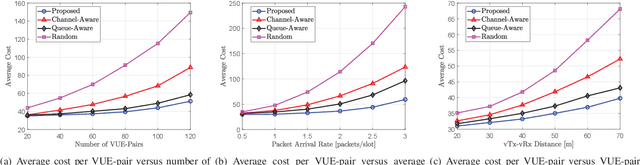
This paper targets at the problem of radio resource management for expected long-term delay-power tradeoff in vehicular communications. At each decision epoch, the road side unit observes the global network state, allocates channels and schedules data packets for all vehicle user equipment-pairs (VUE-pairs). The decision-making procedure is modelled as a discrete-time Markov decision process (MDP). The technical challenges in solving an optimal control policy originate from highly spatial mobility of vehicles and temporal variations in data traffic. To simplify the decision-making process, we first decompose the MDP into a series of per-VUE-pair MDPs. We then propose an online long short-term memory based deep reinforcement learning algorithm to break the curse of high dimensionality in state space faced by each per-VUE-pair MDP. With the proposed algorithm, the optimal channel allocation and packet scheduling decision at each epoch can be made in a decentralized way in accordance with the partial observations of the global network state at the VUE-pairs. Numerical simulations validate the theoretical analysis and show the effectiveness of the proposed online learning algorithm.
GAN-based Deep Distributional Reinforcement Learning for Resource Management in Network Slicing
May 10, 2019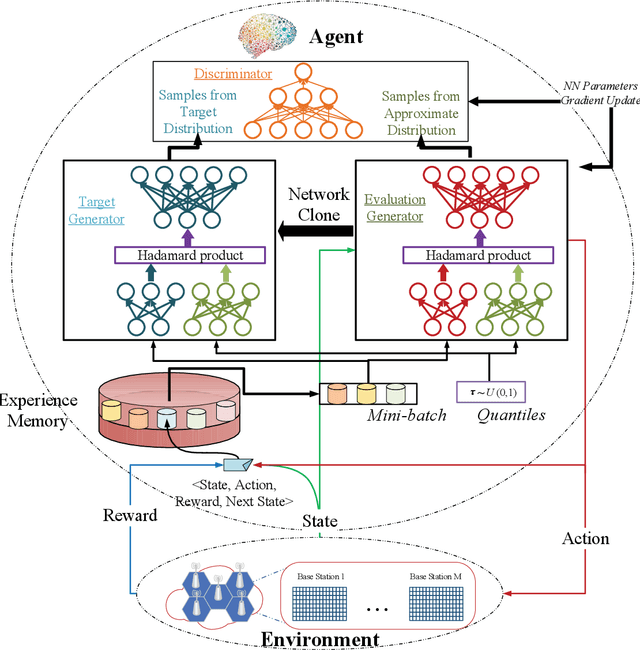
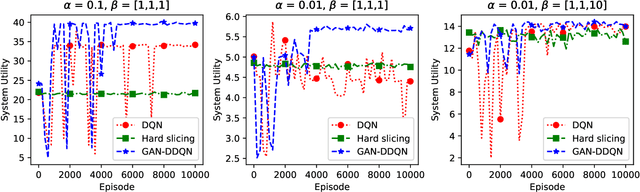
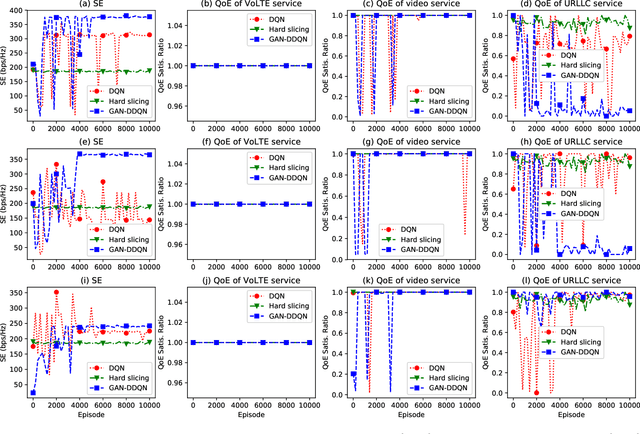
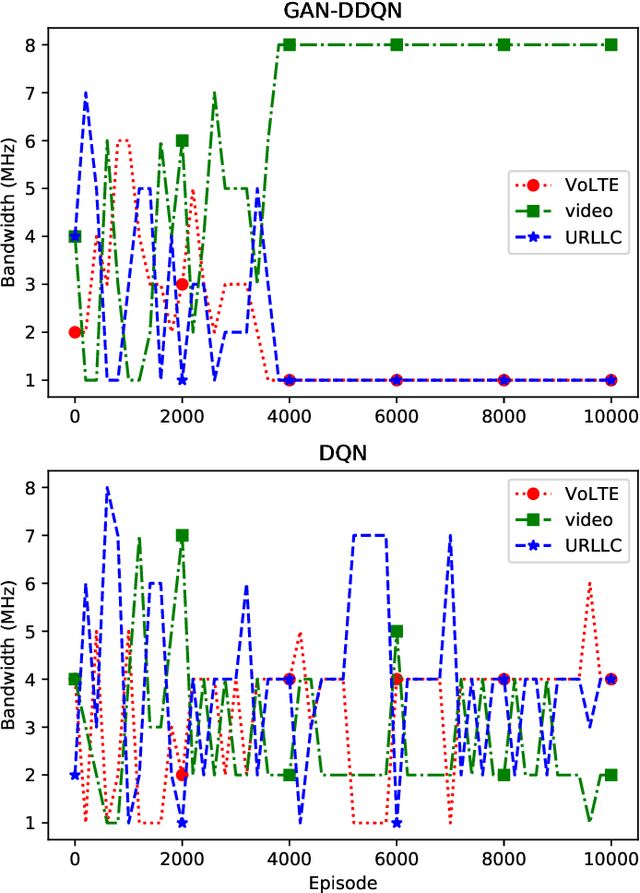
Network slicing is a key technology in 5G communications system, which aims to dynamically and efficiently allocate resources for diversified services with distinct requirements over a common underlying physical infrastructure. Therein, demand-aware allocation is of significant importance to network slicing. In this paper, we consider a scenario that contains several slices in one base station on sharing the same bandwidth. Deep reinforcement learning (DRL) is leveraged to solve this problem by regarding the varying demands and the allocated bandwidth as the environment \emph{state} and \emph{action}, respectively. In order to obtain better quality of experience (QoE) satisfaction ratio and spectrum efficiency (SE), we propose generative adversarial network (GAN) based deep distributional Q network (GAN-DDQN) to learn the distribution of state-action values. Furthermore, we estimate the distributions by approximating a full quantile function, which can make the training error more controllable. In order to protect the stability of GAN-DDQN's training process from the widely-spanning utility values, we also put forward a reward-clipping mechanism. Finally, we verify the performance of the proposed GAN-DDQN algorithm through extensive simulations.
Deep Learning with Long Short-Term Memory for Time Series Prediction
Oct 24, 2018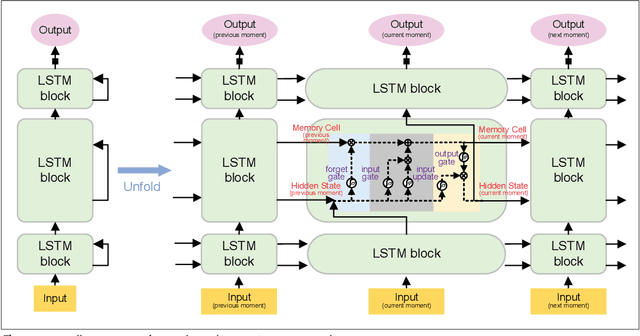
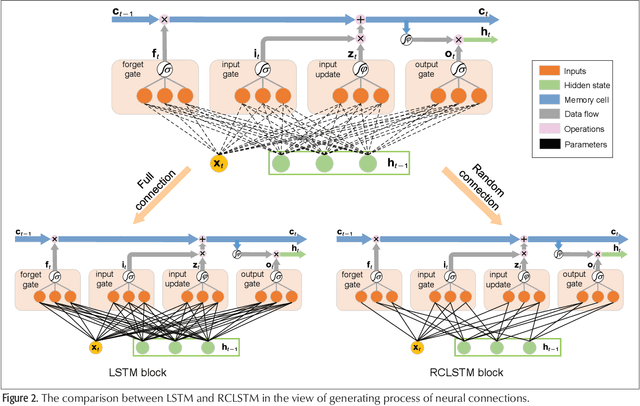
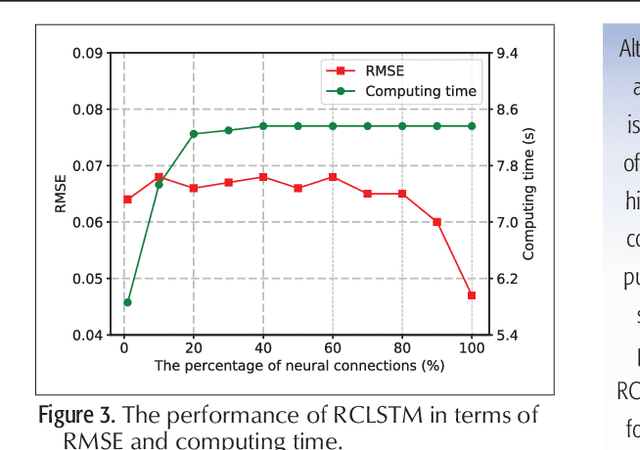
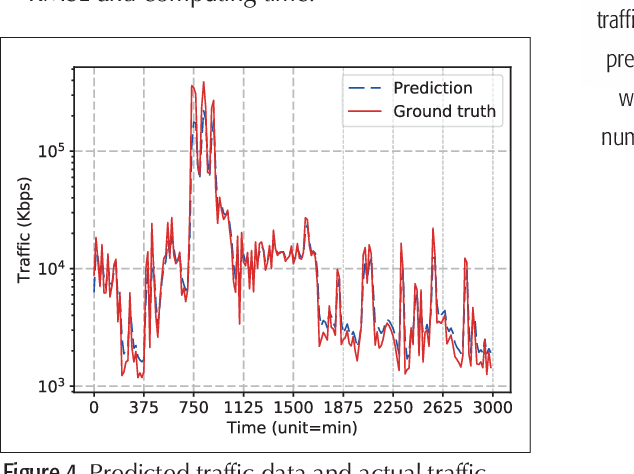
Time series prediction can be generalized as a process that extracts useful information from historical records and then determines future values. Learning long-range dependencies that are embedded in time series is often an obstacle for most algorithms, whereas Long Short-Term Memory (LSTM) solutions, as a specific kind of scheme in deep learning, promise to effectively overcome the problem. In this article, we first give a brief introduction to the structure and forward propagation mechanism of the LSTM model. Then, aiming at reducing the considerable computing cost of LSTM, we put forward the Random Connectivity LSTM (RCLSTM) model and test it by predicting traffic and user mobility in telecommunication networks. Compared to LSTM, RCLSTM is formed via stochastic connectivity between neurons, which achieves a significant breakthrough in the architecture formation of neural networks. In this way, the RCLSTM model exhibits a certain level of sparsity, which leads to an appealing decrease in the computational complexity and makes the RCLSTM model become more applicable in latency-stringent application scenarios. In the field of telecommunication networks, the prediction of traffic series and mobility traces could directly benefit from this improvement as we further demonstrate that the prediction accuracy of RCLSTM is comparable to that of the conventional LSTM no matter how we change the number of training samples or the length of input sequences.
Deep Reinforcement Learning for Network Slicing
May 26, 2018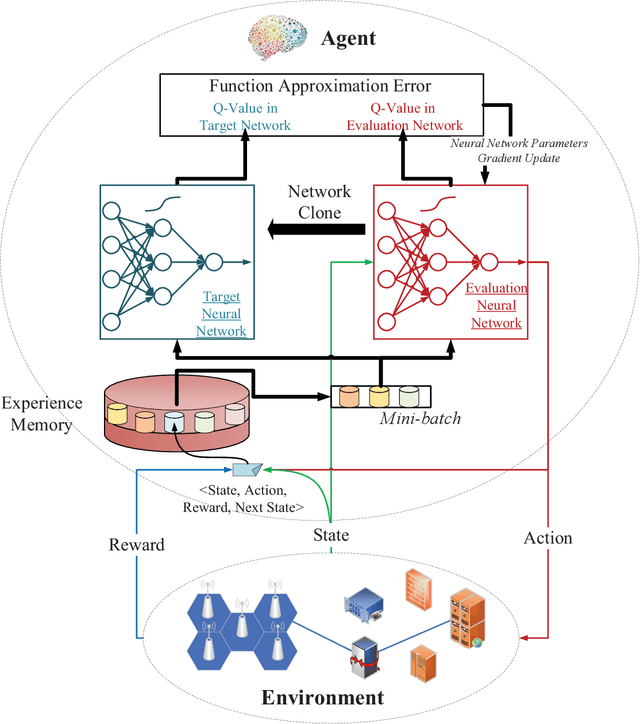
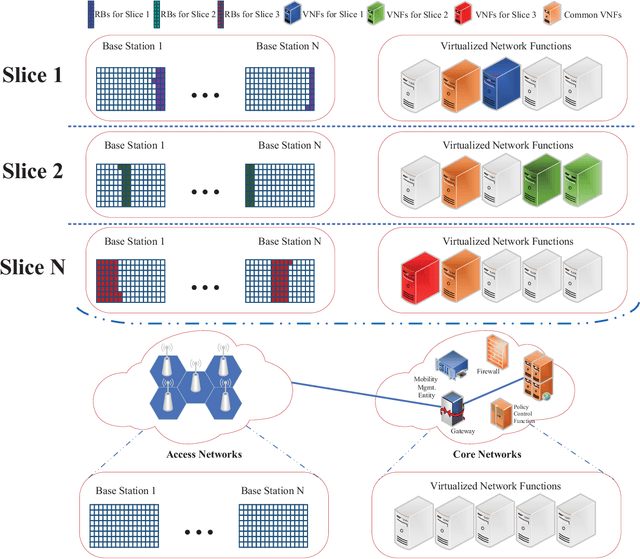
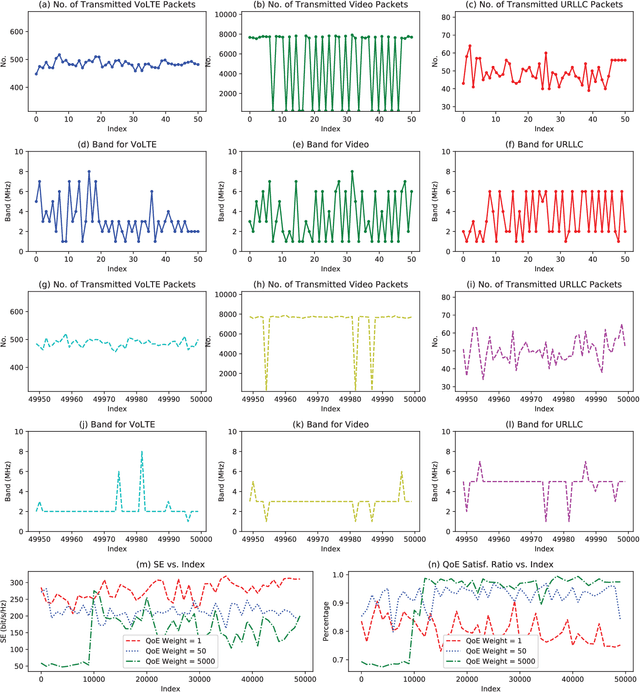
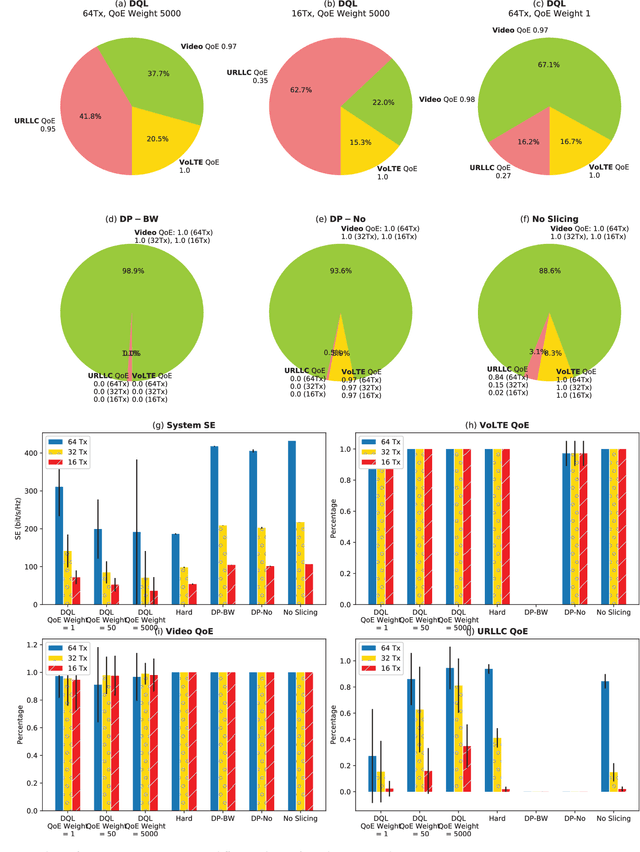
Network slicing means an emerging business to operators and allows them to sell the customized slices to various tenants at different prices. In order to provide better-performing and costefficient services, network slicing involves challenging technical issues and urgently looks forward to intelligent innovations to make the resource management consistent with users' activities per slice. In that regard, deep reinforcement learning (DRL), which focuses on how to interact with the environment by trying alternative actions and reinforces the tendency actions producing more rewarding consequences, is emerging as a promising solution. In this paper, after briefly reviewing the fundamental concepts and evolution-driving factors of DRL, we investigate the application of DRL in some typical resource management scenarios of network slicing, which include radio resource slicing and priority-based core network slicing, and demonstrate the performance advantage of DRL over several competing schemes through extensive simulations. Finally, we also discuss the possible challenges to apply DRL in network slicing from a general perspective.
Optimized Computation Offloading Performance in Virtual Edge Computing Systems via Deep Reinforcement Learning
May 16, 2018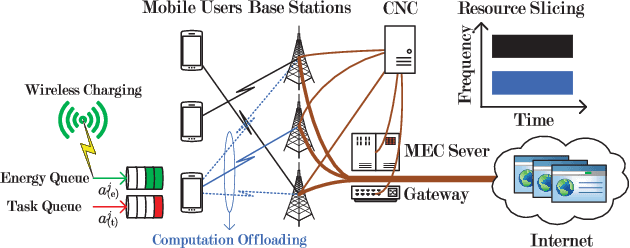
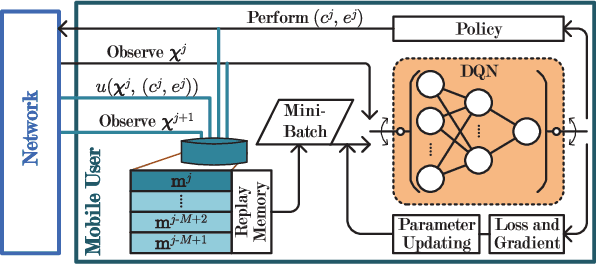
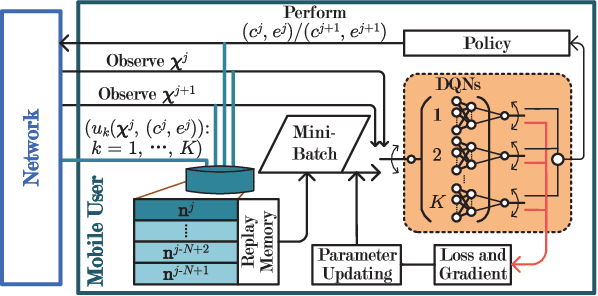
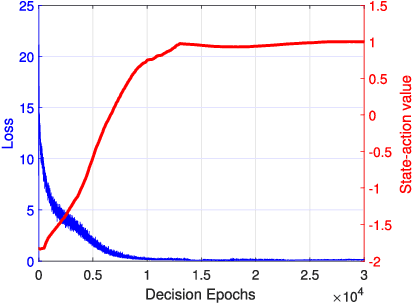
To improve the quality of computation experience for mobile devices, mobile-edge computing (MEC) is a promising paradigm by providing computing capabilities in close proximity within a sliced radio access network (RAN), which supports both traditional communication and MEC services. Nevertheless, the design of computation offloading policies for a virtual MEC system remains challenging. Specifically, whether to execute a computation task at the mobile device or to offload it for MEC server execution should adapt to the time-varying network dynamics. In this paper, we consider MEC for a representative mobile user in an ultra-dense sliced RAN, where multiple base stations (BSs) are available to be selected for computation offloading. The problem of solving an optimal computation offloading policy is modelled as a Markov decision process, where our objective is to maximize the long-term utility performance whereby an offloading decision is made based on the task queue state, the energy queue state as well as the channel qualities between MU and BSs. To break the curse of high dimensionality in state space, we first propose a double deep Q-network (DQN) based strategic computation offloading algorithm to learn the optimal policy without knowing a priori knowledge of network dynamics. Then motivated by the additive structure of the utility function, a Q-function decomposition technique is combined with the double DQN, which leads to novel learning algorithm for the solving of stochastic computation offloading. Numerical experiments show that our proposed learning algorithms achieve a significant improvement in computation offloading performance compared with the baseline policies.
Traffic Prediction Based on Random Connectivity in Deep Learning with Long Short-Term Memory
Apr 03, 2018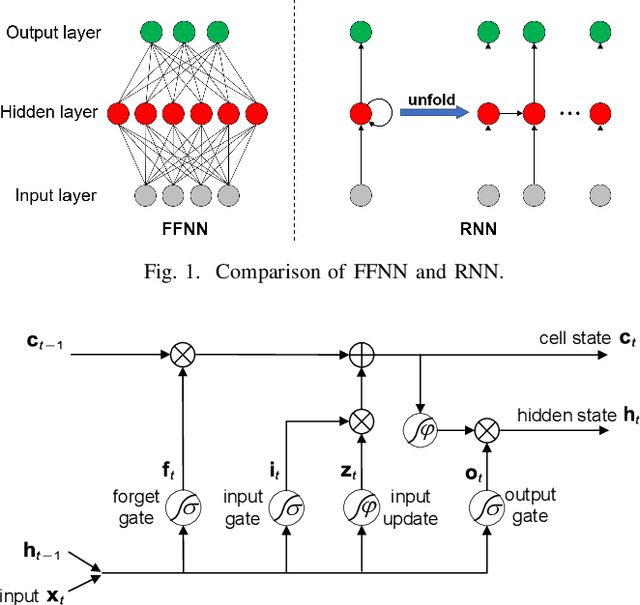
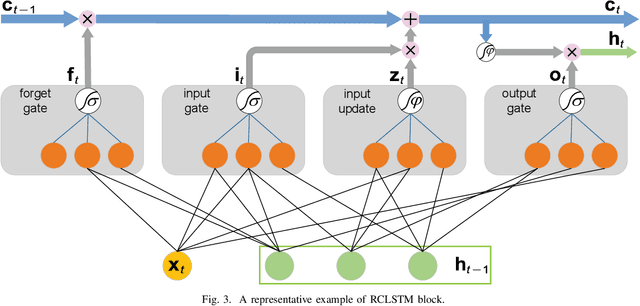
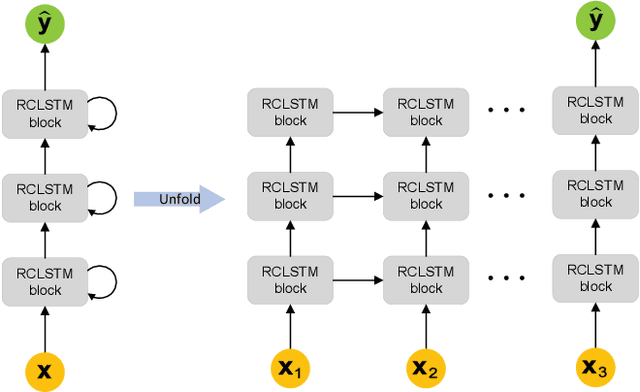
Traffic prediction plays an important role in evaluating the performance of telecommunication networks and attracts intense research interests. A significant number of algorithms and models have been put forward to analyse traffic data and make prediction. In the recent big data era, deep learning has been exploited to mine the profound information hidden in the data. In particular, Long Short-Term Memory (LSTM), one kind of Recurrent Neural Network (RNN) schemes, has attracted a lot of attentions due to its capability of processing the long-range dependency embedded in the sequential traffic data. However, LSTM has considerable computational cost, which can not be tolerated in tasks with stringent latency requirement. In this paper, we propose a deep learning model based on LSTM, called Random Connectivity LSTM (RCLSTM). Compared to the conventional LSTM, RCLSTM makes a notable breakthrough in the formation of neural network, which is that the neurons are connected in a stochastic manner rather than full connected. So, the RCLSTM, with certain intrinsic sparsity, have many neural connections absent (distinguished from the full connectivity) and which leads to the reduction of the parameters to be trained and the computational cost. We apply the RCLSTM to predict traffic and validate that the RCLSTM with even 35% neural connectivity still shows a satisfactory performance. When we gradually add training samples, the performance of RCLSTM becomes increasingly closer to the baseline LSTM. Moreover, for the input traffic sequences of enough length, the RCLSTM exhibits even superior prediction accuracy than the baseline LSTM.